

Deep neural networks (DNNs) are opening up new and exciting opportunities for commercial AI applications. Here’s the thing. They demand massive amounts of resources in terms of operating costs and compute power. In addition, with more and more AI moving to edge devices, we need a way to make DNNs lighter and more efficient, while still keeping them accurate and robust. One answer lies in taking advantage of inference acceleration techniques like graph compilers and quantization. Deci’s answer lies in redesigning the neural architectures while simultaneously taking advantage of compilation and quantization. This blog explains how Deci’s Automated Neural Architecture Construction (AutoNAC) is being used to create proprietary DeciNet architectures that extend the efficient frontiers of latency/accuracy tradeoffs on NVIDIA cloud and edge GPUs.
Deep Neural Networks – The Blessing and The Curse
The beauty of DNN models is their ability to learn on their own, producing effective representations and predictive features from raw data—without human intervention. Although some classical ML algorithms such as gradient boosting trees are also capable of learning basic predictive features, DNNs are far superior in this respect. Stochastic Gradient Descent (SGD) optimization algorithms train DNNs in a piecemeal fashion, which allows them to be trained with virtually unlimited amounts of data. This blessing is unmatched by classical machine learning algorithms such as support vector machines and gradient boosting trees, like XGBoost. For example, XGBoost needs to store almost the entire training data in memory during training, making it impractical for large training sets. Figure 1 illustrates how classical ML algorithms can often achieve better performance in small-data regimes, whereas DL models keep improving with increasing dataset size.
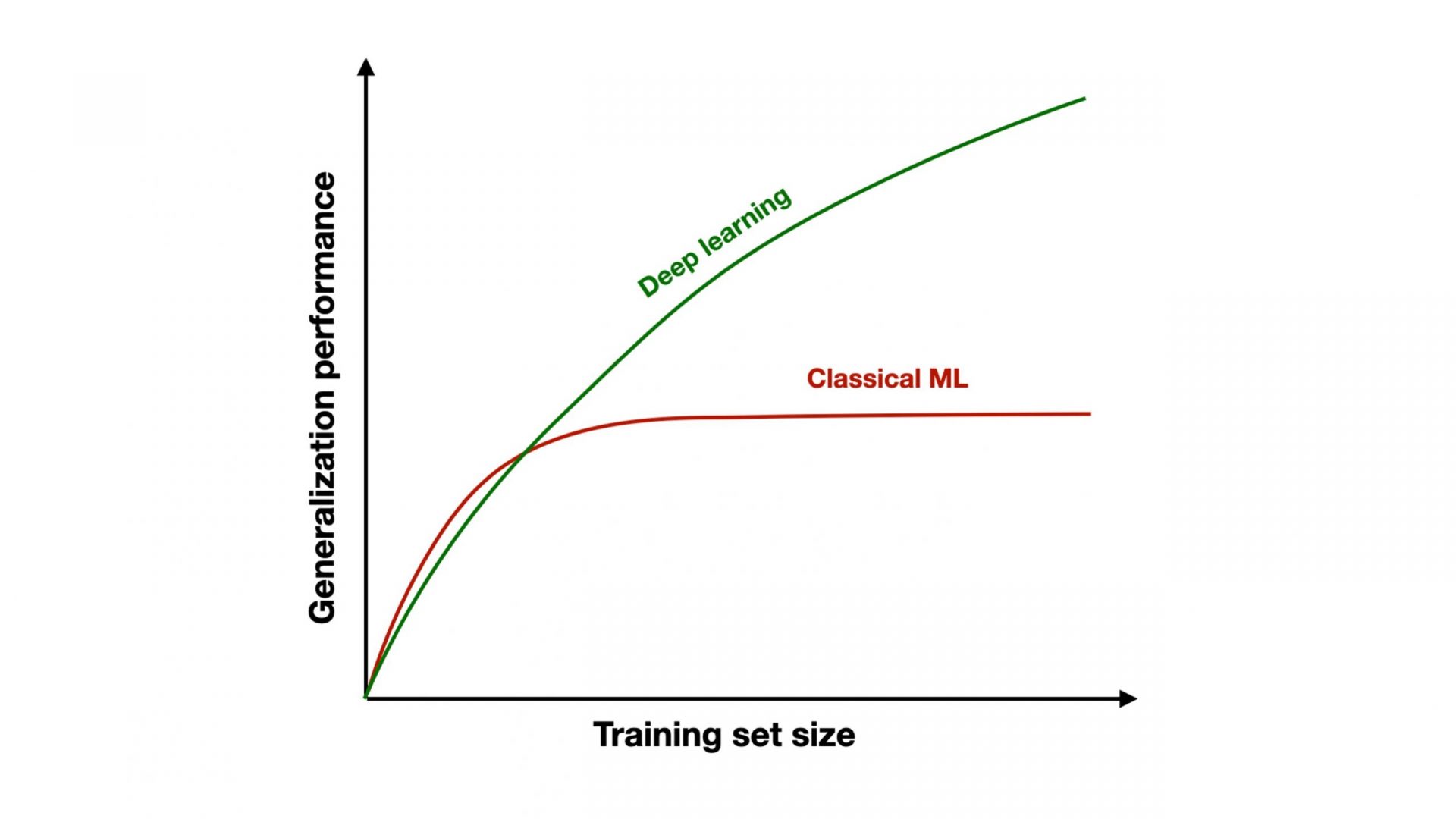
Figure 1. DL performance vs. classical ML when it comes to training dataset. As data size increases, DL models improve while ML algorithms plateau.
We know that excessively large DNNs are easier to train for better accuracy than smaller ones. But this superior accuracy also depends on using much more data. What about the training and inference costs of these excessively large deep neural networks?
Recently, we’ve seen examples of massive training sets that are used to train huge neural models. One striking example is Open AI’s GPT-3 language model, which was trained with SGD on 45 TB of text from the Internet. This year, Google announced the Switch Transformer, a model that is six times larger, with a trillion trainable parameters. With the cost of training the GPT-3 estimated at around $12M, we can see that these enormous models are an expensive endeavor reserved for the very few that have this scale of resources.
Clearly, the costs of operating DNNs at scale on the cloud can be hefty. Can these computations be effectively supported by current and future AI chips? It really boils down to two factors: the availability of very fast and affordable AI chips and superior neural architecture designs that can incorporate algorithmic acceleration techniques like compilation and quantization. We need new methods that can shrink down large neural networks in terms of size, latency, or energy parameters, while preserving high-accuracy performance. This is where neural architecture search (NAS) comes into play.
Hardware Awareness and Acceleration Techniques
So how do we improve throughput and reduce latency, power consumption, or memory footprint—all while keeping accuracy high? This is especially challenging because there are huge variations in the relative efficiency of neural architectures when their performance is measured on different hardware platforms, depending on whether we are looking at latency or energy consumption. In fact, we’ve seen a number of real-life cases where the runtime metrics of two architectures diverge between two devices in the same family. The figure below compares the inference runtime (ms) of ResNet-50 and EfficientNet-B0 on two types of GPUs. EfficientNet-B0 is clearly superior to ResNet-50 when run on the K80 GPU; however, on the V100 GPU, ResNet shows up as slightly faster.
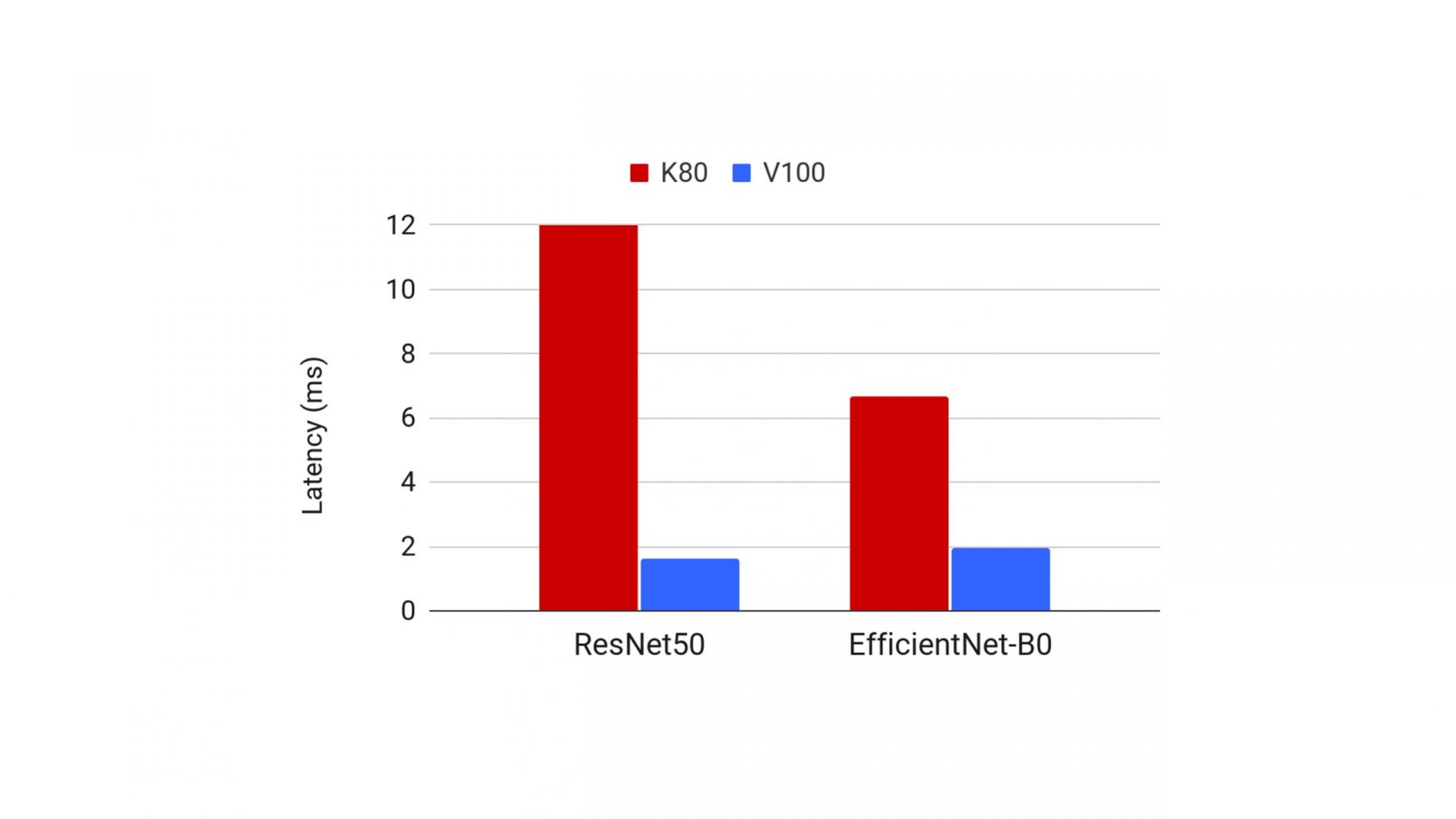
Figure 2. Latencies of ResNet-50 and EfficientNet-B0 on K80 and V100 GPUs. Source: Deci AI
What are the factors that affect the runtime, or other performance metrics, of a given architecture on a specific type of hardware? One obvious factor is the architecture as a whole, with its inner structure and level of depth, as well as the hardware properties of the chip. We tend to look at the degree of parallelism, often measured by the number of basic computing cores, and the effectiveness (size, speed) of the cache memory system.
Other critical factors can also have a direct impact on the run-time performance. These include the drivers and graph compilers, which implement the actual neural network computation on the hardware, as well as various algorithmic techniques, such as weight pruning to reduce the memory footprint and quantization to cut down numerical precision (or ‘bitwidth’) of neural weights and activations, which directly translates on supporting hardware to runtime acceleration.
Quantization allows for significantly smaller networks and more efficient computation, both in terms of tensor arithmetic operations and memory access. That said, different architectures tend to be more or less accommodating when it comes to quantization. By considering an architecture that is more ‘quantization-friendly’, for example, able to support mixed precision and different bitwidth operations, we can potentially boost performance more effectively. Interestingly, some well-known neural networks are not quantization-friendly, and experience severe accuracy degradation when quantized to 8 bits.
Finding the Ultimate Neural Architecture for a Specific AI Model is Tough
One of the central barriers to creating neural networks that can successfully solve AI challenges is the design of an appropriate “neural architecture”. This is the network’s blueprint that specifies the number of neurons in each layer and how they are interconnected. Network architecture design methods have evolved over the years, with the goal of discovering key design principles that improve the efficiency and accuracy of the resulting models. The most advanced architectures today rely on both human intelligence and heavy-duty computation to search large architectural spaces for useful models. These neural architecture search (NAS) techniques have discovered some of the most accurate models, but require Google-scale computational resources. A fourth generation of automatic NN architecture design techniques is now emerging. Techniques in this new family use sophisticated NAS algorithms that can optimize several objective metrics at once while taking into account the hardware platform they will run on—all without the need for Google-scale resources. This is the space we are going to take a closer look at.
As mentioned above, a given neural architecture can have very different inference runtime profiles on different AI chips. To achieve optimal runtime, neural architectures need to be optimized for specific chips, be able to make the most of graph compilers, and be capable of benefiting from quantization. But these factors severely complicate the design process. As AI chips become increasingly diverse, the implementation of hardware-dependent neural architectures is becoming more complex and expensive.
Automated Neural Architecture Construction
A unique NAS technology developed by Deci AI is able to optimize given NN models and explore, or even invent, totally new architectures. This technology is referred to as automated neural architecture construction (AutoNAC). AutoNAC is fully aware of the entire deep learning stack, including graph compilers (e.g., TensorRT for NVIDIA GPUs and Open Vino for Intel compilers) and quantization. In addition to being fully aware of the hardware, AutoNAC performs computations much faster than known NAS methods. What’s more, AutoNAC can perform constrained multi-objective optimization. For example, we’ve used it to find the fastest NN architecture compiled for a particular AI chip, while reaching a prescribed accuracy and making sure the memory footprint was within a specified size.
To apply AutoNAC for a target AI inference chip, we simply define a search space based on the operations and neural layers supported by the target chip. The search is performed autonomously and works by probing certain candidate architectures for their inference time (or other metrics) directly on that chip.
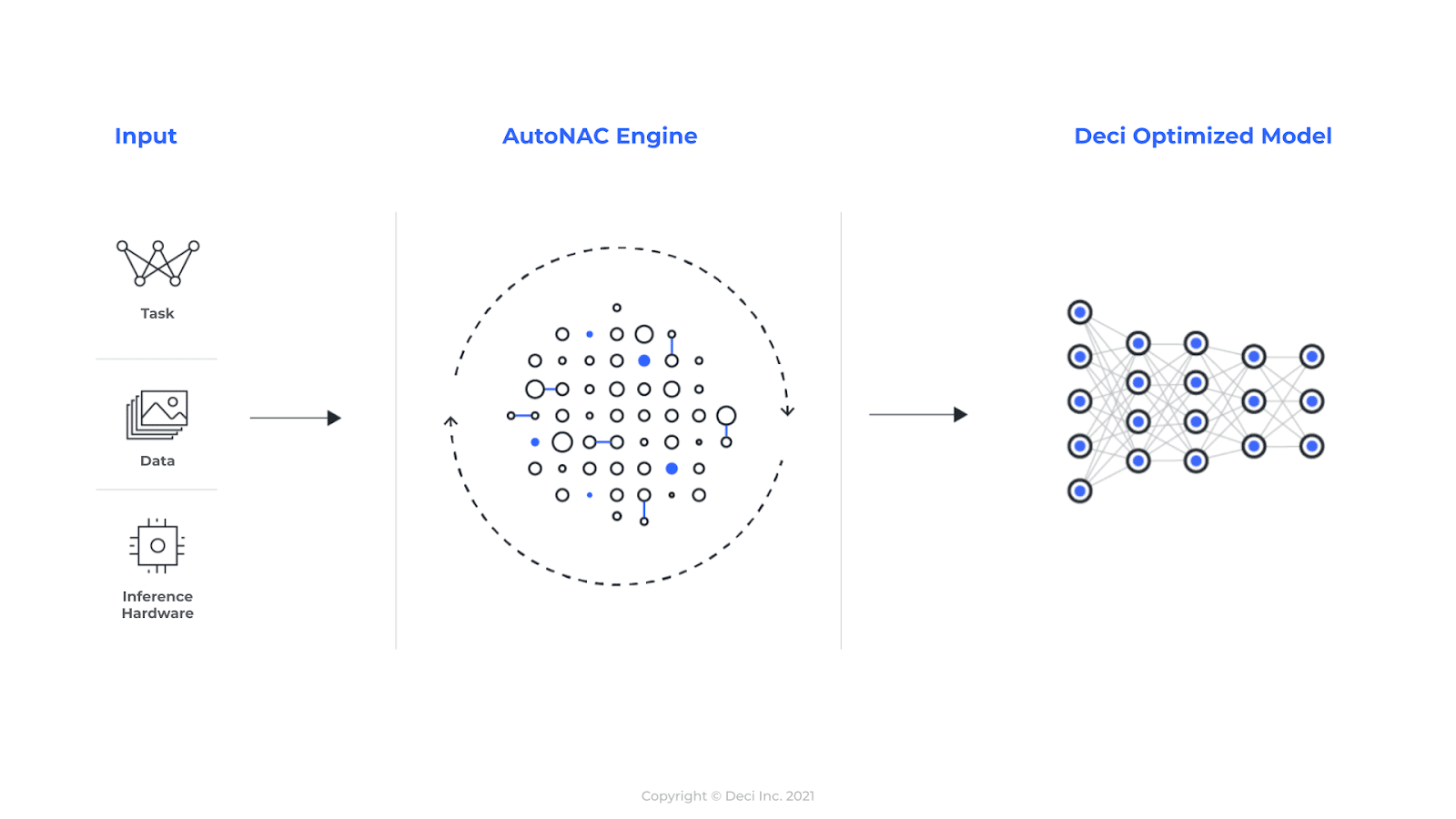
Figure 3. Schematic overview of the AutoNAC process
Standout Performance Achieved by AutoNAC-generated DeciNet Models
To more closely examine AutoNAC’s optimization performance, we applied AutoNAC on ImageNet classification over the NVIDIA T4 GPU chip and the NVIDIA Jetson Xavier NX edge GPU. AutoNAC generated new neural architectures called DeciNets. Strikingly, the new DeciNet models outperform many well-known and powerful models including EfficientNets and MobileNets. When you consider the accuracy versus latency performance tradeoff for each chip, DeciNets extend the efficient frontier for this task on both GPU types.
The results for the NVIDIA T4 GPU are depicted in the scatter plot of Figure 4, showing the ImageNet top-1 accuracy performance versus inference latency (batch size 1) for well-known models. Each model was compiled for the T4 GPU using TensorRT, and quantized to both 8-bit (INT8) and 16-bit (FP16) precision. For each model, the better among these two quantized models is presented in the plot. The new DeciNets clearly dominate the baseline architectures and advance the state-of-the-art for the T4 chip. For instance, EfficientNet B2 achieves 0.803 top-1 ImageNet accuracy with an inference time of 1.950 milliseconds. DeciNet-4 has the same accuracy and is almost 30% faster, while DeciNet-5 is both more accurate and faster.
Importantly, each of the DeciNets was discovered by AutoNAC using roughly four times the computation required to train a single network. This is incredible when you consider that EfficientNet was discovered using NAS technology that took two orders of magnitude more compute power.
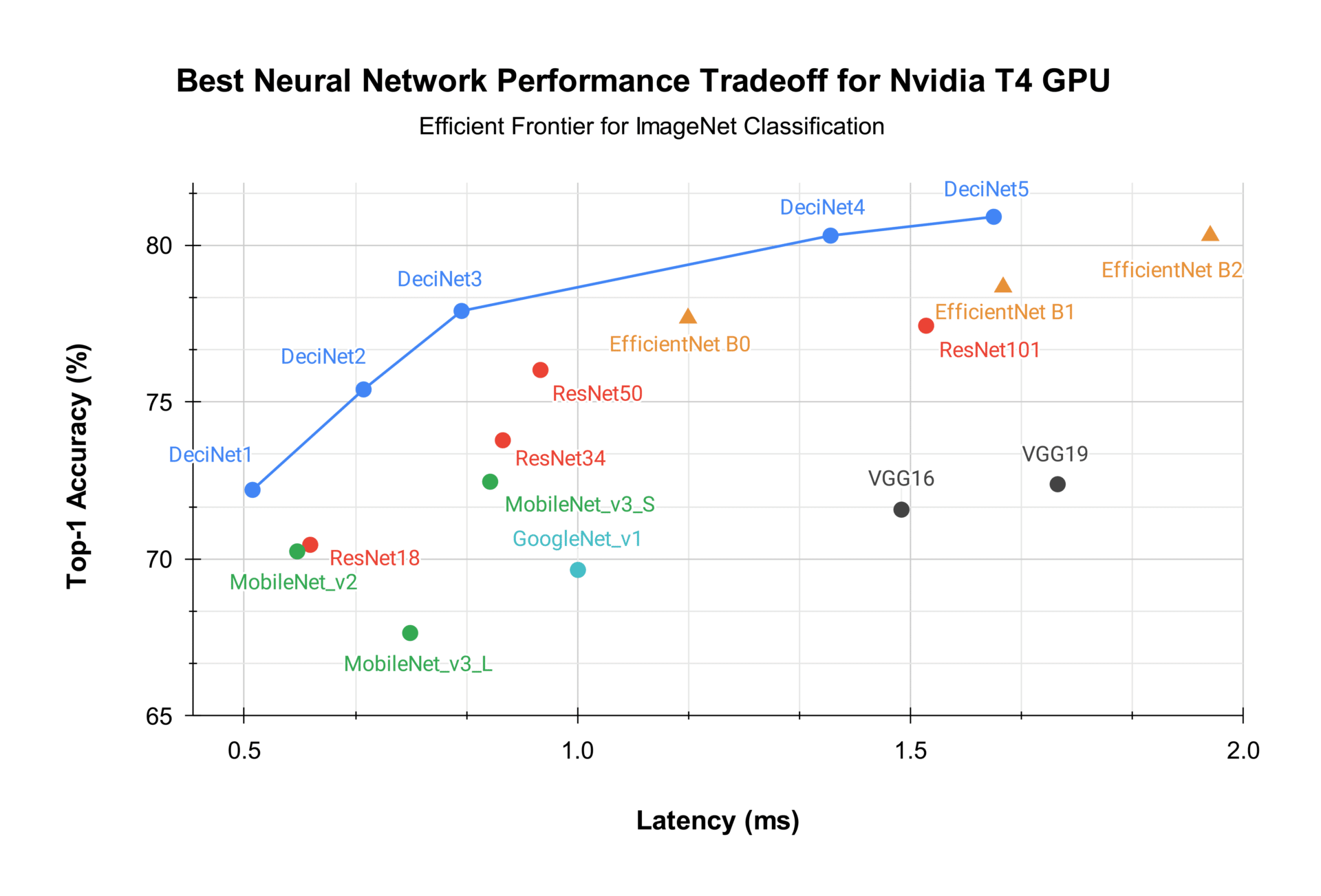
Figure 4. Best neural network performance tradeoff for NVIDIA T4 GPU. Accuracy vs. latency (ms) for DeciNet instances (blue) and various well-known deep learning classification models. Quantization levels were selected for each model to maximize accuracy-latency tradeoff. FP16 quantized models appear as triangles, while INT8 quantized models appear as dots. All models were quantized using TensorRT quantization following MLCommons rules. Source: Deci AI
In a second study, we applied AutoNAC for the NVIDIA Jetson Xavier NX GPU, an AI chip designed to optimize visual perception systems, autonomous robots and drones, handheld medical devices, smart appliances, security cameras, and more. The resulting architectures, called DeciNet Jets, once more outperformed well-known architectures. Figure 5 compares the accuracy-latency profiles of various models. As you can see, AutoNAC was able to significantly extend the efficient frontier and generate novel and powerful architectures for the Xavier edge GPU. Here we see some remarkable speedups. For instance, the EfficientNet-B0 with its 0.777 top-1 accuracy at 0.525 ms latency, is improved by DeciNet-3 both in terms of accuracy and by a factor of over 2x in latency.
In general, we expect AutoNAC to achieve more striking speedups when optimized for less explored AI chips. An attractive property of AutoNAC is that while it is hardware-aware, its application routine is nearly identical on all devices.
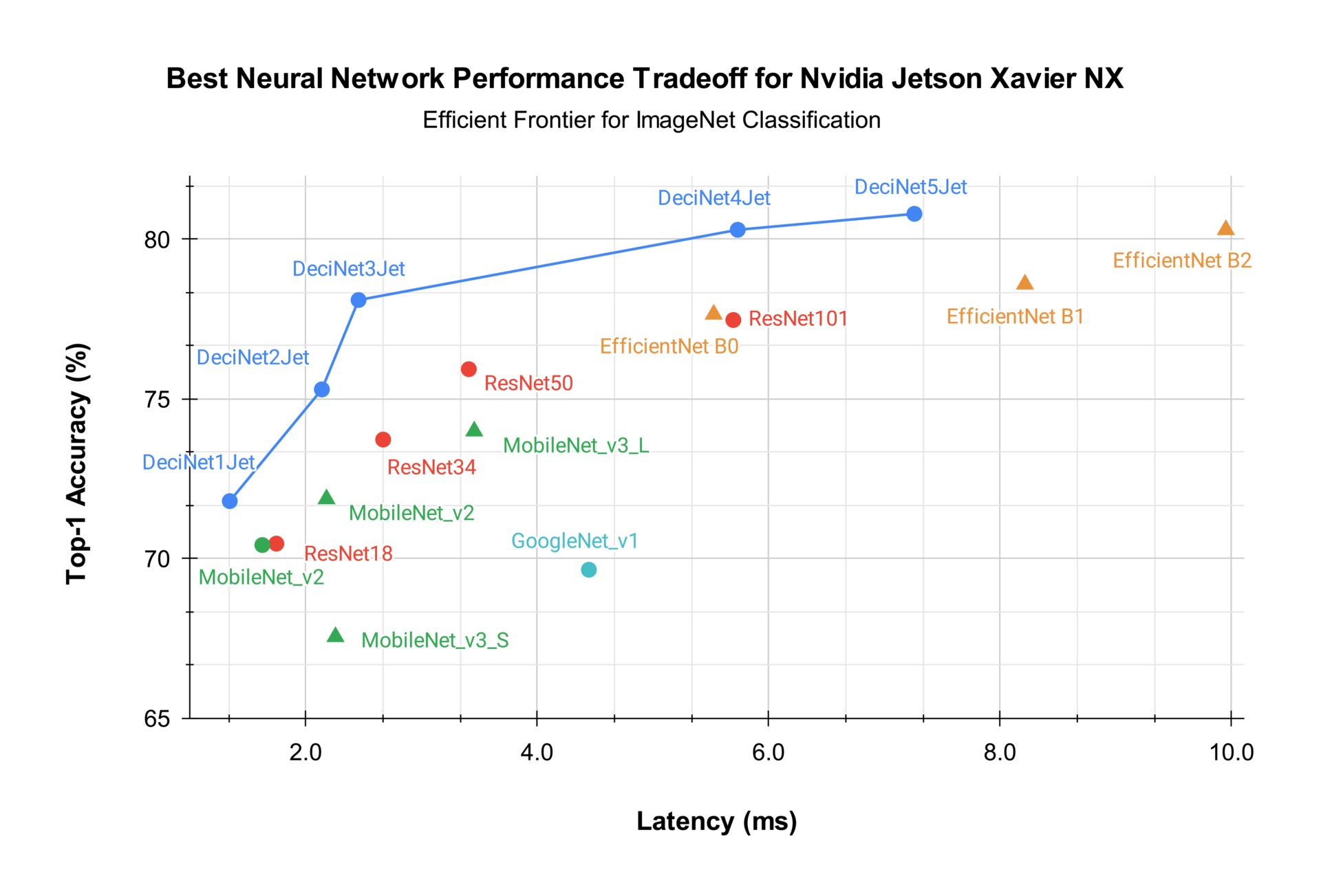
Figure 5. Best neural network performance tradeoff for NVIDIA Jetson Xavier NX edge GPU. Accuracy vs. latency (ms) for DeciNet instances (blue) and various well-known deep learning classification models. Quantization levels were selected for each model to maximize accuracy-latency tradeoff. FP16 quantized models appear as triangles, while INT8 quantized models appear as dots. All models were quantized using TensorRT quantization following MLCommons rules. Source: Deci AI
Looking forward, it’s clear that deep models will soon dominate almost all AI tasks and datasets. And we’ll likely see larger models that can simultaneously handle multi-modal tasks involving many types of data while achieving superior results in very advanced AI applications. Algorithmic acceleration techniques will have to ramp up to accommodate the cost-effectiveness of these new models on the cloud, and enable their application on edge devices. AutoNAC is a prime example of how new techniques are breaking old design barriers and enabling deep AI applications everywhere. To read more about DeciNets, we invite you to download the white paper.









