YOLO-NAS-Sat is a small object detection model, pre-trained on COCO, fine-tuned on DOTA 2.0.
Publishers Deci AI Team
Submitted Version February 22, 2024
Latest Version N/A
Size N/A
Small Object Detection
Overview
Performance
How to Use
License
Resources
Overview
YOLO-NAS-Sat is a small object detection model.
Model Highlights
Task: Small Object Detection
Model type: Deep Neural Network
Framework: PyTorch
Dataset: Pre-trained on COCO, fine-tuned on DOTA 2.0
Model Architecture
Building on the solid foundation of YOLO-NAS, renowned for its standard object detection, YOLO-NAS-Sat tackles the specific challenge of pinpointing small objects. While retaining the YOLO-NAS core, we’ve implemented key changes to sharpen its focus on small objects:
Backbone Modifications: The number of layers in the backbone has been adjusted to optimize the processing of small objects, enhancing the model’s ability to discern minute details.
Revamped Neck Design: A newly designed neck, inspired by the U-Net-style decoder, focuses on retaining more small-level details. This adaptation is crucial for preserving fine feature maps that are vital for detecting small objects.
Context Module Adjustment: The original “context” module in YOLO-NAS, intended to capture global context, has been replaced. We discovered that for tasks like processing large satellite images, a local receptive window is more beneficial, improving both accuracy and network latency.
These architectural innovations ensure that YOLO-NAS-Sat is uniquely equipped to handle the intricacies of small object detection, offering an unparalleled accuracy-speed trade-off.
YOLO-NAS-Sat offers four distinct size variants, each tailored for different computational needs and performances:
The expected input of the YOLO-NAS-Sat model is an RGB image of fixed size. The image is usually preprocessed by resizing it to the desired size and normalizing its pixel values to be between 0 and 1.
Expected Output
The expected output of the YOLO-NAS-Sat model is bounding boxes and confidence scores for detected objects.
History and Applications
While YOLO-NAS-Sat excels in satellite imagery analysis, its specialized architecture is also ideally tailored for a wide range of applications involving other types of images:
Satellite Images: Used for environmental monitoring, urban development tracking, agricultural assessment, and military surveillance.
Microscopic Images: Essential in medical research for detecting cells, bacteria, and other microorganisms, as well as in material science.
Radar Images: Applied in meteorology for weather prediction, in aviation for aircraft navigation, and in maritime for ship detection.
Thermal Images: Thermal imaging finds applications in a variety of fields, including security surveillance, wildlife monitoring, and industrial maintenance, as well as in building and energy audits. The unique information provided by thermal images, especially in night-time or low-visibility conditions, underlines its importance and the volume of use.
Metrics and Performance
Advanced Training Process
YOLO-NAS-Sat was trained from scratch on the COCO dataset, followed by fine-tuning on the DOTA 2.0 dataset. The DOTA 2.0 dataset is an extensive collection of aerial images designed for object detection and analysis, featuring diverse objects across multiple categories. For fine-tuning, the input scenes were segmented into 1024×1024 tiles, using a 512px step for comprehensive coverage. Additionally, each scene was scaled to 75% and 50% of its original size to enhance detection robustness across various scales.
During the training process, random 640×640 crops were extracted from these tiles to introduce variability and enhance model resilience. For the validation phase, the input scenes were divided into uniform 1024×1024 tiles.
Mean Average Precision
Mean Average Precision is a metric used to evaluate object detection models such as Fast R-CNN, YOLO, Mask R-CNN, etc. The mean of average precision (AP) value is calculated over recall values from 0 to 1. A higher mean average precision indicates better accuracy.
Mean Average Precision (mAP) is based on the following sub-metrics.
Intersection Over Union (IOU)
Recall
Precision
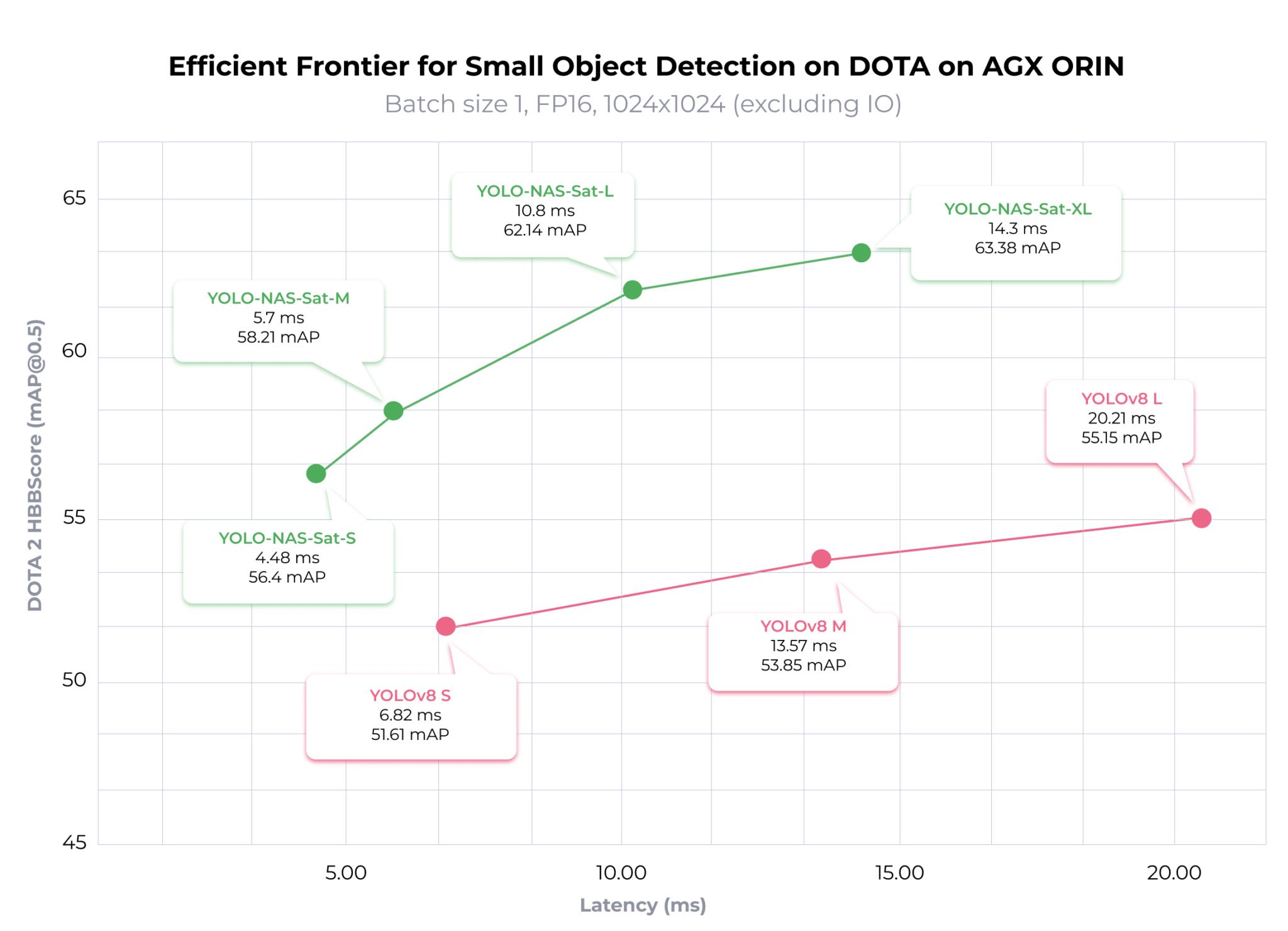
To benchmark YOLO-NAS-Sat against YOLOv8, we subjected YOLOv8 to the same fine-tuning process previously outlined for YOLO-NAS-Sat.
While higher accuracy typically demands a trade-off in speed, the finely tuned YOLO-NAS-Sat models break this convention by achieving lower latency compared to their YOLOv8 counterparts. However, on NVIDIA AGX Orin at TRT FP16 Precision, each YOLO-NAS-Sat variant outpaces the corresponding YOLOv8 variant.
As can be seen in the above graph, YOLO-NAS-Sat S outpaces its YOLOv8 counterpart by 1.52 times, YOLO-NAS-Sat M by 2.38 times, and YOLO-NAS-Sat L by 2.02 times.
How to Use
YOLO-NAS-Sat supports the same .predict () functionality as regular YOLO-NAS. However, we do not open-source model weights, therefore one needs to obtain weights from Deci’s platform in order to use it.
License
The YOLO-NAS Sat model is available under commercial license. To learn more, request a free trial.