Description YOLO-NAS is an object detection model pre-trained on COCO, and Objects365, and evaluated on COCO and RF100 dataset.
Publishers Deci AI Team
Submitted Version May 3, 2023
Latest Version N/A
Size N/A
Object Detection
Overview
Performance
How to Use
License
Resources
Overview
Model Highlights
Task: Object Detection
Model type: Deep Neural Network
Framework: PyTorch
Dataset: Trained onCOCO, Objects365 Datasets and Evaluated on RF100 Dataset.
Model Size and Parameters
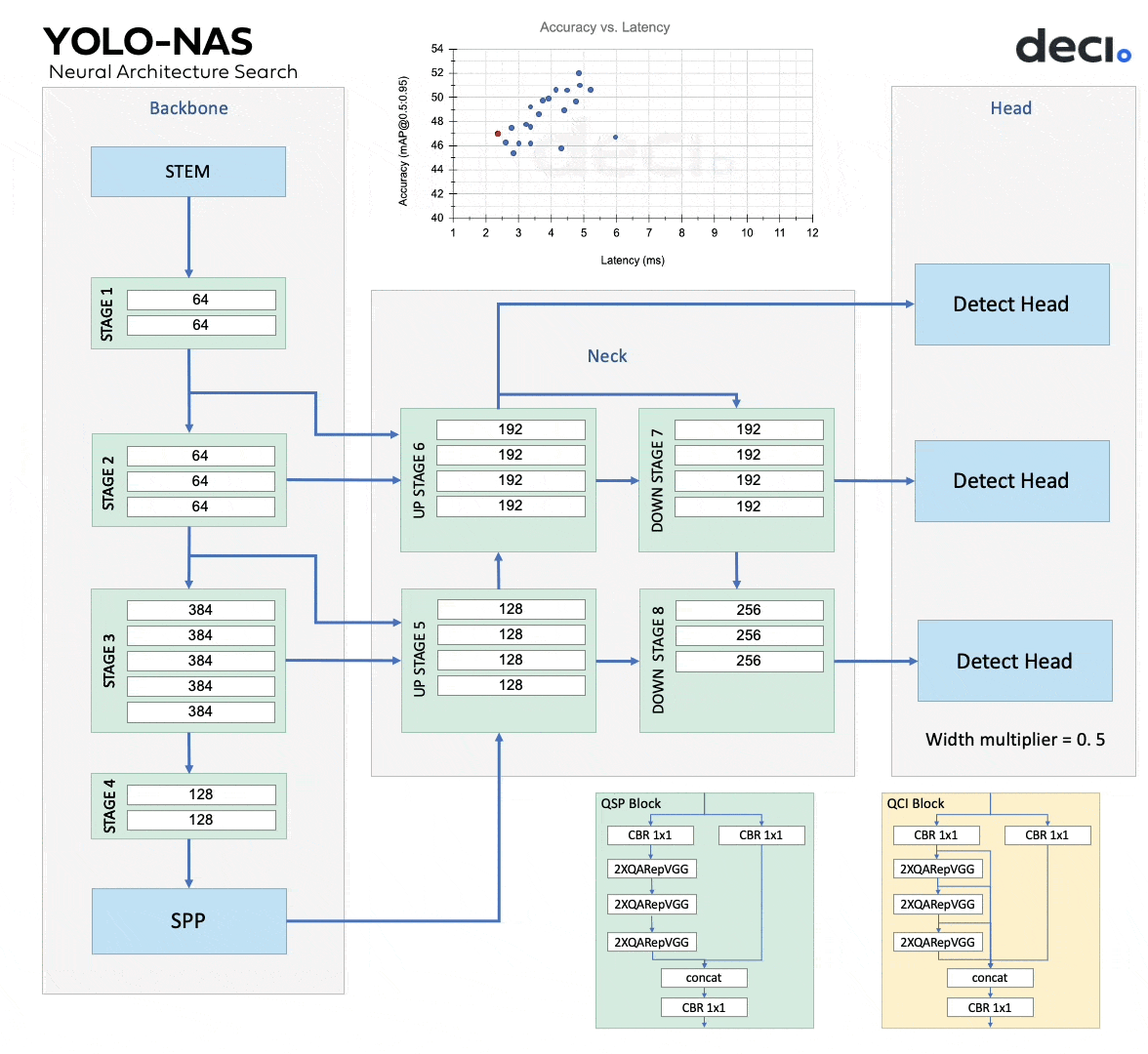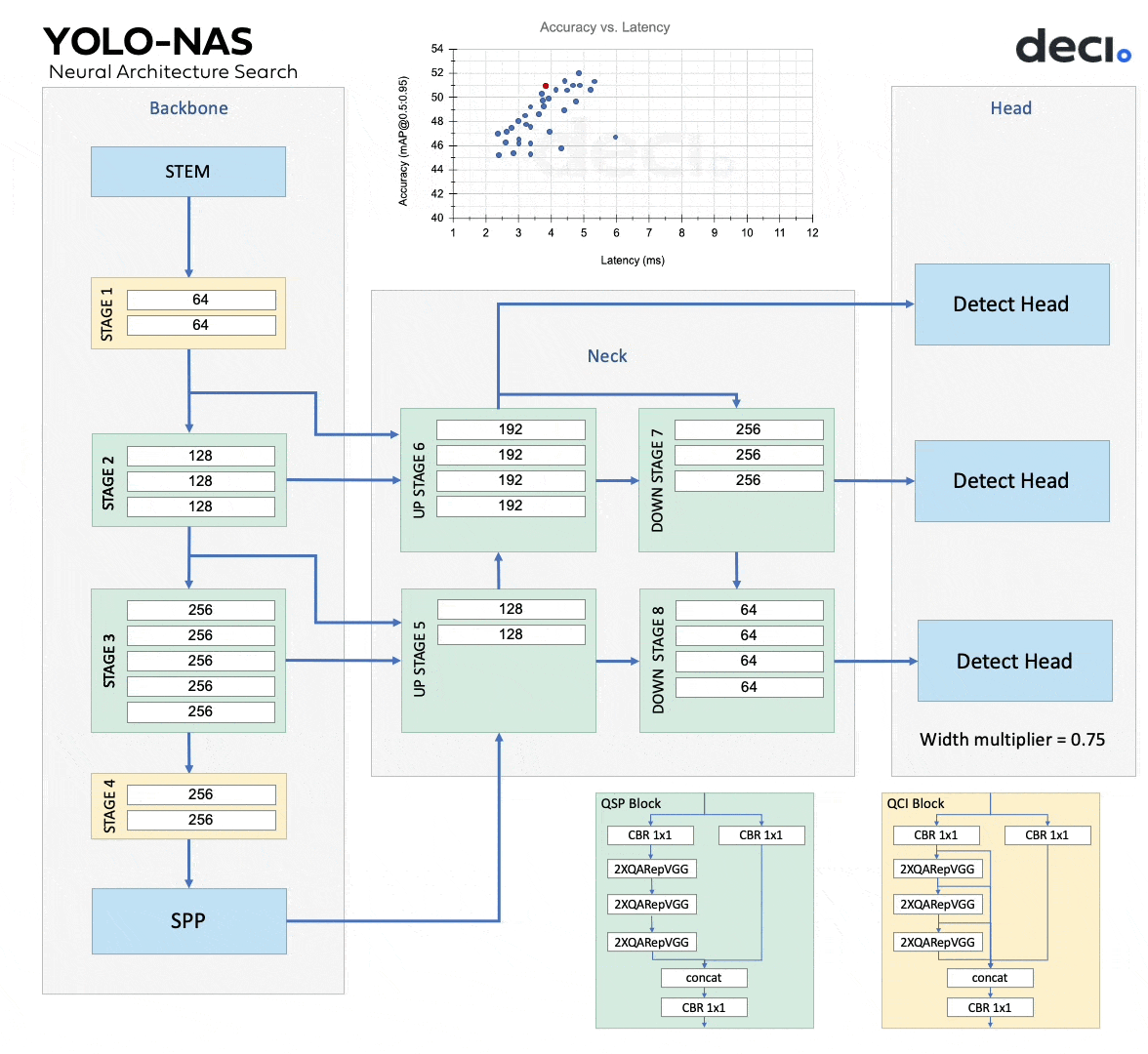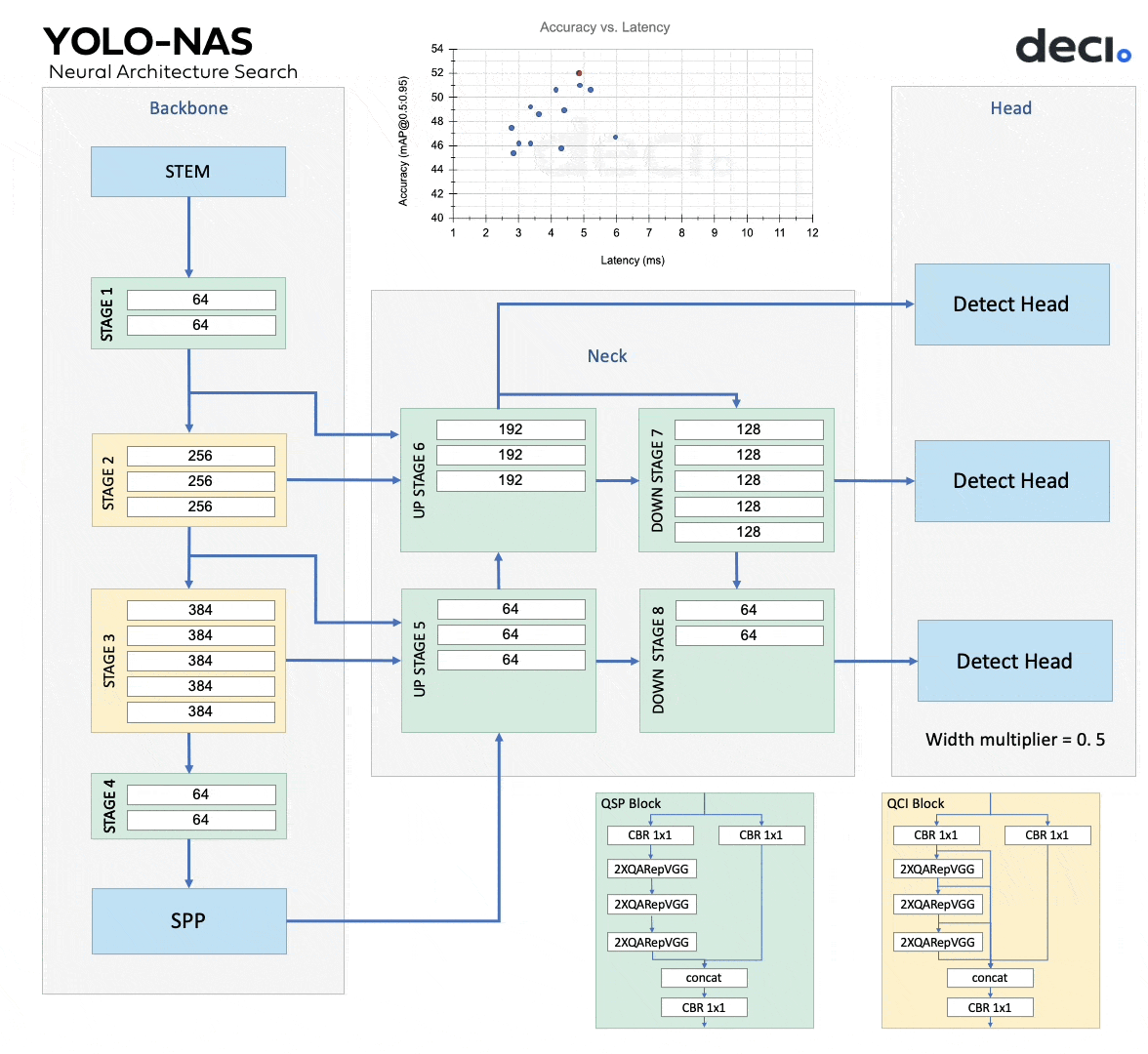
The animation below shows different potential models, and the three of them are YOLO-NAS-S, YOLO-NAS-M, YOLO-NAS-L.
The architectures of YOLO-NAS models were found using Deci’s proprietary Neural Architecture Search (NAS) technology, AutoNAC. AutoNAC was used to ascertain the optimal sizes and structures of stages, encompassing block type, the number of blocks, and the number of channels in each stage. Throughout the NAS process, Quantization-Aware RepVGG (QA-RepVGG) blocks are incorporated into the model architecture, guaranteeing the model’s compatibility with Post-Training Quantization (PTQ). Using quantization-aware “QSP” and “QCI” modules consisting of QA-RepVGG blocks provides 8-bit quantization and reparameterization benefits, enabling minimal accuracy loss during PTQ. A hybrid quantization method is also used that selectively quantizes specific layers to optimize accuracy and latency tradeoffs while maintaining overall performance.
YOLO-NAS offers three different model sizes: YOLO-NAS-S, YOLO-NAS-M, YOLO-NAS-L. Each model variant is designed to offer a balance between Mean Average Precision (mAP) and latency. The YOLO-NAS-S model is the smallest and fastest, but it is not as accurate as the larger models. Conversely, the YOLO-NAS-L model is the largest, most accurate, and slowest.
The YOLO-NAS-M model offers a middle ground between the two. Table 1 details the comparison of each of these models in terms of Mean Average Precision (mAP) and latency. The mAP numbers in the table are reported for the Coco 2017 Val dataset and latency benchmarked for 640×640 images on the Nvidia T4 GPU.
Model
mAP
Latency (ms)
YOLO-NAS S
47.5
3.21
YOLO-NAS M
51.55
5.85
YOLO-NAS L
52.22
7.87
YOLO-NAS S INT-8
47.03
2.36
YOLO-NAS M INT-8
51.0
3.78
YOLO-NAS L INT-8
52.1
4.78
Expected Input
YOLO-NAS takes an image as an input.
Expected Output
YOLO-NAS outputs bounding boxes, labels and confidence scores and using the predict function we can draw these bounding boxes around each of the detected objects and add the labels and the confidence scores.
History and Applications
Invented in 2015, YOLO is a state-of-the-art object detection algorithm. Thanks to its speed, it has now become a standard way of detecting objects in the field of Computer Vision. Previously, people were using Sliding Window Object Detection, then faster versions were invented, which include RCNN, Fast RCNN, and Faster RCNN. YOLO outperforms these previous object detection algorithms.
YOLO-NAS was released by DeciAI on May 03, 2023. YOLO-NAS outperforms other YOLO models by achieving a better trade-off between speed and accuracy than its counterparts, including PPYOLOE, YOLOv5, YOLOv6, YOLOv7, and YOLOv8.
Some real-world applications of YOLO-NAS include:
Video Surveillance (Security, Performance & Safety, Retail)
Medical Diagnosis (Tumor Detection, Neurological Diagnosis, Health Monitoring, Remote Patient Monitoring)
Research: The YOLO algorithm can be used in all kinds of research. For example, the algorithm can be used to detect movement in wildlife or for tracking targets. The algorithm can even be used to detect spots or patches from geographic data.
Metrics and Performance
Training and Evaluation Data, and Metrics
YOLO-NAS models were pre-trained on the famous Object365 benchmark dataset—a dataset consisting of 2M images and 365 categories. After pseudo labeling, it is pretrained on 123k COCO unlabelled images. Knowledge Distillation (KD) and Distribution Focal Loss (DFL) were also incorporated to enhance the training process of the YOLO-NAS models. After pretraining the YOLO-NAS models on Object 365 and COCO dataset, the YOLO-NAS models’ performance was tested on the RoboFlow100 dataset to showcase its ability to handle complex object detection tasks. The results demonstrate that YOLO-NAS models outperform YOLOv8, YOLOv7, and YOLOv5 models by a good margin.
Mean Average Precision
Mean Average Precision is a metric used to evaluate object detection models such as Fast R-CNN, YOLO, Mask R-CNN, etc. The mean of average precision (AP) value is calculated over recall values from 0 to 1. A higher mean average precision indicates better accuracy.
Mean Average Precision (mAP) is based on the following sub-metrics.
Intersection Over Union (IOU)
Recall
Precision
Inference Performance
When selecting an architecture there are several things you should carefully consider:
What is the expected performance of the architecture on your target inference hardware (Optimized for T4 GPU)?
What is the architecture performance after compilation and quantization?
Does this architecture deliver the best accuracy-speed tradeoff for your specific project?
Having clarity on these topics before you start training the model can save you a lot of time, effort, and money.
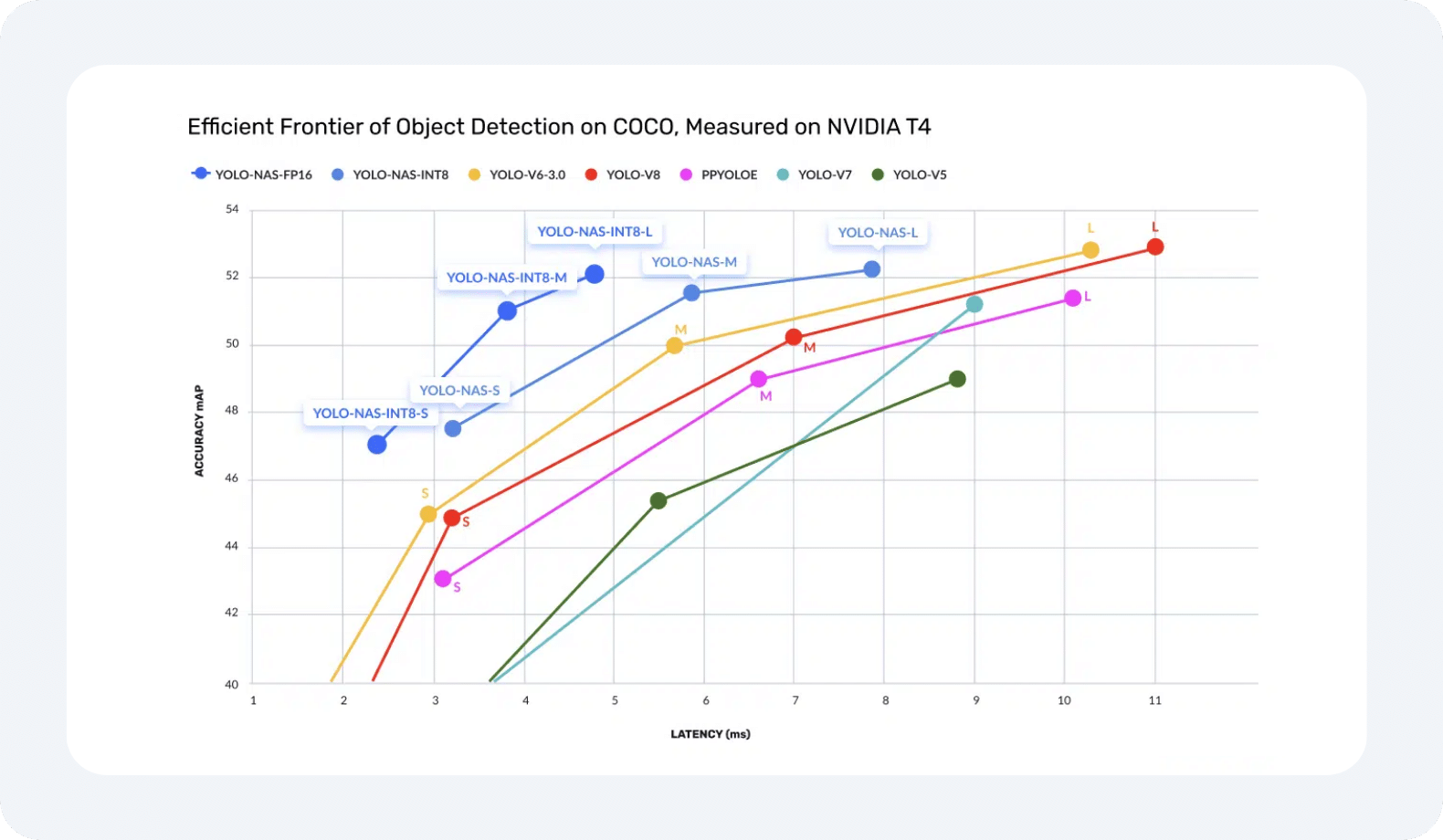
The graph shows the efficiency frontier plot for object detection on the COCO2017 dataset (validation) comparing YOLO-NAS vs other YOLO architectures.
YOLO-NAS (m) model delivers a 50% (x1.5) increase in throughput and 1 mAP better accuracy compared to other SOTA YOLO models on the NVIDIA T4 GPU.
How to Use
You can use the YOLO-NAS model to do object detection on images and videos. Below, see how you can easily load the YOLO-NAS pretrained model and use it for object detection.