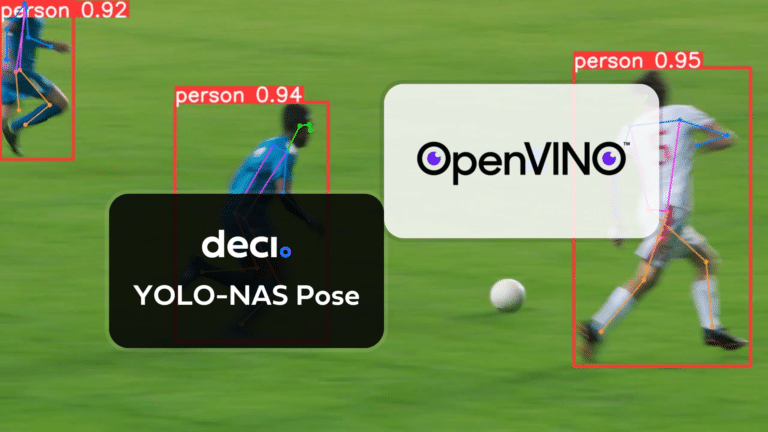
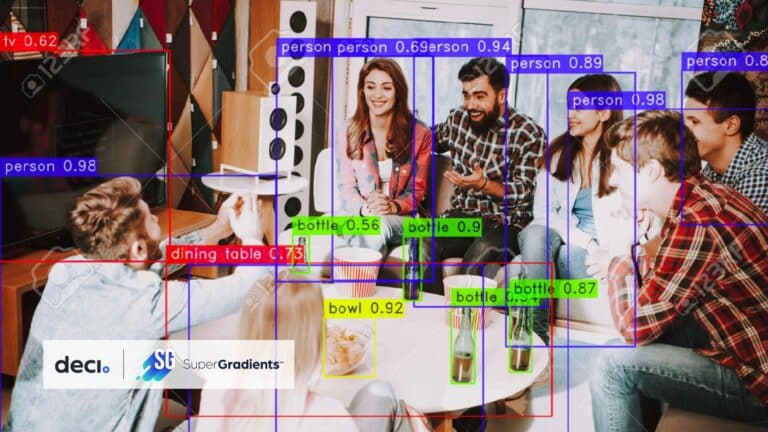
SuperGradients is a cutting-edge open-source training library for training from scratch or fine-tuning of pre-trained PyTorch-based deep learning models. With its user-friendly API, SuperGradients makes it easy to load and customize production-ready models with state-of-the-art accuracy, and streamline your machine learning workflow. Whether you’re looking to improve your deep learning model’s performance or streamline its deployment, SuperGradients has the tools and features you need to take your projects to the next level.
In this blog, we will review the latest features introduced into SuperGradients. If you are already a SuperGradients user this is a great opportunity to learn how you can get more out of your existing training platform. If you are new to SuperGradients, we suggest you start from our documentation website, although this blog might open your eyes to some cool new features that will give you a good understanding of what you can find in our training library.
Training with Configurations Files
Before we get into the nitty-gritty details of using different SuperGradients features, it’s a good idea to go through some training with configuration files in SuperGradients. We designed SuperGradients to expose as many parameters as possible and allow outside configuration without writing a single line of code. By becoming more familiar with the configuration files, you’ll be able to control the learning rate, the weight decay, or the loss function and metric used in the training. You can even control which block-type or activation function to use in your model. So, if you don’t yet know how to define all these parameters, head over to the link and then jump back here for information on the different features.
What’s new in SuperGradients?
Pre-Launch Callbacks and the AutoTrainBatchSizeSelectionCallback
Pre-Launch Callbacks are an important feature that allows you to perform certain tasks before the actual training of the model begins. This can be useful for things like setting up the training environment, changing model hyperparameters, and initializing different components of the training process.
One of the callbacks available, called AutoTrainBatchSizeSelectionCallbackCUDA out of memorymax_batch_sizeCUDA out of memoryAutoTrainBatchSizeSelectionCallback
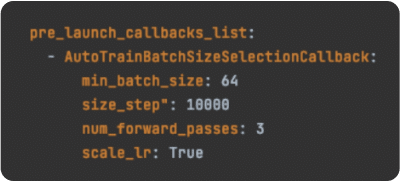
This callback will automatically select the best batch size for training your model. The min_batch_size parameter specifies the minimum batch size that can be used for training, while the size_step parameter sets the step size for increasing the batch size. The num_forward_passes parameter specifies the number of forward passes to be used for measuring the training performance, and the scale_lr parameter determines whether the learning rate should be scaled based on the batch size.
If we launch the Cifar-10 dataset with the above automatic batch sizing feature, the screen will look like this:
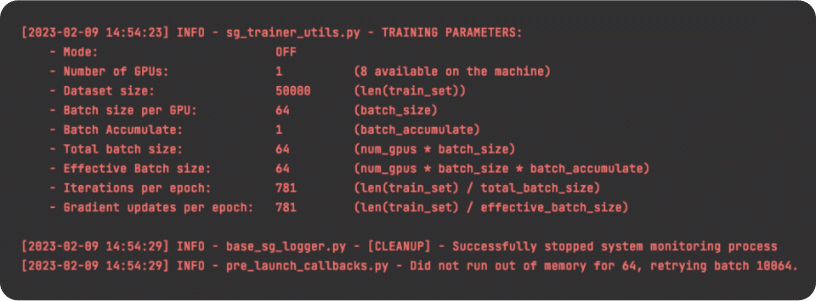
To utilize this pre launch callbacks feature, simply create a custom class that inherits from PreLaunchCallback and implements the __call__ method. Then you can use this class to perform any necessary modifications to the cfg prior to launching the training.
EMA: New Schedules + Support for Custom EMA Schedules
Exponential Moving Average (EMA) is a smoothing technique used in training machine learning models. It helps to reduce the noise in the training process and improve the generalization of the model. EMA is a simple technique that can be used with any model and optimizer.
Here’s how to use EMA in SuperGradients:
from super_gradients import Trainer
trainer = Trainer(...)
trainer.train(
training_params={"ema": True, "ema_params": {"decay": 0.9999, "decay_type": "constant"}, ...},
...
)
The decay hyperparameter controls the speed at which the EMA is updated and must be within the range (0,1). Larger values of decay will result in a slower EMA model update.
SuperGradients supports several types of changing decay values over time:
- constant:
"ema_params": {"decay": 0.9999, "decay_type": "constant"} - threshold:
"ema_params": {"decay": 0.9999, "decay_type": "threshold"} - exp:
"ema_params": {"decay": 0.9999, "decay_type": "exp", "beta": 15}
You can also implement a custom decay schedule by subclassing the IDecayFunction:
from super_gradients.training.utils.ema_decay_schedules import IDecayFunction, EMA_DECAY_FUNCTIONS
class LinearDecay(IDecayFunction):
def __init__(self, **kwargs):
pass
def __call__(self, decay: float, step: int, total_steps: int) -> float:
"""
Compute EMA for a specific training step following a linear scaling rule [0..decay)
:param decay: The maximum decay value.
:param step: Current training step. The unit-range training percentage can be obtained by `step / total_steps`.
:param total_steps: Total number of training steps.
:return: Computed decay value for a given step.
"""
training_progress = step / total_steps
return decay * training_progress
EMA_DECAY_FUNCTIONS["linear"] = LinearDecay
Phase Callbacks API
In deep learning, a phase callback is a function that is called at specific points during the training process of a model. The purpose of a phase callback is to allow the user to perform certain actions or modify certain parameters of the model at specific phases of the training process.
Integrating your own code into an existing training pipeline can take a lot of effort. To tackle this challenge, a list of callables triggered at specific points of the training code can be passed through phase_calbacks_list inside training_params when calling Trainer.train(...).
There are different types of phase callbacks that can be easily implemented using the SuperGradients super_gradients.training.utils.callbacks module, including the following:
ModelConversionCheckCallbackLRCallbackBaseEpochStepWarmupLRCallbackBatchStepLinearWarmupLRCallbackStepLRCallbackExponentialLRCallbackPolyLRCallbackCosineLRCallbackFunctionLRCallbackLRSchedulerCallbackDetectionVisualizationCallbackBinarySegmentationVisualizationCallbackTrainingStageSwitchCallbackBaseYoloXTrainingStageSwitchCallback
For example, the YoloX COCO detection training recipe uses YoloXTrainingStageSwitchCallback to turn off augmentations and incorporate L1 loss starting from epoch 285:
super_gradients/recipes/training_hyperparams/coco2017_yolox_train_params.yaml:
max_epochs: 300
...
loss: yolox_loss
...
phase_callbacks:
- YoloXTrainingStageSwitchCallback:
next_stage_start_epoch: 285
...
Another example would be the use of the BinarySegmentationVisualizationCallback to visualize predictions during training in our Segmentation Transfer Learning Notebook.
In this case, the SG callback needs to inherit from the above class and override the appropriate methods, based on the points at which we would like to trigger the action.
To understand which methods you need to override, you need to understand better when the above methods are triggered.
From the class docs, the order of the events is as follows:
on_training_start(context) # called once before training starts, good for setting up the warmup LR
for epoch in range(epochs):
on_train_loader_start(context)
for batch in train_loader:
on_train_batch_start(context)
on_train_batch_loss_end(context) # called after loss has been computed
on_train_batch_backward_end(context) # called after .backward() was called
on_train_batch_gradient_step_start(context) # called before the optimizer step about to happen (gradient clipping, logging of gradients)
on_train_batch_gradient_step_end(context) # called after gradient step was done, good place to update LR (for step-based schedulers)
on_train_batch_end(context)
on_train_loader_end(context)
on_validation_loader_start(context)
for batch in validation_loader:
on_validation_batch_start(context)
on_validation_batch_end(context)
on_validation_loader_end(context)
on_validation_end_best_epoch(context)
on_test_start(context)
for batch in test_loader:
on_test_batch_start(context)
on_test_batch_end(context)
on_test_end(context)
on_training_end(context) # called once after training ends.
As you can see, all the Callback methods expect a single argument – a PhaseContext instance. This argument gives access to some variables at the points mentioned above in the code through its attributes. We can discover what variables are exposed by looking at the documentation of the Callback‘s specific methods we need to override.
For example:
...
def on_training_start(self, context: PhaseContext) -> None:
"""
Called once before the start of the first epoch
At this point, the context argument is guaranteed to have the following attributes:
- optimizer
- net
- checkpoints_dir_path
- criterion
- sg_logger
- train_loader
- valid_loader
- training_params
- checkpoint_params
- architecture
- arch_params
- metric_to_watch
- device
- ema_model
...
:return:
"""
Now let’s implement our callback. Suppose we would like to implement a simple callback that saves the first batch of images in each epoch for both training and validation in a new folder called “batch_images” under our local checkpoints directory.
Our callback needs to be triggered in 3 places:
- At the start of training, create a new “batch_images” under our local checkpoints directory.
- Before passing a train image batch through the network.
- Before passing a validation image batch through the network.
To do this, our callback will override Callback‘s on_training_start, on_train_batch_start, and on_validation_batch_startmethods:
from super_gradients.training.utils.callbacks import Callback, PhaseContext
from super_gradients.common.environment.ddp_utils import multi_process_safe
import os
from torchvision.utils import save_image
class SaveFirstBatchCallback(Callback):
def __init__(self):
self.outputs_path = None
self.saved_first_validation_batch = False
@multi_process_safe
def on_training_start(self, context: PhaseContext) -> None:
outputs_path = os.path.join(context.ckpt_dir, "batch_images")
os.makedirs(outputs_path, exist_ok=True)
@multi_process_safe
def on_train_batch_start(self, context: PhaseContext) -> None:
if context.batch_idx == 0:
save_image(context.inputs, os.path.join(self.outputs_path, f"first_train_batch_epoch_{context.epoch}.png"))
@multi_process_safe
def on_validation_batch_start(self, context: PhaseContext) -> None:
if context.batch_idx == 0 and not self.saved_first_validation_batch:
save_image(context.inputs, os.path.join(self.outputs_path, f"first_validation_batch_epoch_{context.epoch}.png"))
self.saved_first_validation_batch = True
Note the @multi_process_safe decorator, which allows the callback to be triggered precisely once when running distributed training.
For coded training scripts (i.e., not using configuration files), we can pass an instance of the callback through phase_callbacks:
...
...
trainer = Trainer("my_experiment")
train_dataloader = ...
valid_dataloader = ...
model = ...
train_params = {
...
"loss": "cross_entropy",
"criterion_params": {}
...
"phase_callbacks": [SaveFirstBatchCallback()],
}
trainer.train(training_params=train_params, train_loader=train_dataloader, valid_loader=valid_dataloader)
Wrap up
The recent versions of SuperGradients have been packed with new and improved features aimed at streamlining the deep learning workflow. Pre-Launch Callbacks, like the AutoTrainBatchSizeSelectionCallback, allow users to perform various tasks before the actual training of the model begins, such as setting up the environment, changing model hyperparameters, and initializing the training process components. The Exponential Moving Average (EMA) feature provides a smoothing technique to improve the generalization of models, with several types of decay schedules available (constant, threshold, exp) and the ability to implement custom decay schedules by subclassing IDecayFunction. Additionally, the new Phase Callbacks API allows for greater customization of the training pipeline by passing a list of callables that can be triggered at specific points of the training code.