
Authors:
- Eugene Khvedchenya, Deep Learning Research Engineer
- Harpreet Sahota, DevRel Manager
Introduction
Object detection has revolutionized how machines perceive and interpret the world around them.
It’s a crucial task in computer vision, enabling machines to recognize and locate objects within images or videos. Over the years, this technology has become increasingly robust and accurate, making it indispensable across many applications that shape our modern world, such as autonomous vehicles, facial recognition systems, and more. One key factor that has driven the progress of object detection is the discovery of powerful neural network architectures. The discovery of powerful neural network architectures has driven the advancement of object detection, enhancing the capabilities of computer vision.
In particular, architectures such as Faster R-CNN and YOLO have been instrumental in shaping modern object detection architectures.
YOLO, which stands for You Only Look Once, is one of the most popular and successful approaches to object detection.
The first version of YOLO was introduced in 2016 and changed how object detection was performed by treating object detection as a single regression problem. It divided images into a grid and simultaneously predicted bounding boxes and class probabilities. Though it was faster than previous object detection methods, YOLOv1 had limitations in detecting small objects and struggled with localization accuracy. Since the first YOLO architecture hit the scene, several YOLO-based architectures have been developed, all known for their accuracy, real-time performance, and enabling object detection on edge devices and in the cloud.
YOLOv6, YOLOv7, and YOLOv8 are the current state-of-the-art models from the YOLO family, building on the success of YOLOv5.
But just because we have all these YOLOs doesn’t mean that deep learning for object detection is a dormant area of research.
Developing a new YOLO-based architecture can redefine state-of-the-art (SOTA) object detection by addressing the existing limitations and incorporating recent advancements in deep learning. Imagine a new YOLO-based architecture that could enhance your ability to detect small objects, improve localization accuracy, and increase the performance-per-compute ratio, making the model more accessible for real-time edge-device applications.
By pushing the boundaries of accuracy and efficiency, a new YOLO architecture could become a benchmark for object detection, driving innovation and unlocking new possibilities across many industries and research domains. And that’s precisely what we’ve done here at Deci.
In this post, we’d like to introduce you to our new architecture – YOLO-NAS.
At Deci, we are committed to advancing the frontier of AI development by constantly pushing ourselves to improve. The tradeoff between accuracy and latency is well-known to deep learning practitioners. Accuracy often comes at the cost of time; the most precise models are typically the slowest. Our tools enable teams to overcome this and other challenges and allow them to develop fast and accurate models. Our success in addressing this task has positioned us as leaders in the field.
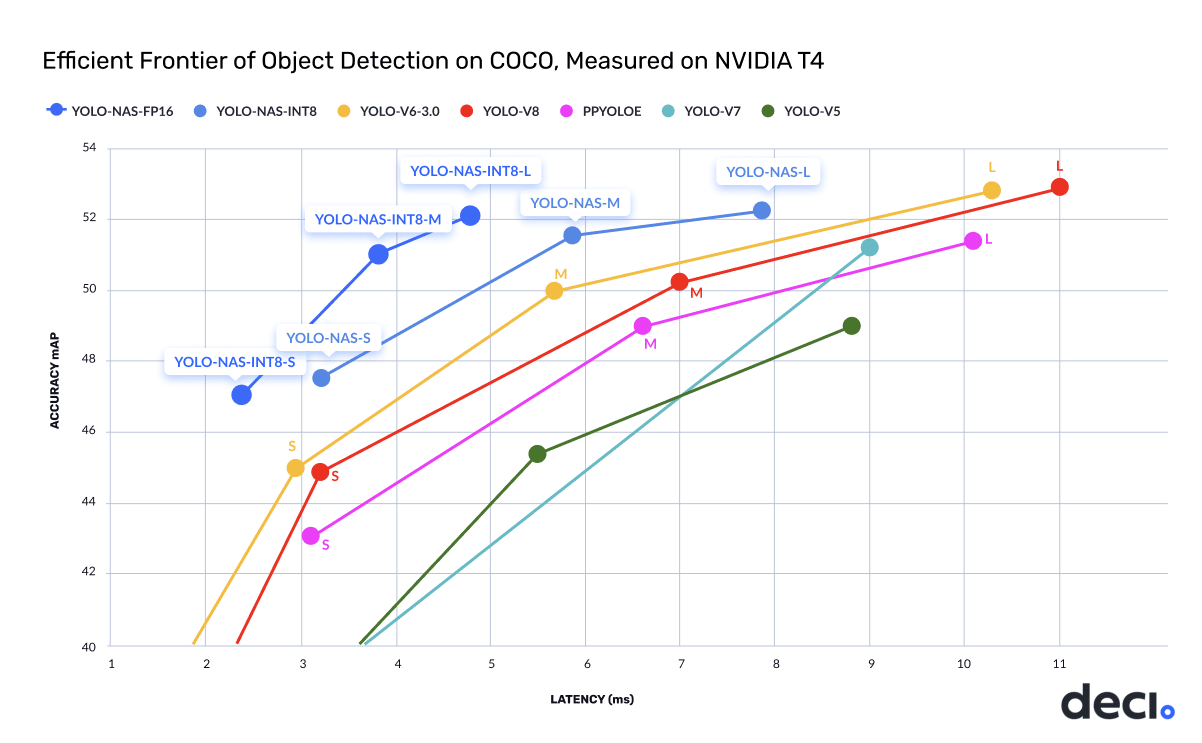
TL;DR: What’s New in the YOLO-NAS Architecture?
- The use of QSP and QCI blocks combine re-parameterization and 8-bit quantization advantages. These blocks rely on an approach suggested by Chu et al. Blocks allow for minimal accuracy loss during post-training quantization.
- Deci’s proprietary NAS technology, AutoNAC, was used to determine optimal sizes and structures of stages, including block type, number of blocks, and number of channels in each stage.
- A hybrid quantization method that selectively quantizes certain parts of a model, reducing information loss and balancing latency and accuracy. Standard quantization affects all model layers, often leading to significant accuracy loss. Our hybrid method optimizes quantization to maintain accuracy by only quantizing certain layers while leaving others untouched. Our layer selection algorithm considers each layer’s impact on accuracy and latency, as well as the effects of switching between 8-bit and 16-bit quantization on overall latency.
- A pre-training regimen that includes automatically labeled data, self-distillation, and large datasets.
- The YOLO-NAS architecture is available under an open-source license. Its’ pre-trained weights are available for research use (non-commercial) on SuperGradients, Deci’s PyTorch-based, open-source, computer vision training library.
The new YOLO-NAS architecture sets a new frontier for object detection tasks, offering the best accuracy and latency tradeoff performance.
This balance outperforms existing models today, setting a new standard for state-of-the-art (SOTA) object detection. Designed specifically for production use, YOLO-NAS is fully compatible with high-performance inference engines like NVIDIA® TensorRT™ and supports INT8 quantization for unprecedented runtime performance.
This optimization allows YOLO-NAS to excel in real-world scenarios, such as autonomous vehicles, robotics, and video analytics applications, where low latency and efficient processing are essential.
The model’s innovative architecture also leverages cutting-edge techniques, such as attention mechanisms, quantization aware blocks, and reparametrization at inference time to further improve its object detection capabilities. These contribute to YOLO-NAS’s exceptional performance in detecting objects of varying sizes and complexities, creating a new gold standard for use cases across industries.
As you’ll learn in this post, YOLO-NAS sets a new benchmark for object detection models regarding the accuracy and latency tradeoffs.
We Used Deep Learning to Find a New Deep Learning Architecture!
Inspired by the success of the most recent YOLO architecture, YOLOv8, our researchers challenged themselves to find a more performant architecture.
Utilizing our proprietary neural architecture search (NAS) algorithm, The Automated Neural Architecture Construction (AutoNAC) engine, our research team discovered a new architecture that outperforms YOLOv8.
We used machine learning to find a new deep learning architecture!
Why do it this way?
Finding the “right” architecture by hand is extremely tedious and inefficient. So, we applied AutoNAC to discover novel object detection models optimized to minimize inference latency computed over NVIDIA’s T4 – a widely used cloud GPU. AutoNAC used a neural design space incorporating SOTA architectural design principles and Deci’s novel neural elements.
Utilizing NAS offers significant advantages over manual exploration.
NAS algorithms can systematically explore the vast search space of potential architectures, effectively identifying novel and optimized configurations that might be overlooked by human intuition. By automating the process, these algorithms can efficiently evaluate and compare a vast number of candidate architectures, ultimately converging on a solution that optimally balances accuracy, speed, and complexity.
Although Neural Architecture Search (NAS) has been suggested to automate the development of better artificial neural networks that outperform manually-designed architectures, it has been deemed impractical due to the significant resource requirements it entails. Only large companies with extensive computing resources have utilized NAS, making it inaccessible to most developers. AutoNAC has introduced a solution to this problem by bringing into play a new, fast, and compute-efficient generation of NAS algorithms allowing it to operate cost-effectively and at scale.
The AutoNAC engine is hardware and data-aware and considers all the components in the inference stack, including compilers and quantization.
To create YOLO-NAS, our research team started with an unfathomable search space of 10^14 possible architectures.
Our AutoNAC engine traversed this search space and honed in on the region we call “the efficiency frontier.” AutoNAC explores and maps the efficiency frontier, searching for an architecture that best balances latency vs. throughput. We sample three points of this frontier to create the YOLO-NASS, YOLO-NASM, and YOLO-NASL architectures.
Our data-driven approach accelerated the discovery of this innovative architecture, with the entire process taking roughly 3800 GPU hours.
Reducing reliance on manual intervention and invention empowers the development of more efficient, robust, and versatile deep learning models for various applications.
AutoNAC is an efficient NAS algorithm used by Deci’s customers to automatically construct efficient deep learning models for any task and hardware.
During the NAS process, we incorporated quantization-aware RepVGG blocks into the model architecture, ensuring that our model architecture would be compatible with Post-Training Quantization (PTQ).
Training Details
YOLO-NAS’s multi-phase training process involves pre-training on Object365, COCO Pseudo-Labeled data, Knowledge Distillation (KD), and Distribution Focal Loss (DFL).
The model is pre-trained on Objects365, a comprehensive dataset with 2 million images and 365 categories, for 25-40 epochs (depending on the model variant) due to the extensive time needed for each epoch (each epoch takes 50-80 minutes on 8 NVIDIA RTX A5000 GPUs). The COCO dataset provides an additional 123k unlabeled images, which are used to generate pseudo-labelled data. An <accurate model> is trained on COCO to label these images, which are then used to train our model with the original 118k train images.
The YOLO-NAS architecture also incorporates Knowledge Distillation (KD) and Distribution Focal Loss (DFL) to enhance its training process.
Knowledge Distillation is applied by adding a KD term to the loss function, enabling the student network to mimic the logits of both classification and DFL predictions of the teacher network. DFL is employed by learning box regression as a classification task, discretizing box predictions into finite values, and predicting distributions over these values, which are then converted to final predictions through a weighted sum.
Quantization Aware Architecture
YOLO-NAS’s architecture employs quantization-aware blocks and selective quantization for optimized performance.
The model’s design features adaptive quantization, skipping quantization in specific layers based on the balance between latency/throughput improvement and accuracy loss. When converted to its INT8 quantized version, YOLO-NAS experiences a smaller precision drop (0.51, 0.65, and 0.45 points of mAP for S, M, and L variants) compared to other models that lose 1-2 mAP points during quantization. These techniques culminate in innovative architecture with superior object detection capabilities and top-notch performance.
The YOLO-NAS architecture and pre-trained weights define a new frontier in low-latency inference and an excellent starting point for fine-tuning downstream tasks.
Use Cases
Strong pre-trained weights often lead to higher model accuracy on new datasets when fine-tuning.
YOLO-NAS was trained on the RoboFlow100 dataset (RF100), a collection of 100 datasets from diverse domains, to demonstrate its ability to handle complex object detection tasks. The RF100 dataset is a benchmark for existing YOLO models, enabling us to compare YOLO-NAS’s performance against them and showcase its advantages.
We followed the RF100 repository’s training protocol to ensure a fair comparison.
The training protocol for the model includes the following settings, applied consistently across all datasets for 100 epochs on a single T4 GPU with 16GB of VRAM during training:
- Learning rate: 5e-4 for the Small version and 4e-4 for the Medium version of the model
- Weight decay: 1e-4 (excluding bias and BatchNorm layers)
- Exponential moving average (EMA) with a decay factor of 0.99
- Batch size: 16
- Image resolution: 640×640
These hyperparameters ensure a robust and consistent training process, allowing for a fair comparison of the model’s performance across different datasets.
Below are the results obtained by focusing on the “Small” and “Medium” YOLO-NAS variants.
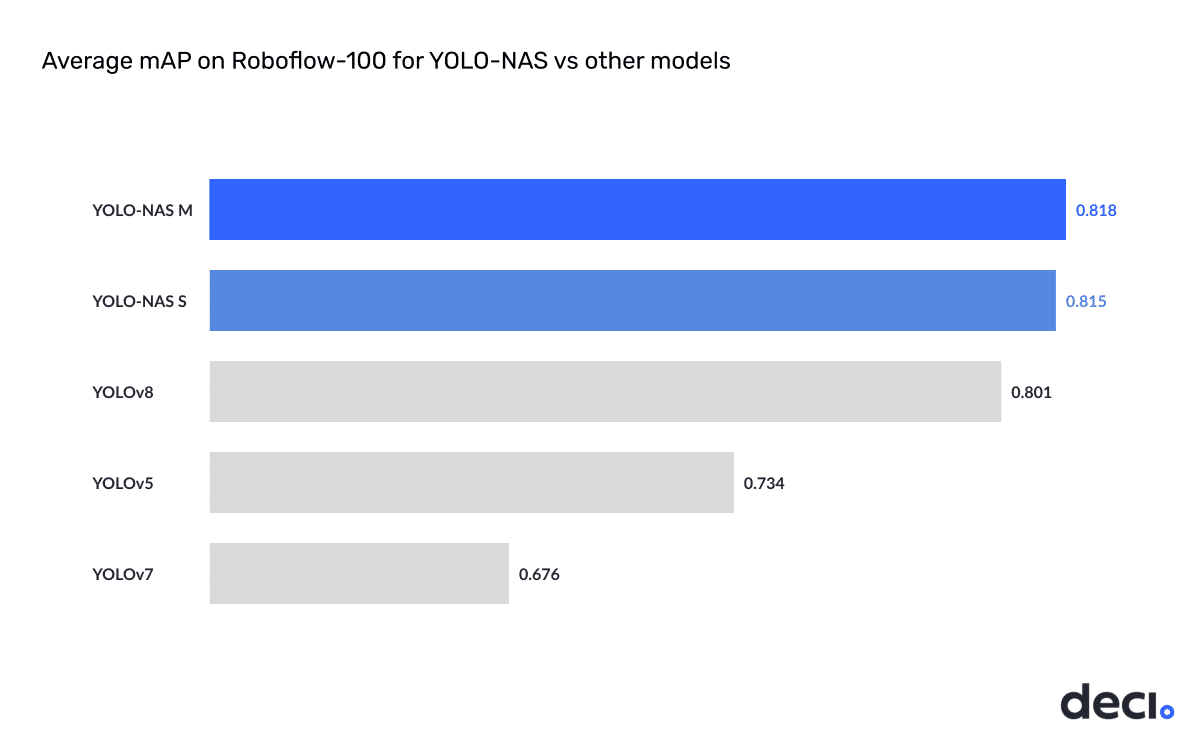
Due to the unavailability of mAP scores for some datasets for the YOLO v5/v7/v8 models, we compared YOLO-NAS’s performance only on datasets with available scores. YOLO-NAS was successfully trained on all 100 datasets without issues, providing a comprehensive comparison.
Below is a per-category breakdown of YOLO-NAS’s performance on the RF-100 dataset, compared to the performance of v5/v7/v8 models:
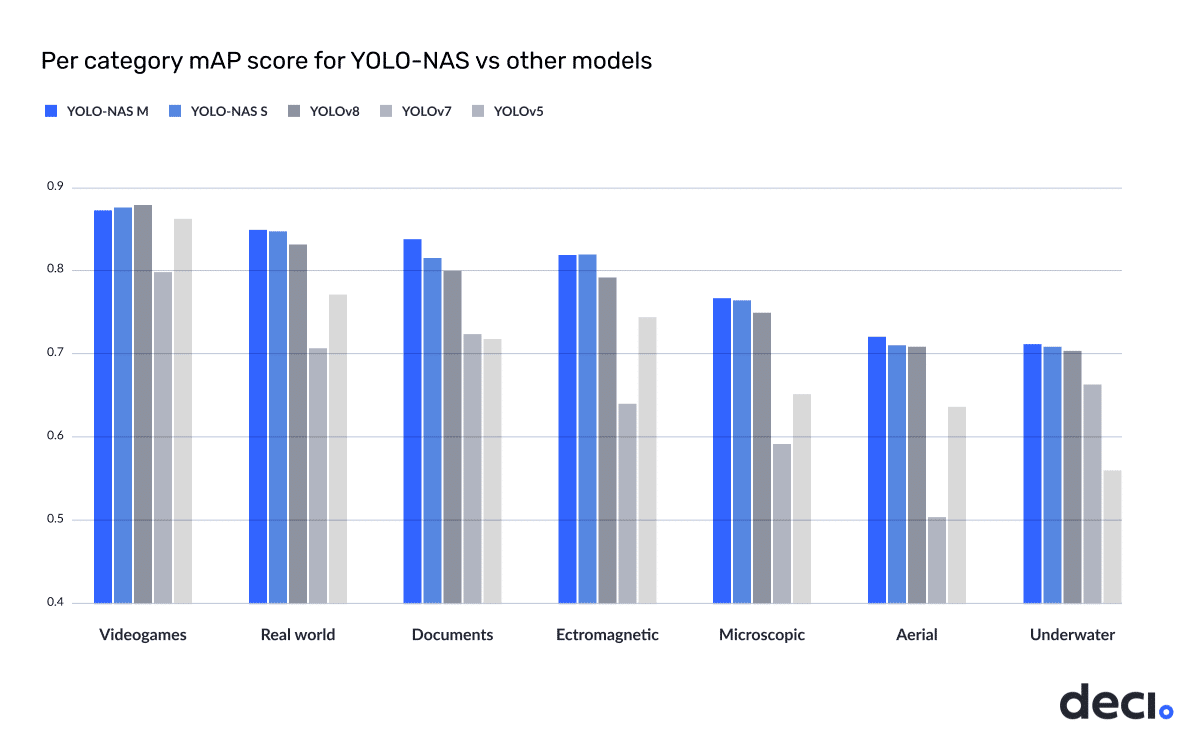
Note: For Yolo vV5/v7/v8, we used the results reported here.
To support the open-source community, we have released the capability to fine-tune YOLO-NAS models on the RF100 dataset within the SuperGradients library. This feature is available in SuperGradients version 3.10 and above, making it easier for users to leverage our models for improved performance on diverse tasks.
python -m super_gradients.train_from_recipe --config-name=roboflow_yolo_nas_s dataset_name=abdomen-mri
We also release the “Fine-Tuning YOLO-NAS Notebook” available here.
YOLO-NAS can be easily fine-tuned to achieve state-of-the-art results using Google Colab Notebook. With the help of SuperGradients, transfer learning becomes even more seamless and efficient, allowing for quick adaptation to new tasks and datasets.
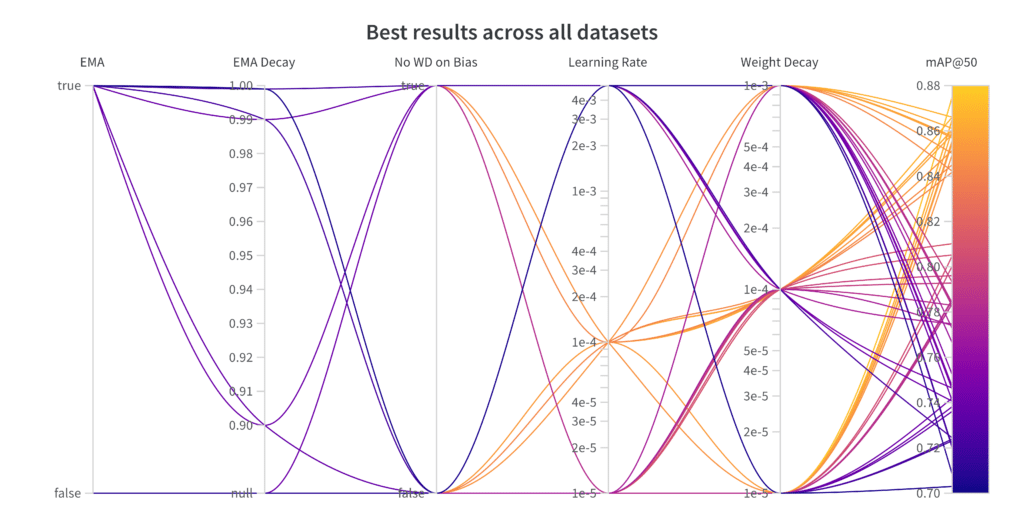
A Small Note on Used Hyperparameters
Finding the optimal hyperparameters for each dataset individually can be tedious.
To avoid overfitting hyperparameters for each dataset, we took 10 random subsets from RF100 and performed a short grid search across learning rate, weight decay, and EMA settings. Our goal was to find a set of parameters that lead to the maximum average mAP, ensuring a robust solution across different datasets. We then applied these hyperparameters to train YOLO-NAS on all datasets from RF100. We used a batch size of 16 for the Small (S) variant and 12 for the Medium (M) variant, ensuring an efficient training process tailored to each model version.
Potential Impact
The new object detection model, YOLO-NAS, developed by Deci using AutoNAC technology, has achieved state-of-the-art performance in object detection.
We hope this breakthrough inspires new research and revolutionizes the field of computer vision, enabling machines to perceive and interact with the world more intelligently and autonomously. Regarding scalability and availability, YOLO-NAS is designed with production use in mind and is fully compatible with inference engines like NVIDIATensorRT, ensuring seamless deployment. YOLO-NAS offers a practical and scalable solution for various computer vision applications.
The SuperGradients open-source training library simplifies fine-tuning the model for downstream tasks, making it accessible to a wider audience and promoting its adoption across various applications.
Conclusion
Our new object detection model has expanded the frontier in object detection.
This new model is fast and accurate, offering the best accuracy-latency tradeoff among existing object detection models on the market. This accomplishment was made possible by Deci’s AutoNAC neural architecture search technology, which efficiently constructs deep learning models for any task and hardware.
YOLO-NAS is quantization-friendly and supports TensorRT deployment, ensuring full compatibility with production use. Ultimately, this breakthrough in object detection can inspire new research and revolutionize the field, enabling machines to perceive and interact with the world more intelligently and autonomously.
We’re excited to see what you build with it!









