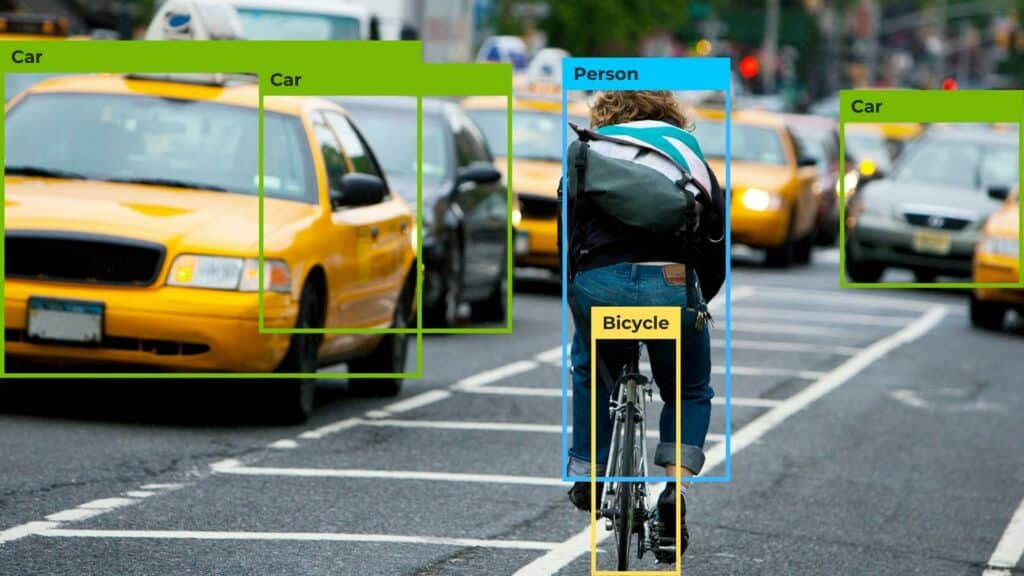
Object detection is advancing at an unprecedented rate in the world of machine learning and deep learning models. It has again reached new heights with the recent release of the YOLOv6 model (MT-YOLOv6, to be exact) by the Meituan Visual Intelligence Department.
YOLOv6 is not officially a part of the YOLO family of object detector models, but the original YOLO detector significantly inspires its implementation. It is mainly focused on delivering industrial applications.
In this blog, we’ll discuss the components of the YOLOv6 object detection model and compare it to other YOLO versions including YOLOX and YOLOv5. We’ll later discuss how you can use YOLOv6 with Deci’s deep learning development platform.
What is YOLOv6?
Mt-YOLOv6, or simply YOLOv6, is a single-stage object detection algorithm.
A single-stage object detection model performs object localization and image classification within the same network. Object localization involves identifying the position of a single object (or multiple objects) within an image frame. While object classification involves assigning labels to localized objects in an image using bounding boxes.
In comparison, a two-stage object detection model performs the two tasks using separate networks. The single-stage method is simpler and faster.
The YOLO model family performs single-stage predictions using a grid. It contains a pre-trained backbone architecture to learn feature maps of the image, a neck to aggregate those feature maps, and a head to make the final predictions. YOLOv6 uses an EfficientRep backbone with a Rep-PAN neck built similarly to the original YOLO model. Moreover, YOLOv6 uses a decoupled head.
Let’s discuss the YOLOv6 backbone, neck, and head in detail.
What’s New in YOLOv6?
In terms of YOLO architectures, YOLOv6 offers several model sizes, including YOLOv6-n (4.3M parameters), YOLOv6-tiny (15M parameters), and YOLOv6-s (17.2M parameters). Even larger sizes are expected.
The YOLOv6 backbone and neck are known for working well with GPUs, reducing hardware delays and allowing more use cases for industrial applications.
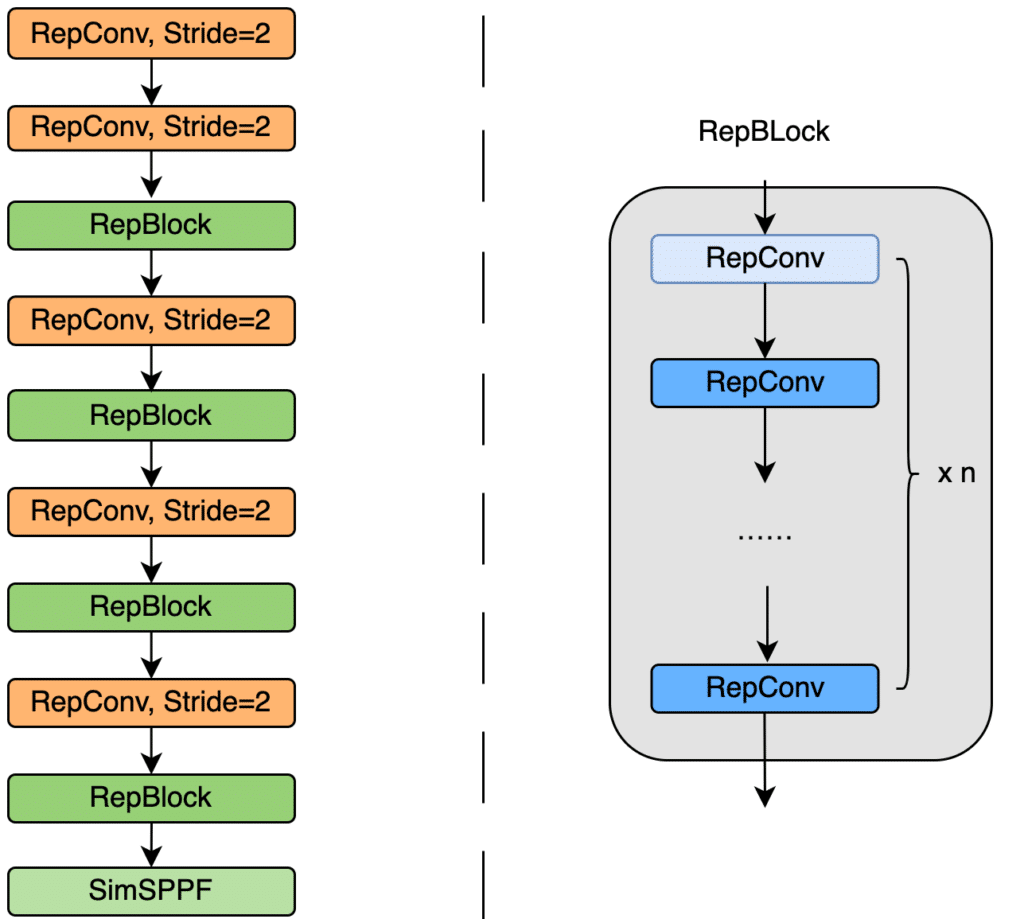
The EfficientRep backbone used in YOLOv6 favors GPU processing using the Rep operator, which allows structural reparameterization. This is a technique that restructures trained convolutional neural network layers to achieve better inference speed.
EfficientRep uses RepConv layers followed by RepBlocks, as shown in the image below. Each RepConv layer consists of various RepVGG layers, a batch normalization layer, and a ReLU activation unit.
The stride parameter determines how the convolution filter is applied to the input image. Each convolution operation shifts two pixels to reduce the output dimensions, making the detection network faster.
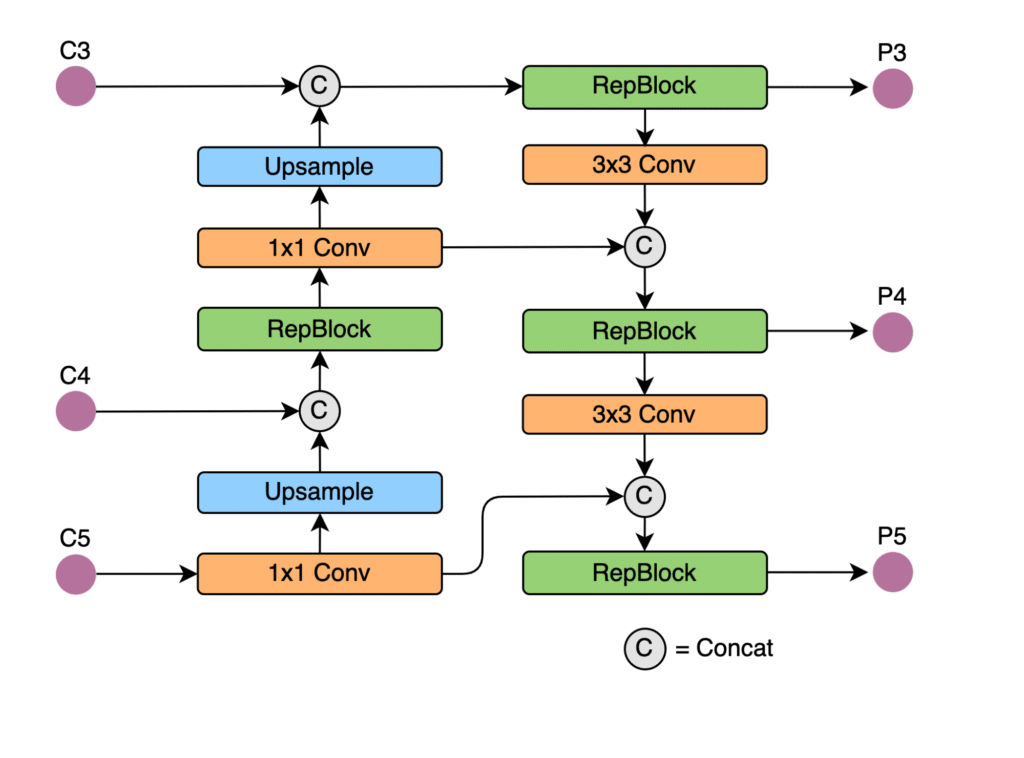
The Rep-PAN neck is based on PANet topology, which may use RepBlocks instead of CSPNet blocks. PANet topology uses path augmentation by enhancing low-level patterns to perform better object localization. The PANet structure uses concatenation and fusion to predict object class and mask. The PANet structure is shown in the image below.
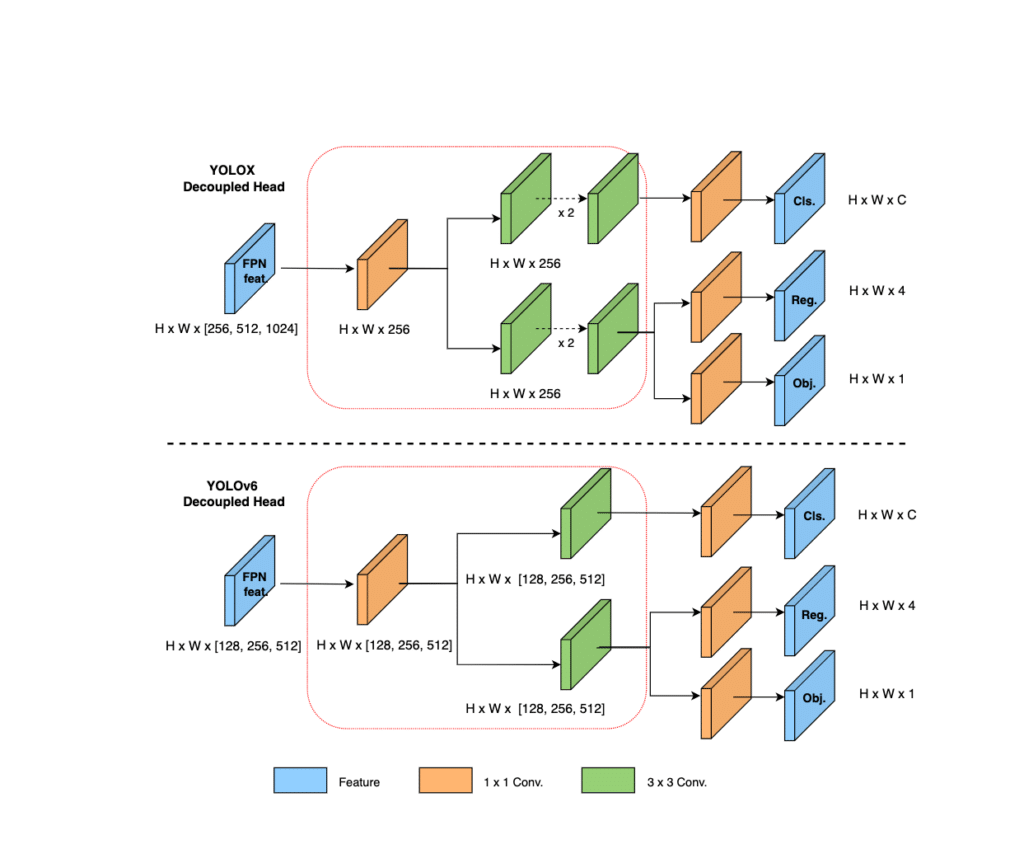
The typical decoupled head design (like in YOLO) separates the network’s classification, regression, and detection branches but adds two additional 3*3 CNN layers to improve accuracy. However, the two additional layers increase network overhead which causes delay.
On the other hand, YOLOv6 simplifies the design of the decoupling head by eliminating the need for additional CNN layers, as shown in the image below. This decoupled head can cater to 128, 256, and 512 channels, reducing the network delay by 6.8% and making the YOLOv6 head more concise and efficient.
Moreover, YOLOv6 further improves detection accuracy by using:
- An anchor-free paradigm to enhance detection speed by 51%.
- A SimOTA label assignment strategy to allocate positive samples dynamically.
- A SIoU bounding box regression loss to supervise network learning and accelerate network convergence.
YOLOv6 Benchmarks
The three available YOLOv6 variants are evaluated on the mean Average Precision (mAP) metric. This is typically used for evaluating the performance of object detection models. mAP measures the AP for each class label and averages it for the total number of classes.
Average Precision is calculated based on four metrics: precision, recall, and a precision-recall curve for each threshold. Finally, the mean Average Precision is calculated by taking the average of all AP values.
Now, let’s observe the benchmarking results of YOLOv6 variants. All models are evaluated using COCO datasets, in this case the COCO val2017 dataset. The inference speed is recorded on V100 and T4 GPUs with float-16 (FP16) quantization.
| Model Variant | mAP | Latency V100 FP16 (ms) | Latency T4 FP 16 (ms) |
| YOLOv6-nano | 35.0 mAP | 1.82 ms | 2.3 ms |
| YOLOv6-tiny | 41.3 mAP | 2.18 ms | 3.21 ms |
| YOLOv6-small | 43.1 mAP | 2.5 ms | 3.59 ms |
How Does YOLOv6 Compare With YOLOv5 or YOLOX?
Currently, YOLOv6 is the most advanced SOTA detection framework, giving better accuracy performance than YOLOv5 and YOLOX. Let’s discuss some differences between the three models.
- Average Precision – YOLOv5-small gives 37.3 mAP, YOLOX-small offers 40.5 mAP, and YOLOv6-small leads the way with 43.1 mAP on the COCO validation dataset.
- Speed – The YOLOv6-small has a latency of 3.59 ms while the YOLOv5-nano can reach 5.38.
- Backbone – YOLOv5 uses the CSPNet backbone, and YOLOX uses the similar CSPDarkNet53 backbone. YOLOv6 uses the EfficientRep backbone with arguably stronger input representation capabilities, and it can efficiently utilize GPU hardware, making the detection network stronger for industrial applications.
- Detection Head – YOLOv5 doesn’t decouple classification and regression branches. YOLOX decouples classification and regression heads but has greater network delay. In contrast, YOLOv6 simplifies the design of the decoupling head layers to reduce network delay.
- Matching – YOLOv5 uses aspect ratios of ground truth boxes and anchors to define positive samples and then center point offset to make sure each GT is assigned to more anchors. In contrast, YOLOv6 and YOLOX use SimOTA which obtains more high-quality positive samples dynamically to improve detection accuracy by 1.3% AP, compared to YOLOv5.
- Loss – YOLOv6 uses SIoU loss for their small model, and for the rest they use a simple IoU, YOLOX uses IoU loss, and YOLOv5 uses IoU loss.
| YOLOv5-small | YOLOX-small | YOLOv6-small | |
| Average Precision | 37.4 mAP | 40.5 mAP | 43.1 mAP |
| Speed | 5.38ms | 3.59ms | |
| Backbone | CSPNet | CSPDarkNet53 | EfficientRep backbone – has stronger input representation capabilities, and can efficiently utilize GPU hardware, making the detection network stronger for industrial applications |
| Inference | Fuses classification and regression branches | Decouples classification and regression heads but has greater network delay | Simplifies the design of the decoupling head layers to reduce network delay |
| Labeling | Uses the static Shape matching label assignment strategy and a cross-grid matching strategy to increase the number of positive samples | Uses SimOTA which obtains more high-quality positive samples dynamically to improve detection accuracy by 1.3% AP, compared to YOLOv5 | |
| Loss | Focal loss along and IoU loss | IoU loss | SIoU loss |
To summarize, YOLOv6 improves both speed and accuracy compared to its predecessors, YOLOv5 and YOLOX, particularly for industrial applications that leverage its hardware optimization capabilities. Compared to a YOLOV5-nano baseline, the decoupled head of YOLOv6 adds 1.1% mAP. Finally, YOLOv6-nano achieves 35% mAP and a speed of 1242.2 fps.
Now that you have a better understanding of how YOLOv6 differs from previous YOLO models. Let’s go over how to maximize your use of it with Deci’s platform.
How to Optimize YOLOv6 Inference Performance with Deci’s Deep Learning Platform
Deci is a deep learning development platform that allows you to quickly optimize inference performance of deep learning models.
The platform includes several tools that support data scientists and ML engineers across the development phases of deep learning projects.
- SuperGradients – A training library for computer vision models which simplifies the training process and wraps up many advanced training techniques with just a few lines of code.
- Automated compilation and quantization engine – A compilation and quantization tool that seamlessly optimizes inference performance of your trained models for your hardware with the click of a button.
- Hardware Benchmark Tool – A hardware benchmarking tool that helps you select the best hardware for your model and application. Upload your model and see how it performs across different parameters (throughput, latency, model size, memory footprint), various hardware types and batch sizes.
- Infery – A deployment tool that runs inference with 3 lines of code to get predictions or model benchmarking.
- AutoNAC – Deci’s proprietary Neural Architecture Search engine that enables you to build accurate & efficient architectures customized for your application, hardware and performance targets.
How to Automatically Compile and Quantize YOLOv6
Download your preferred model size from the YOLOv6 GitHub repository in ONNX format. Open your Deci account and upload the pre-trained Model. Select the object detection task and give the model an appropriate name, as shown in the image below.
Next, select the hardware that you want to run your model on and then press start. The Deci platform has an online hardware fleet that includes a wide variety of hardware types. These include K80, V100, T4, Jetson Xavier, Jetson Nano, Jetson Xavier AGX, and various Intel CPU machines.
The model will upload within a few minutes and will be available on the Deci console. Once the model is uploaded you can easily benchmark its inference performance metrics (such as throughput, latency, size, and memory footprint) on various hardware.
You can also go ahead to maximize its inference performance by using Deci’s automated compilation and quantization tool. See below, the baseline YOLOv6 model compared to the expected inference performance of YOLOv6 after being optimized for inference on the NVIDIA V100 GPU using the Deci platform.
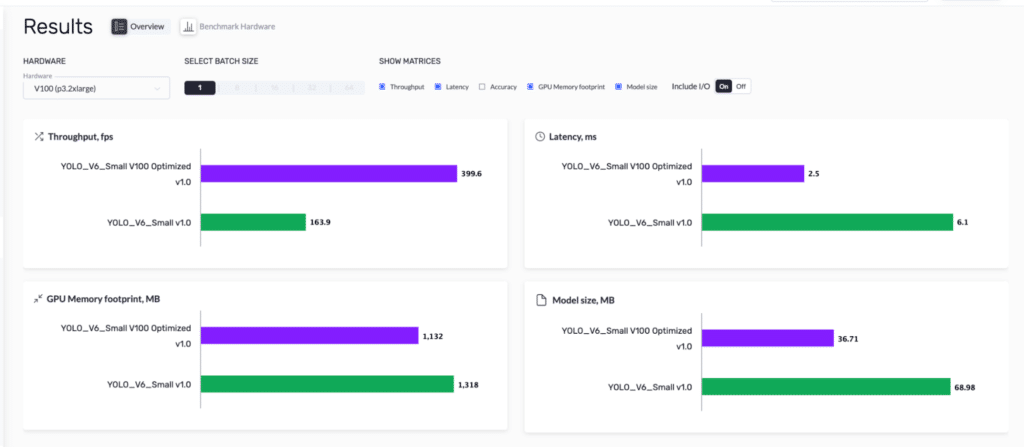
You can learn more about how Deci optimizes various YOLO models by checking out our webinar on deploying and accelerating YOLOv5 in 15 minutes.
Build Custom Model Architectures with the Deci Platform
If you are looking to gain even better accuracy or inference performance than what YOLOv6 can deliver, then consider using Neural Architecture Search.
Deci’s proprietary Neural Architecture Search engine, AutoNAC (Automated Neural Architecture Construction) empowers you to easily build accurate and fast architectures tailored for your inference hardware and performance targets. AutoNAC is the most advanced and commercially scalable NAS solution in the market.
To learn more about AutoNAC, read more about it here.









