Note: This article was co-authored by Deci and João Lages.
Methods for language model merging have gained significant traction in recent times, with merged models showcasing remarkable performance on the Open LLM Leaderboard.
Model merging is a cost-effective way to combine useful skills, usually without the need for fine-tuning. Among the array of available tools, Mergekit stands out as the current frontrunner for model merging. Although this library has many implemented merge methods, it only has one algorithm capable of integrating diverse model architectures, known as frankenmerging.
Besides that method, all the other merging algorithms in Mergkit, including SLERP, Mixture of Experts (MoE), and the various task vector algorithms, do not merge entire models outright. Instead, they operate on individual layers.
This blog offers a detailed comparison of the four model merging methods: SLERP, frankenmerging, MoE, and task vector algorithms. It explores their techniques for merging vector weight groups and outlining their advantages and disadvantages. This analysis aims to clarify each approach’s unique benefits and potential drawbacks.
Model Merging Through Task Vector Algorithms
Task vector algorithms leverage the calculated differences between base and fine-tuned models to strategically enhance performance on specific tasks.
These algorithms involve operations based on task vectors.
The concept of a task vector was first introduced in Editing Models with Task Arithmetic. A task vector is computed by subtracting the weights of a base model from the weights of a task-specific model that has been fine-tuned based on that same base model. The intuition is that this vector indicates the adjustment necessary to enhance the base model’s performance on a specific task.
Task vectors are used to merge models, following a generic 4 step approach:
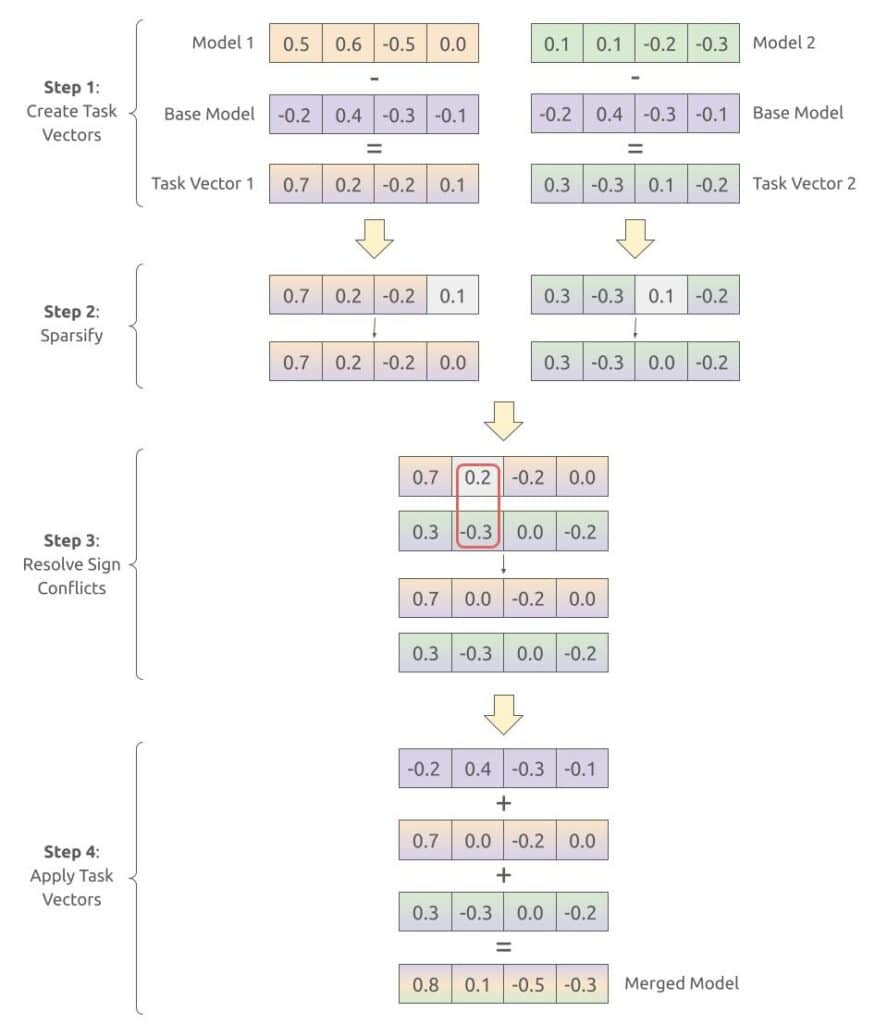
- Step 1: Calculate all the task vectors. This is done by simply subtracting the base model’s weights from the task model’s weights.
- Step 2: The goal of this step is to reduce redundancy in model weights and/or only focus on the most impactful weight changes. This is achieved by setting to zero some task vector values. The way these values are selected depends on the algorithm.
- Step 3: Compare all task vector indexes independently, and fix the ones that have a different sign (i.e., positive and negative values for that same index). The sign conflicts are solved by setting to zero some of the task vector values. The way these values are selected also depends on the algorithm.
- Step 4: Add all the resulting task vectors to the base model weights.
There are 4 main task vector algorithms in Mergekit, and they differ in how steps 2 and 3 are performed:

- Task Arithmetic only uses the task vectors, skipping steps 2 and 3.
- TIES improves this by focusing only on the values with the highest absolute value (magnitude), and setting to zero the smaller ones in step 2. The number of values to drop is configurable. Also, in step 3, the sign conflicts are solved by keeping the values whose sign belongs to the group with the highest magnitude.
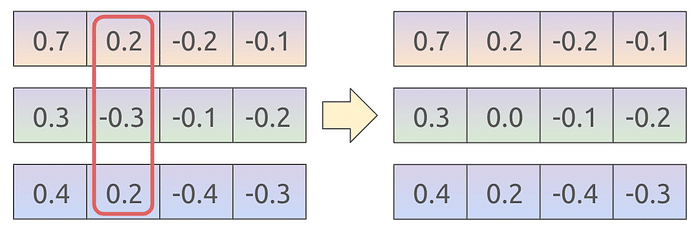
- DARE randomly drops some task vector values in step 2, in order to reduce redundancy.
- DARE + TIES combines step 2 of the DARE method with step 3 of the TIES method.
These merge algorithms require a base model to be specified but can merge multiple models at once. Also, there are some configurable parameters such as the weight given to each task vector, and the number of values to be dropped in step 2.
The table below outlines the advantages and disadvantages of the four task vector algorithms, providing a concise comparison.
| Method | What It Is | Pros | Cons |
| Task Arithmetic | Directly adds task-specific weight differences to a base model. | Simple and straightforward.Requires no additional parameter tuning. | Less nuanced; may not fully capture complex model improvements. No redundancy handling. |
| TIES | Focuses on significant weight changes by magnitude, ignoring smaller ones. | Reduces model complexity by focusing on impactful changes.Addresses redundancy to some extent. | Potentially overlooks subtle but important adjustments.Requires choosing which changes to ignore. |
| DARE | Randomly drops weight changes to reduce redundancy. | Introduces randomness to prevent overfitting.Simplifies the model by reducing weight count. | Randomness can lead to loss of critical information. Less predictable outcomes. |
| DARE + TIES | Combines the magnitude focus of TIES with the randomness of DARE. | Balances significant change focus with randomness to enhance model performance.Aims to capture the best of both methods. | Complexity increases with combining methods. Requires careful tuning of parameters. |
Model Merging Through SLERP
SLERP, or Spherical Linear Interpolation, smoothly blends two models by navigating the shortest path on a high-dimensional sphere. It can be applied to only 2 models at a time.
Imagining we are merging two weight vectors with two positions only, we can plot these vectors in a 2D plane and better visualize the performed steps:
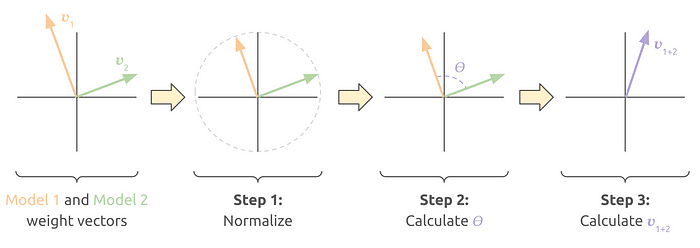
- Step 1: Normalize the vectors to have the same size.
- Step 2: Calculate the angle 𝛳 (in radians) between the two vectors.
- Step 3: Calculate 𝒗₁₊₂ according to the formula below, where 𝑡 is a parameter to give higher weight to Model 1 or Model 2. t=o means only Model 1 is used, while t=1 means only Model 2 is used.
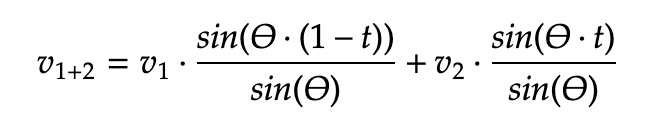
SLERP improves on standard weight averaging by maintaining each model’s unique characteristics and curvature, even in intricate, high-dimensional spaces.
Frankenmerging
Frankenmerging, as the name suggests, is the process of merging different models by mixing pieces of them together.
Currently, this is the only method in Mergekit that works for different model architectures. This is because it doesn’t fuse different layers into a single one as other methods do, and instead just stacks different layers sequentially.
Here’s an example of a frankenmerging configuration in Mergekit:
slices:
- sources:
- model: psmathur/orca_mini_v3_13b
layer_range: [0, 24]
- sources:
- model: garage-bAInd/Platypus2-13B
layer_range: [20, 40]
merge_method: passthrough
dtype: float16
This will produce a model that has the first 24 layers of psmathur/orca_mini_v3_13b, and layers 20–40 of garage-bAInd/Platypus2–13B on top.
That’s it. This method takes a lot of trial and error, but has produced a few interesting models like Goliath and Solar-10.7B.
Model Merging Through Mixture of Experts (MoE)
Mixture of Experts, an innovative architectural paradigm, has gained a lot of attention, especially through its implementation in Mixtral, demonstrating its ability to blend expertise for better performance. The technique utilizes a smart routing mechanism to direct input data to the most relevant specialized parts, or ‘experts’, within a model, ensuring optimal performance by drawing on the unique strengths of each expert.
In this architecture, traditional feedforward layers are substituted with MoE layers, which consist of a cluster of feedforward layers known as “experts” and a single router, also referred to as the “gate.”
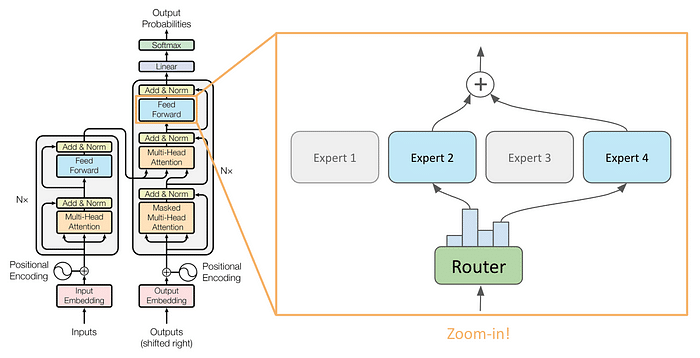
For each token, every MoE layer selectively employs N experts (N=2 in the image above), determined by its router. Typically, this router is a single linear layer with an output size matching the number of experts, followed by a softmax activation.
The N experts with the highest probabilities are subsequently chosen to compute the new hidden states. Finally, a weighted average based on these probabilities is computed to derive the final hidden state vector.
MoE layers are employed in model merging in the following manner: each model functions as an expert.
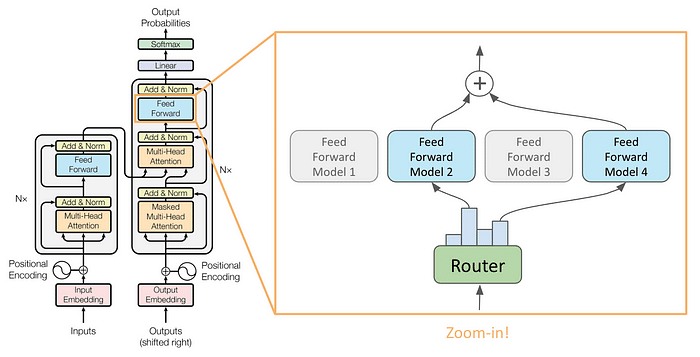
Note that there are other weights in the transformer architecture (e.g., in attention layers), so a base model needs to be specified. Consequently, this algorithm exclusively merges the weights within the feedforward layers of the models, leaving others intact.
Regarding the initialization of router weights, besides random weight initialization, Mergekit provides alternative options based on supplied positive and negative prompts for each expert. However, it is advisable to fine-tune the entire model post-merging for optimal performance.
Fun fact: A model merged through this method is commonly referred to as moerge (as a short version for MoE-merge 😄).
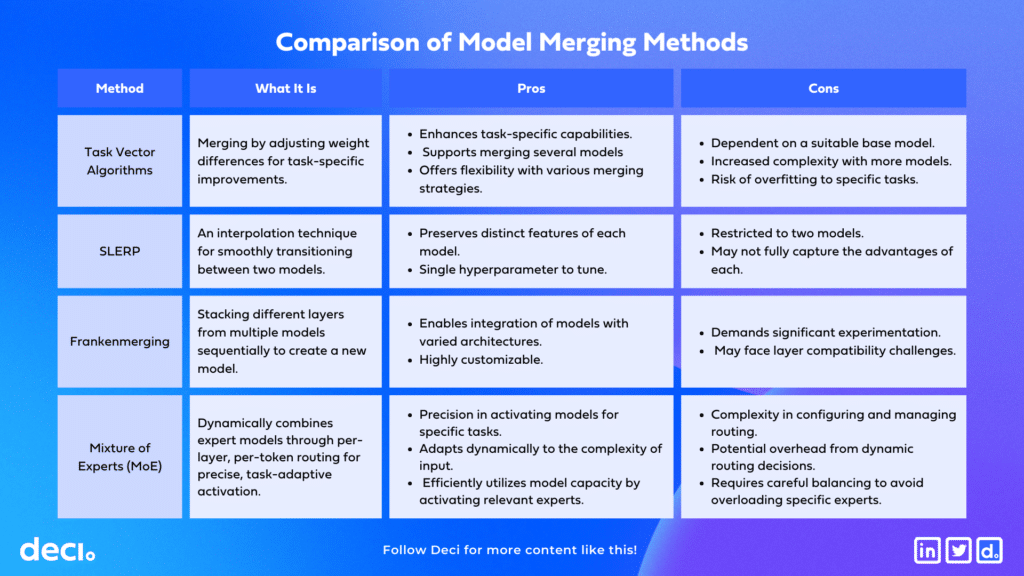
Model Merging Method Comparison
The following table outlines the key characteristics of each model merging approach, including their advantages and limitations.
Quality Assessment of Merged Models
Many merged models became popular by quickly climbing to the top spots on the Open LLM Leaderboard.
However, some of these models have been flagged for data contamination. If any of the merged models were trained using data from the leaderboard’s evaluation set, it’s considered contamination. This problem is harder to track as the models being merged are themselves combinations of multiple models. As a result, the leaderboard no longer displays merged models by default.
Here are some interesting successful merges:
- NeuralBeagle14–7B: a SLERP merge of 2 Mistral-based models, that is then further fine-tuned using DPO, leading to better score on the leaderboard.
- blockchainlabs_7B_merged_test2_4: another SLERP merge between 2 merge models (one of them being NeuralBeagle14–7B), with a 75.28 score.
- Beyonder-4x7B-v2: a MoE merge between 4 different models, resulting in a 72.33 score.
Conclusion
Model merging holds significant promise for advancing natural language processing. Experimentation and parameter tuning remain crucial for determining the most effective merging techniques for specific tasks and scenarios.
The underlying reasons for the effectiveness of these methods are still an active area of research. We highly recommend checking out this Reddit post, which features many insightful discussions on this topic.
We also encourage you to discover Deci’s LLMS and GenAI Development Platform, designed to enable developers to deploy and scale high-performing models efficiently, with the added benefit of keeping their data on-premises.