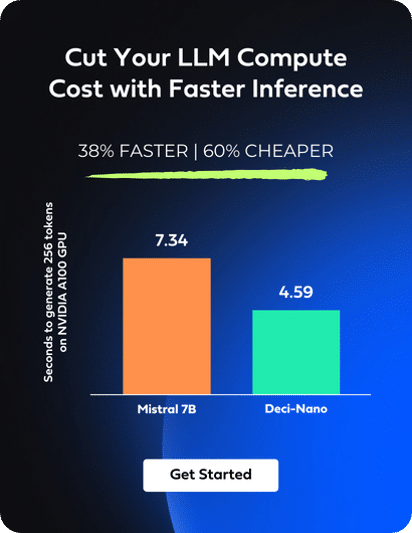
Introduction
As AI engineers working with language models, we often find ourselves at the mercy of the model’s whims, especially when it outputs results far from what we anticipated. However, with a deeper understanding of decoding strategies, we can wield greater control over these models, steering their outputs more effectively.
This blog is about unlocking that control. We’ll first revisit the text generation process, pinpointing exactly where decoding strategies make their impact. Following that, we’ll dive into various decoding strategies, such as greedy search, top-k and top-p sampling, multinomial search, beam search, and contrastive search. For each strategy, we’ll detail its advantages and disadvantages. Our goal is to enhance your ability to align the model’s output with your specific goals, whether you’re aiming to create more engaging content, generate accurate responses, or simply explore the linguistic capabilities of AI.
Brief Overview of How Language Models Generate Text
Let’s start with a quick overview of how language models generate text. If you’re already familiar with this process, feel free to jump ahead to the Decoding Strategies section.
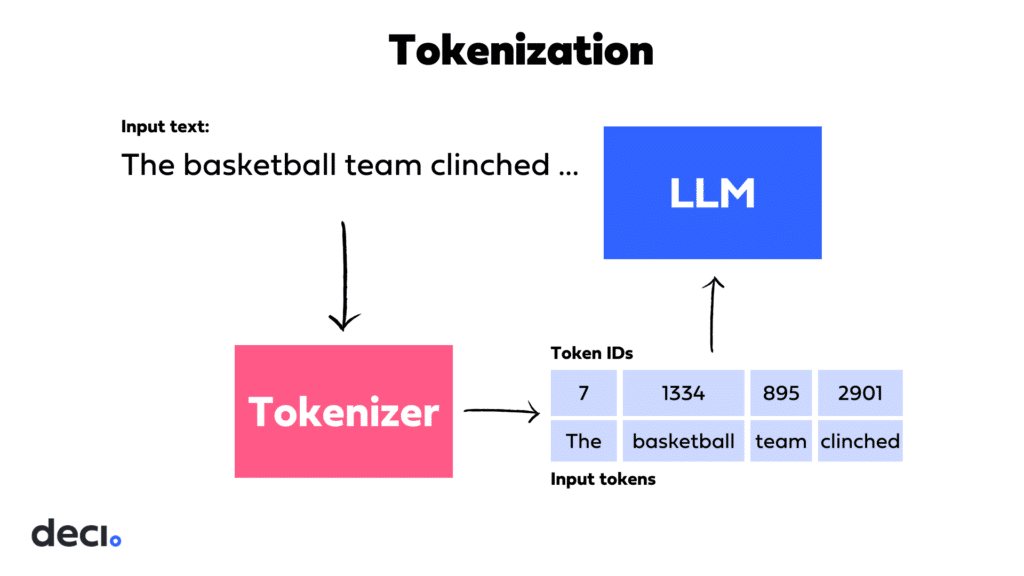
Language models generate text by predicting the next token in a sequence based on the input context. This process starts with breaking down the input text into manageable chunks, or tokens.
Tokenization
Tokens can be as small as individual characters or as large as entire words or phrases. The choice of token size often depends on the model’s design and the granularity of the language it aims to capture. For instance, word-level tokenization splits text into whole words, while subword tokenization breaks words down into smaller units, capturing prefixes, roots, and suffixes. Subword tokenization thereby balances the vocabulary size and the ability to handle unknown words.
Each token is then represented by an integer, mapping it to a unique identifier in the model’s vocabulary. This vocabulary is a pre-defined list that includes all the unique tokens the model recognizes. It’s like a language dictionary, enabling the model to process and understand the input text. For example, “beyond” might be assigned the integer 1234, while the subword “be” might be assigned 5678.
Processing and Predicting Text
After tokenization, the numerical representations of tokens are processed by the model, which includes layers of neural networks and, in the case of Transformers, self-attention mechanisms. These elements work together to determine the likelihood of the next token in the sequence. The intricacies of this transformation process are beyond the scope of this discussion. Instead, we’ll focus on the subsequent steps.
In the final layer of the model the transformed representations of the input sequence are projected onto a logit vector. This vector’s size corresponds to the size of the model’s vocabulary. Each entry in the logit vector represents an unnormalized score for each token in the vocabulary, indicating the model’s assessment of how likely each token is to be the next in the sequence. However, these logits do not sum up to one and are not directly interpretable as probabilities.
Softmax
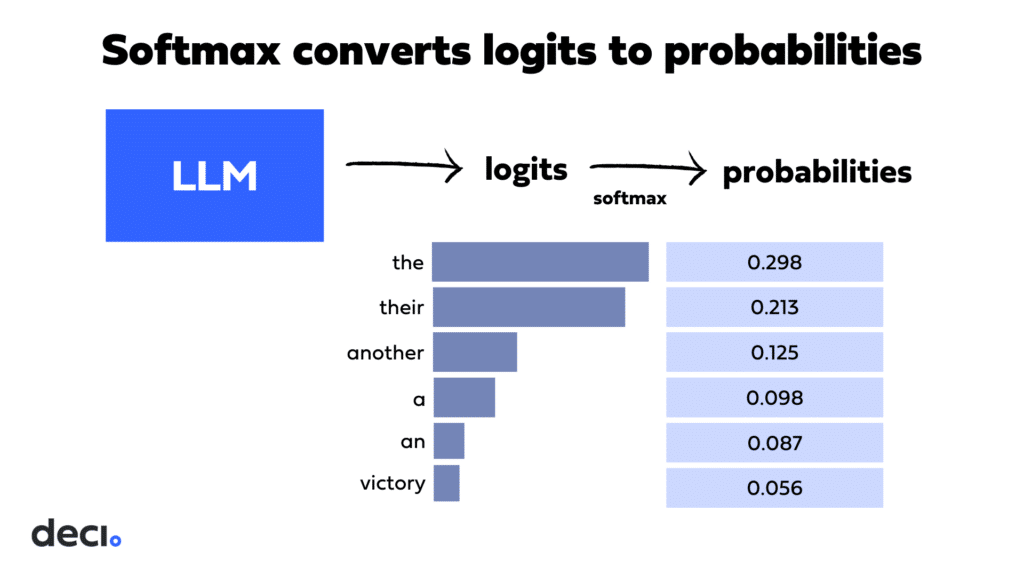
The softmax function converts logits into probabilities. It scales the logits so that their values fall between 0 and 1. The values sum up to 1, creating a probability distribution across all possible next tokens in the vocabulary.
For example, if the current sequence is “The basketball team clinched” the model might predict that the next token could be “the” with a probability of 0.298, “their” with 0.213, “another” with 0.125, and so on.
Now we are left with a tensor containing the probability of each token in the vocabulary occurring next.
Decoding
The next step involves selecting the next token based on these probabilities, which is where decoding strategies come into play. These strategies determine how the model chooses the next token, from simply picking the most probable token to more complex sampling methods that introduce randomness or consider multiple top candidates.
The chosen token is appended to the existing sequence, and this updated sequence is then fed back into the model as the new input. This process repeats iteratively, with the model taking the extended sequence, processing it through its layers as described earlier, and producing a new set of logits and probabilities for the subsequent token. This cycle continues until a stopping condition is met, such as reaching a maximum sequence length or generating a special token that signifies the end of the text.
Decoding Strategies
Decoding strategies dictate how a language model selects the next token in a sequence after predicting probabilities for all possible tokens. These strategies significantly impact the quality and variety of the generated text. There are two main types of decoding strategies: deterministic and stochastic.
- Deterministic strategies choose the most probable next token at each step, ensuring predictability but often at the expense of diversity.
- Stochastic strategies introduce randomness into the selection process, aiming for more varied and creative outputs but with less predictability.
The choice of decoding strategy is crucial, as it affects the model’s ability to generate coherent, engaging, and contextually appropriate text. The following sections will explore specific strategies, highlighting their applications, benefits, and drawbacks.
Decoding Strategy Cheat Sheet
| Decoding Strategy | What It Is | Deterministic or Stochastic | Advantages | Disadvantages |
| Greedy Decoding | Always picks the most probable next token. | Deterministic | Efficient; Fast. | Can be repetitive; Predictable. |
| Multinomial Sampling | Selects the next token based on probability distribution. | Stochastic | Promotes diversity; Encourages creativity. | Can produce irrelevant outputs; Unpredictable. |
| Top-k Sampling | Narrows choices to top-k tokens, then samples based on probability. | Stochastic | Balances predictability and diversity. | Risk of repetition; Finding optimal k can be challenging. |
| Top-p (Nucleus) Sampling | Chooses from a subset of tokens whose combined probability reaches or exceeds a threshold p | Stochastic | Reduces randomness; Focuses on plausible outputs. | Complexity in choosing p; May exclude relevant but less probable tokens. |
| Beam Search | Explores multiple high-probability paths simultaneously. | Deterministic | Produces coherent text; Reduces nonsensical outputs. | Computationally intensive; Slower generation times. |
| Beam Search with Multinomial Sampling | Combines beam and multinomial sampling for token selection within beams. | Stochastic | Coherent yet creative outputs; Enhances diversity. | Increased complexity; Slower and resource-intensive. |
| Contrastive Search | Maximizes differences between top candidate sequences. | Deterministic | Boosts diversity; Reduces redundancy. | Higher processing demands; May affect predictability/coherence. |
You can download a PDF version of the cheat sheet here.
Greedy Decoding
Greedy decoding is the simplest strategy for choosing the next token in a sequence generated by a language model. At each step, it selects the token with the highest probability as predicted by the model.
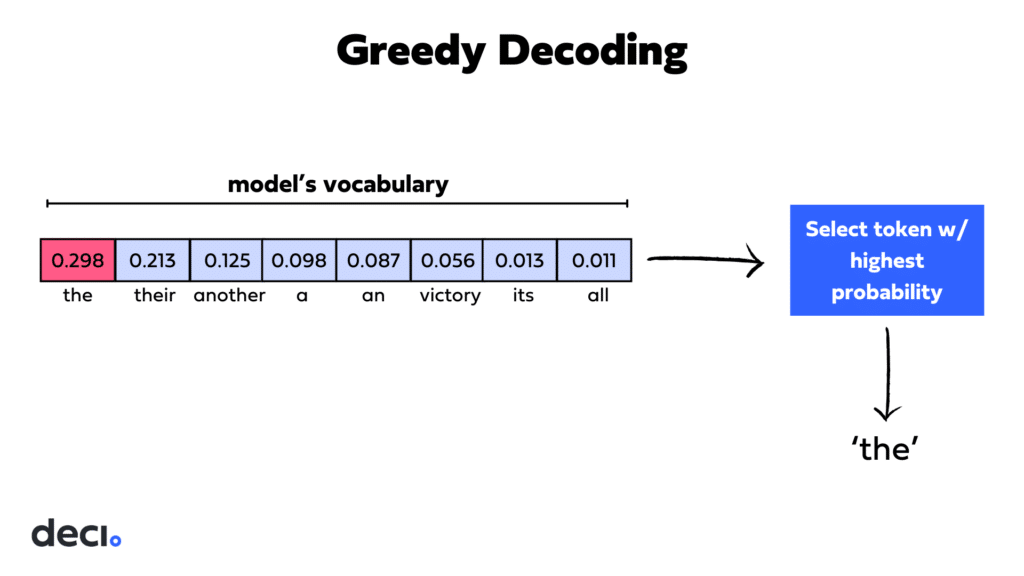
Advantages of greedy decoding:
- Efficiency: Greedy decoding is straightforward and fast, ideal for speed-critical applications.
Disadvantages of greedy decoding:
- Repetitiveness: Tends to produce repetitive and predictable text.
- Lack of Creativity: Always chooses the most probable next token without considering broader context or alternatives, potentially reducing text quality and diversity.
Temperature Adjustment
Before exploring more complex sampling strategies, it’s important to understand the role of temperature adjustment in the text generation process. Temperature is a hyperparameter that modifies the output probabilities produced by the softmax function, affecting the selection of the next token.
How Temperature Impacts the Softmax Function
Each logit corresponds to a potential next token, and the softmax function’s job is to convert these logits into probabilities that sum up to 1. The formula for the softmax function applied to a logit zi for the ith token in a vocabulary of size V is as follows:
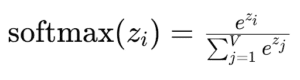
This ensures that each token’s probability is a positive number between 0 and 1, with the entire distribution summing up to 1.
Temperature (T) adjusts the softmax function by dividing each logit by T before applying the softmax:
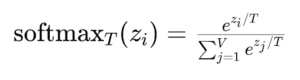
Inspired by Cameron Wolfe’s illustration of how temperature impacts probabilities
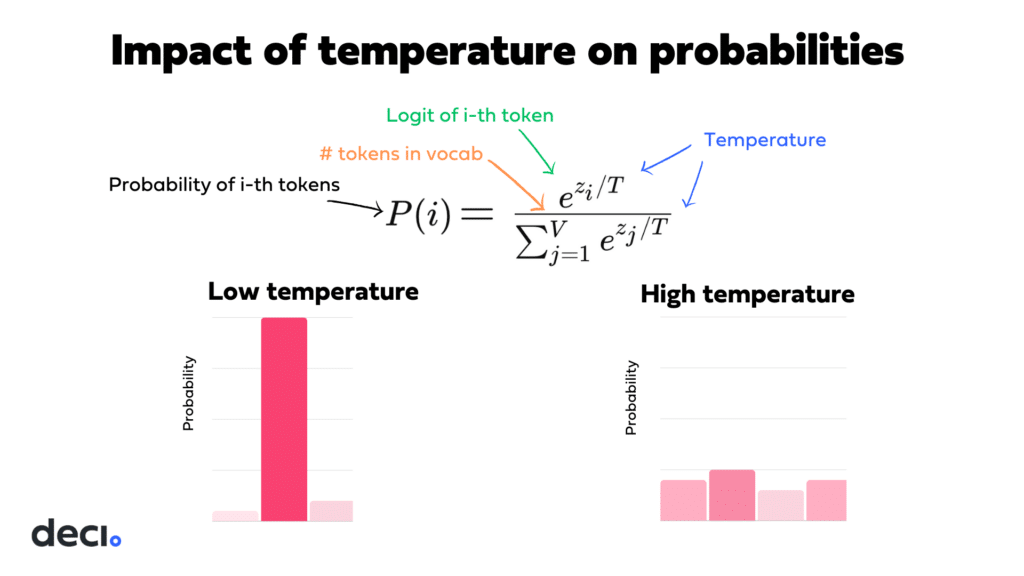
Temperature’s impact on the probability distribution
- High Temperature (When T>1): The effect of dividing by a temperature greater than 1 is to make the logits closer to each other before the softmax operation. This “flattening” of the distribution means that differences between logits are less pronounced, leading to a more uniform distribution where less likely tokens gain a higher chance of being selected.
- Low Temperature (When T<1): Conversely, dividing by a temperature less than 1 amplifies the differences between logits, making the distribution “sharper.” This results in a higher probability for more likely tokens and significantly lowers the chances for less likely tokens.
- When T=1: The softmax function operates normally without modifying any of the logits.
This is why adjusting temperature allows for tuning the balance between randomness and determinism in text generation. It directly impacts decoding strategies, affecting text diversity and novelty.
Multinomial Sampling
Multinomial (or random) sampling introduces variability into the text generation process by selecting the next token based on its probability. Unlike greedy decoding, which always picks the most probable token, random sampling allows for a broader exploration of potential continuations by drawing from the probability distribution of all tokens.
The role of temperature adjustment here is crucial; it alters the shape of the probability distribution from which tokens are sampled. A higher temperature flattens the distribution and gives lower-probability tokens a better chance of being selected. Conversely, a lower temperature sharpens the distribution, favoring higher probability tokens.
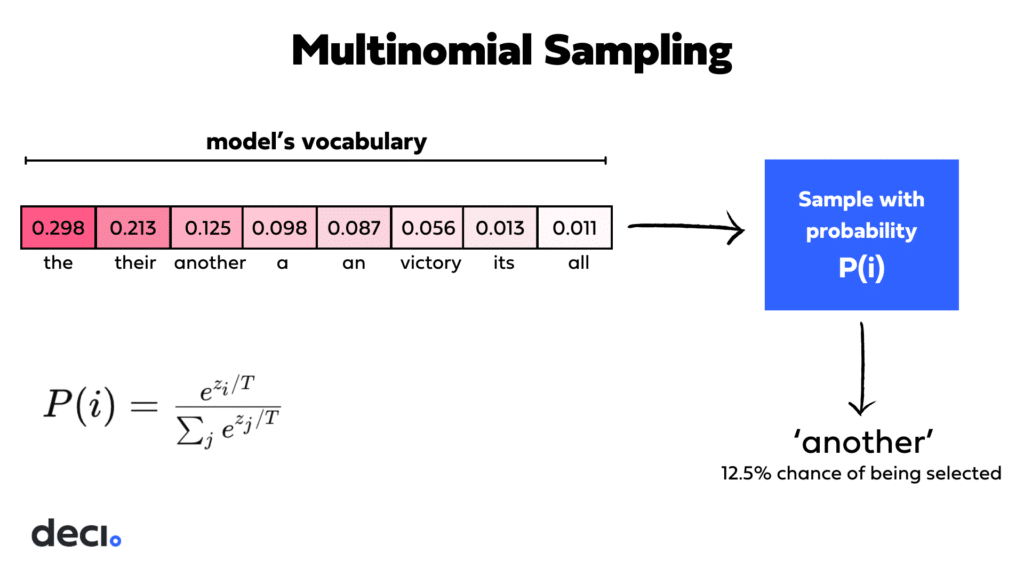
Advantages of multinomial sampling:
- Enhanced Creativity: Utilizes the entire probability distribution, allowing for the generation of more unique and varied text.
- Customizable Randomness: The ability to adjust temperature provides control over the level of randomness versus predictability in the output.
Disadvantages of multinomial sampling:
- Risk of Incoherence: Higher randomness can lead to less relevant or incoherent generations, particularly with higher temperature settings.
- Optimization Challenge: Identifying the ideal temperature setting requires trial and error, as extremes can produce overly erratic or mundane results.
Top-k Sampling
Top-k sampling refines the selection process by limiting the pool of potential next tokens to the top-k most likely candidates. Among these top-k tokens, the next token is chosen based on its probability, maintaining a degree of randomness while focusing on more likely options.
By adjusting the k value, you can directly influence the model’s selection process. A lower k value restricts the model to a smaller set of highly probable tokens, making the text generation more predictable and coherent. Conversely, a higher k value allows for more diversity by considering a broader array of tokens, which can introduce creativity but may also result in less predictable outputs.
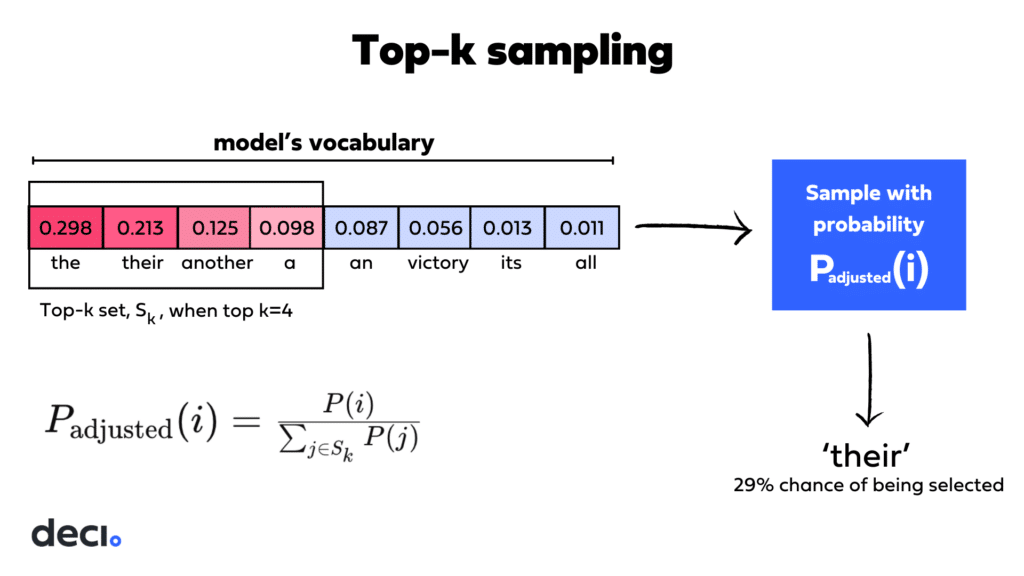
So, setting top-k to the full vocabulary count gives every token a shot at being selected. Setting top-k to 1 means the token with the highest probability gets selected, and we’re back to greedy search.
Advantages of top-k sampling:
- Balance: Offers a middle ground between predictability and diversity, enhancing text quality by focusing on plausible continuations without sacrificing variety.
- Reduced Risk of Irrelevant Outputs: Limiting selections to top candidates decreases the chances of generating nonsensical or irrelevant text compared to pure random sampling.
Disadvantages of top-k sampling:
- Potential for Repetition: While less likely than with greedy decoding, there’s still a chance of repetitiveness if the top-k set frequently includes similar tokens.
- Choice of k: Determining the optimal value of k requires experimentation, as too small a k may lead toward predictability, while too large a k can reintroduce excessive randomness.
Top-p Sampling
In top-p sampling or nucleus sampling, the selection pool for the next token is determined by the cumulative probability of the most probable tokens. When you set a threshold p, the model includes just enough of the most probable tokens so that their combined probability reaches or exceeds this threshold.
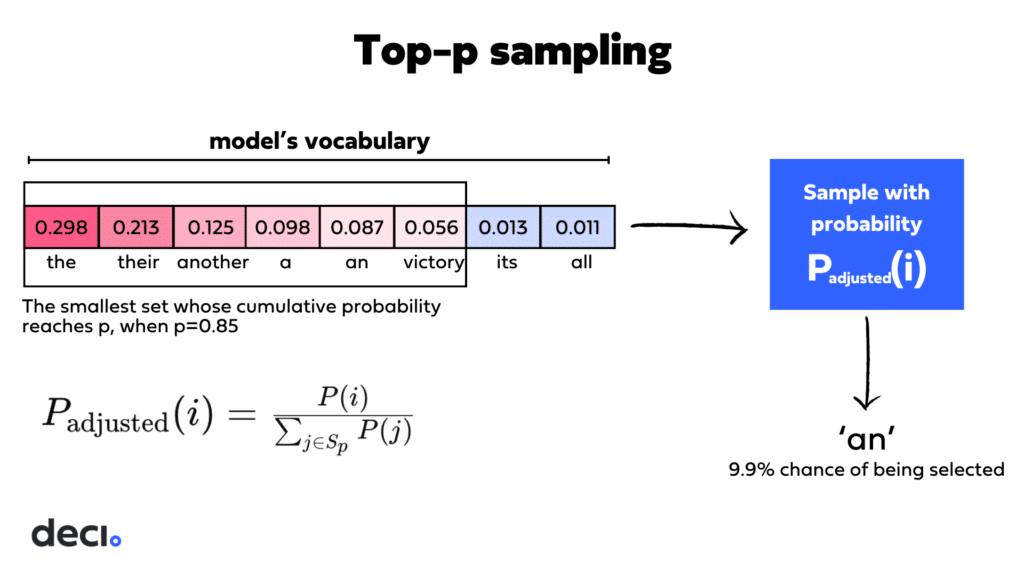
- Lowering the p Threshold: When you lower the p threshold, you’re effectively making the selection pool more exclusive. Only the most probable tokens whose cumulative probability reaches the lower threshold are considered. This generally leads to a more predictable output because it concentrates on a smaller set of highly probable tokens.
- Raising the p Threshold: Conversely, increasing the p threshold allows more tokens to be included in the selection pool because more tokens are needed to reach the higher cumulative probability threshold. This results in greater diversity in the output since it incorporates a wider array of less probable tokens.
Tokens from the top-p subset are selected according to their probabilities, not randomly. After the model determines the subset of tokens whose cumulative probability exceeds the threshold p, it samples from this subset based on the re-normalized probabilities of the tokens within it.
Advantages of top-p sampling:
- Dynamic Selection: Unlike top-k, top-p sampling dynamically adjusts the number of tokens considered at each step based on their cumulative probability, allowing for more flexibility and context sensitivity in the selection process.
- High-Quality Outputs: By focusing on a nucleus of probable tokens, it tends to generate diverse and coherent text, often producing higher quality outputs compared to other methods.
- Reduction of Extremely Unlikely Tokens: Effectively filters out the long tail of low-probability options, reducing the chances of generating irrelevant or nonsensical text.
Disadvantages of top-p sampling:
- Balance Between Diversity and Coherence: While it aims to balance diversity and coherence, finding the right threshold (p-value) requires careful tuning to avoid overly conservative or overly random outputs.
How Temperature, Top-k, and Top-p Interact
When using temperature with top-k or top-p, the softmax operation (which is influenced by temperature) is applied first to adjust the probabilities. Top-k and top-p then work within this adjusted distribution to select the next token. The sampling methods are applied in the following order:
Top-k narrows down the choices to the k most likely tokens within the temperature-adjusted distribution. This means that only the k most likely next tokens (according to the temperature-scaled distribution) are considered for sampling
Top-p refines this selection by including only those tokens within the top-k set whose cumulative probability exceeds the threshold p from the temperature-scaled and top-k filtered distribution.
Beam Search
Beam search works by preserving a predetermined number of potential sequences, known as “beams.” It systematically expands these sequences at each step by exploring all possible next tokens and assessing the probabilities of the resultant sequences. The sequences with the highest cumulative probabilities are retained for further expansion in subsequent rounds. This iterative process repeats until the sequences either hit a maximum length or produce an end token. Ultimately, the sequence with the highest total probability from the set of beams is chosen as the final output.
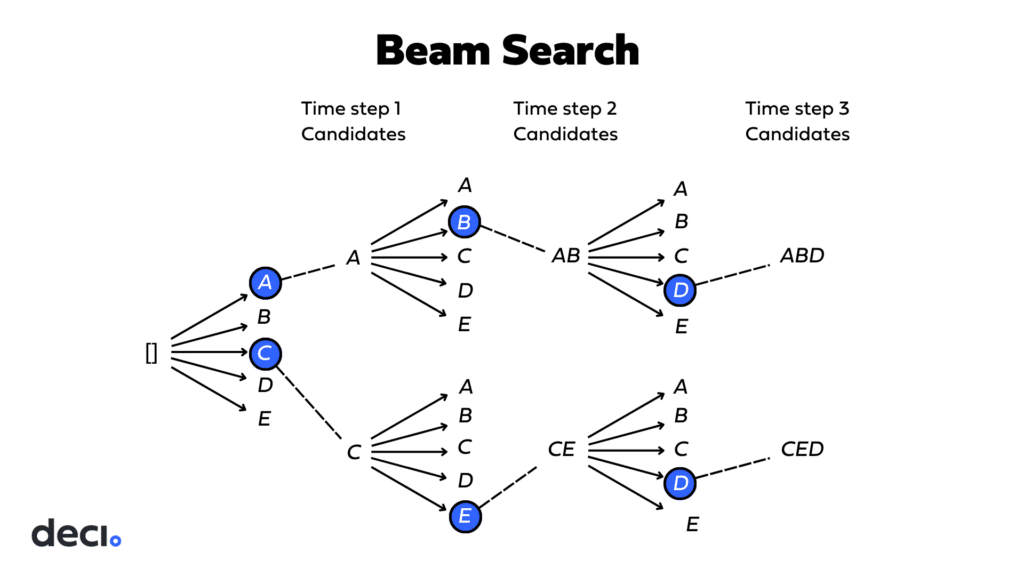
Beam search is enabled when you specify a value for num_beams that is greater than 1.
Advantages of beam search
- Higher Quality and Coherence: By exploring and retaining multiple high-probability sequences simultaneously, beam search is more likely to produce coherent and contextually appropriate text, reducing the chances of nonsensical outputs.
Disadvantages of beam search
- Increased Computational Complexity: Beam search evaluates multiple sequence paths simultaneously, increasing the demand for computational resources compared to simpler methods like greedy decoding.
- Slower Generation Times: The method’s complexity leads to slower text generation, making it less suitable for applications where response time is critical.
- Resource Intensive: The need to track and evaluate several paths simultaneously can limit its practicality in resource-constrained environments or real-time applications.
Beam Search with Multinomial Sampling
In this method, while beam search keeps a set of most likely sequences, multinomial sampling is used to randomly select the next token within each beam based on its probability distribution.
Advantages of beam search with multinomial sampling:
- Coherent and Creative Outputs: By balancing the systematic approach of beam search with the randomness of multinomial sampling, this method produces text that is both coherent and varied.
- Enhanced Diversity: Multinomial sampling within the beams increases the diversity of the generated text, making the outputs less predictable and more interesting.
Disadvantages of beam search with multinomial sampling:
- Increased Computational Complexity: The combination of maintaining multiple beams and randomly sampling within them adds significant computational overhead.
- Slower Generation Speed: This method’s complexity can slow down text generation, posing challenges for time-sensitive applications.
- Resource Intensive: Requires more careful management of computational resources, potentially limiting its use in environments with strict resource constraints.
Contrastive Search
Everything we’ve discussed so far can fall into two categories:
- Deterministic methods (greedy search and beam search), where the next token is selected simply by choosing the one with the highest probability. This may lead to model degradation, where the generated text is unnatural and contains repetitions.
- Stochastic Methods (multinomial sampling, top-k, top-p). These often result in outputs that lack coherence and can sometimes be too random or divergent from the intended context
Contrastive search tries to balance the issues of deterministic and stochastic methods by introducing a degeneration penalty.
The degeneration penalty discourages the selection of tokens that would lead to repetitive or degenerate text, effectively penalizing tokens that are too similar to what has already been generated. This is achieved by calculating the maximum cosine similarity between the token representation of the candidate token and that of all tokens in the context.
Advantages of contrastive search
- Boosted Diversity: Enhances the variety of generated text by penalizing similar token selections, encouraging exploration across a broader range of outputs.
- Reduced Redundancy: Actively works against the generation of repetitive phrases, leading to more engaging and varied content.
Disadvantages of contrastive search
- Increased Processing Demands: The necessity for similarity assessments to penalize redundant tokens escalates computational requirements.
- Potential for Less Predictability and Coherence: The method’s focus on maximizing diversity might result in outputs that are “interesting” but occasionally stray from predictability or coherence, as it prioritizes novelty over consistency.
Application-Specific Recommendations and Considerations
So, how can these approaches be tailored to specific applications?
The choice of decoding strategy significantly impacts the output’s quality, diversity, and relevance, so experimentation with temperature settings and strategies is essential for optimal performance across different use cases:
- Conversational AI: For chatbots and virtual assistants, a balance between predictability and diversity is key. Top-k or top-p sampling can provide coherent yet varied responses, enhancing user engagement without straying into incoherence. Beam search might be employed for more complex queries where accuracy is paramount.
- Creative Writing: Projects that generate poetry, stories, or other creative texts benefit from higher diversity to spark originality. Multinomial sampling or beam search with multinomial sampling can introduce the necessary creativity, with temperature adjustments used to fine-tune the novelty of outputs.
- Technical Content Generation: In tasks requiring high accuracy and relevance, such as generating technical reports or documentation, a more deterministic approach like greedy decoding or beam search could be preferable to ensure coherence and precision.
- Summarization: For summarizing articles or reports, beam search can help maintain high coherence and factual accuracy. Top-p sampling may also effectively generate concise summaries that capture the essence of the original content while reducing redundancy.
Conclusion
In conclusion, selecting the right decoding strategy is pivotal to optimizing the performance of language models across various applications. Ultimately, understanding the strengths and limitations of each decoding method allows for more informed decision-making, leading to higher quality, more relevant, and engaging AI-generated text.
If you’re interested in exploring examples with code, check out our video tutorial. We also encourage you to explore our Google Colab notebook.
We also encourage you to discover Deci’s LLMs and Gen AI Development Platform, designed to enable developers to deploy and scale high-performing models efficiently, with the added benefit of keeping their data on-premises.
If you’re interested in exploring our range of models, we invite you to sign up for a free trial of our API.
For those curious about our VPC and on-premises deployment options, we encourage you to book a 1:1 session with our experts.