📘Access the notebook.
AI engineers often find themselves at the forefront of pioneering customer service technologies.
Imagine you’re an AI engineer at TechAssist, a leader in consumer tech. Your latest project? To revolutionize the company’s customer service chatbot using advanced AI techniques.
The core of this endeavour involves integrating a “CoT golden dataset” into the chatbot’s framework. This dataset isn’t ordinary; it’s a rich compilation of problem-solving methods, step-by-step guides, annotated customer interactions, and extensive product knowledge.
The goal is to leverage this dataset to significantly improve the chatbot’s performance.
Why Chain of Thought (CoT) Prompting?
CoT Prompting is a method that guides language models through a step-by-step reasoning process.
Instead of directly providing an answer, the model displays its reasoning, forming a coherent “chain” of thoughts. This process emulates human-like thought patterns, which is especially useful for complex problem-solving tasks. Standard prompting in AI models typically involves giving a direct answer without showing the underlying reasoning process.
For example, if asked a simple arithmetic question, the standard response would be a straightforward number, say “11”.
In contrast, CoT prompting dives deeper.
Taking the same arithmetic question, a CoT response would detail each step in the calculation, such as “Roger began with 5, then added 6 from 2 cans, so 5 + 6 equals 11”. This provides the answer and outlines the logical pathway taken to reach it. This method enables the chatbot to provide the correct answers and demonstrate clear and logical reasoning steps. This is particularly beneficial in resolving complex customer service queries where understanding the problem-solving process is as important as the solution.
A chatbot that employs CoT prompting benefits from:
- Enhanced Reasoning: By breaking down complex customer queries into more straightforward steps, CoT prompting ensures more accurate and understandable solutions.
- Synergy with Few-Shot Prompting: Incorporating example-based guidance greatly enhances the model’s ability to handle intricate tasks.
- Interpretability: CoT prompting shines a light on the AI’s thought process, making its reasoning transparent and understandable.
- Versatile Applications: This approach is invaluable across various fields, including arithmetic, commonsense, and symbolic reasoning tasks.
TechAssist plans to use this approach to enhance the reasoning capabilities of its chatbot.
The process involves:
- Vector Database Integration: Embedding queries in a vector space and retrieving relevant CoT examples based on their contextual “distance.”
- Query Variation and Amalgamation: Generating multiple perspectives of a single user query to gather a broader set of relevant CoT examples, overcoming the limitations of distance-based retrieval.
The Search for the Right LLM For Your Usecase
The project extends beyond theory, as you must identify the most effective Large Language Model (LLM) for practical customer service scenarios. This involves comparing different LLMs, each known for specific strengths, under real-life conditions.
This hypothetical scenario isn’t just about testing algorithms; it explores integrating data, logic, and AI to enhance customer service. As an AI engineer at TechAssist, you stand at the cusp of a new era in AI development, pushing the boundaries of AI comprehension and problem-solving.
In this blog, you’re going to put yourself in the shoes of an AI Engineer working on this problem and try to find the right LLM for the job.
Methodology: Comparative Analysis of LLMs
The strategy includes a comprehensive testing phase:
- Generating CoT Responses: Evaluating models in zero, one, and three-shot regimes.
- Judgment Analysis: Use a more powerful LLM as an “LLM Judge” to assess each model’s hit rate and reasoning quality.
- Faithfulness Metric: Applying the
ragasframework to measure the accuracy of each model’s reasoning.
DeciLM-7B-instruct
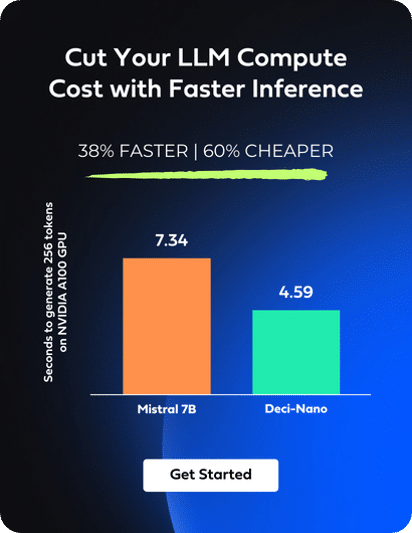
DeciLM-7B and its variant, DeciLM-7B-instruct, have been introduced to address the increasing computational demands and costs associated with LLMs. DeciLM-7B, with 7.04 billion parameters, offers a throughput 4.4 times higher than Mistral 7B and improved accuracy.
DeciLM-7B-instruct is fine-tuned from DeciLM-7B for instruction-following use cases. Notably, both models rank among the top-performing LLMs in their category. The efficiency of DeciLM enhances the viability and scalability of various generative AI applications, such as support chatbots and content creation assistants.
To understand the groundbreaking advancements in language model technology, consider the following key highlights of DeciLM-7B, a leading player in the field:
🎯 High Accuracy: DeciLM-7B achieves an average score of 61.55 on the Open LLM Leaderboard, surpassing Mistral 7B. It also scores higher than popular 13 billion-parameter models, such as Llama 2 and Vicuna.
⚡ Enhanced Throughput Performance: DeciLM-7B is a highly efficient language model, designed for handling large batches with impressive throughput. The table below provides a comprehensive look at DeciLM-7B’s performance across different scenarios, including operations on both NVIDIA A10G and NVIDIA A100 GPUs. It further breaks down the results based on tasks involving a prompt and generation length of either 512 or 2048 tokens, offering a clear view of its capabilities under varying conditions.
| Inference Tool | Hardware | Prompt Length | Generation Length | Generated tokens/sec | Batch Size |
| HF (Pytorch) | A100 (SXM4-80GB-400W) | 512 | 512 | 1174 | 352 |
| HF (Pytorch) | A100 (SXM4-80GB-400W) | 2048 | 2048 | 328 | 72 |
| HF (Pytorch) | A10G | 512 | 512 | 400 | 48 |
| HF (Pytorch) | A10G | 2048 | 2048 | 97 | 8 |
🚀 Accelerated Speed with Infery-LLM: Combined with Infery-LLM, the fastest inference engine, DeciLM-7B’s performance is significantly boosted, achieving 4.4x the speed of Mistral 7B with vLLM. This combination is vital for industries needing high-speed, high-volume customer interaction like telecommunications, online retail, and cloud services.
🔍 Innovative Architecture: DeciLM-7B, developed with AutoNAC’s help, uses Variable Grouped Query Attention for optimal accuracy-speed balance.
🌟 Instruction-Tuned Variant: DeciLM-7B-instruct, tuned with LoRA on the SlimOrca dataset, scores 63.19 on the Open LLM Leaderboard and is one the best 7B instruct models obtained using simple LoRA fine-tuning, without relying on preference optimization techniques such as RLHF and DPO.
Mistral-7B-instruct-v0. 1
The Mistral 7B variant, Mistral-7b-instruct-v0. 1, stands out for its impressive efficiency and robust performance, encapsulated in its 7-billion-parameter design.
🔗 Overview of the CoT Collection Dataset:
Because I don’t actually have a dataset of customer interactions, I’ll use a stand in dataset for illustrative purposes.
The CoT Collection paper outlines an innovative approach to enhance the reasoning abilities of smaller language models (LMs).
This dataset, available on Hugging Face, comprising 1.84 million rationales across 1060 tasks, is designed to boost chain-of-thought (CoT) capabilities, particularly in models with fewer than 100B parameters. The results from the study are promising: CoT fine-tuning led to notable improvements in both zero-shot and few-shot learning performances.
The researchers employed a thorough evaluation method, including both direct and CoT evaluations, to assess the impact of CoT fine-tuning on various tasks. They found that smaller LMs, when trained with the CoT Collection, could outperform larger models in some scenarios, including outdoing ChatGPT in specific few-shot learning settings.
In this blog post, we won’t use this dataset for fine-tuning. We’ll use it as an example of what a golden dataset may look like.
📝 Dataset Structure:
- 🎯
source: Input given to the language model. - ✅
target: Ground truth answer. - 🧩
rationale: CoT explaining how the target is derived from the source. - 📂
task: Shows dataset origin for source and target.
Zero shot prompting
Zero-shot prompting involves presenting a query or task to an LLM without providing any specific training or examples for that particular task.
Zero-shot prompting relies on the model’s extensive training on diverse content, enabling it to respond accurately even to prompts outside its initial training data. The significance of zero-shot prompting lies in its ability to extend the versatility of LLMs. It allows these models to adapt to various tasks, making them more effective across various applications without requiring task-specific tuning.
Prompt engineering, a practice closely related to this technique, involves carefully crafting prompts to guide the LLM toward producing specific, relevant outputs.
The structure and wording of a prompt can markedly influence the quality of the model’s response, highlighting the importance of skillful prompt design in maximizing the efficacy of zero-shot prompting.
One shot prompting
One-shot and few-shot prompting are two related concepts in LLMs that, like zero-shot prompting, relate to how these models handle tasks they weren’t specifically trained for.
In one-shot prompting, the LLM is given a single example or instance to illustrate the task. This example serves as a guide for the type of response or output that is expected. An LLM can often generalize and produce relevant responses for similar tasks or queries even with just one example.
The single example acts as a point of reference for the model, enabling it to understand the context and desired format of the response.
The following is the one shot example that is provided to the models for generation:
The following is ###Input that provides context. The ###Input is paired with either an instruction or a question.
Input: In this task, answer ‘Yes’ if the frequency of the given word in the two sentences is equal, else answer ‘No’. Sentence1: ‘a man in a vest standing in a bathroom’, Sentence2: ‘a person with ripped jeans on riding on a skateboard’. Is the frequency of the word ‘a’ in two sentences equal?
The following is an example of Rationale and Answer related to the Input.
Rationale: Sentence1: ‘a man in a vest standing in a bathroom’, Sentence2: ‘a person with ripped jeans on riding on a skateboard’.\nThe frequency of the word ‘a’ in sentence 1 = 4, The frequency of the word ‘a’ in sentence 2 = 3.\n4 == 3? No.
Answer: No
Three shot prompting
Few-shot prompting involves providing the model with a few (more than one but typically not many) examples of the task or type of query.
Each example helps the model better understand the nuances of the task and the range of acceptable responses. This method is handy for more complex tasks where more than one example might be needed to encapsulate the full scope or variations of the task.
Both one-shot and few-shot prompting rely on the inherent capabilities of LLMs to generalize from examples and understand context.
They balance zero-shot prompting, which provides no examples, and full-fledged training or fine-tuning, which involves a comprehensive set of examples and training iterations. These methods make LLMs versatile and powerful tools for a wide range of natural language processing tasks.
They demonstrate the model’s ability to adapt and respond appropriately even with limited direct instruction or guidance specific to the task at hand.
LLM as Judge
The study titled “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena” explores the effectiveness of large language models (LLMs) in the role of judges for chat assistants.
It addresses the complexity of aligning these models with human preferences, particularly in tasks without set boundaries. Initially, the paper highlights the insufficiency of traditional benchmarks in gauging LLMs’ alignment with human expectations in open-ended scenarios, noting that existing benchmarks don’t fully grasp how users perceive the usefulness of chatbots.
Key Insights from the Paper
Assessing LLM-as-a-Judge: Pros and Cons
- Pros:
- Scalability: Utilizing LLM-as-a-judge minimizes human intervention, allowing for extensive, rapid benchmarking.
- Transparency: These judges offer evaluations and reasons behind them, enhancing interpretability.
- Cons:
- Position Bias: A tendency to favor specific viewpoints, a phenomenon not unique to LLMs but also seen in human and other machine learning contexts.
- Verbosity Bias: Preferring lengthier responses over more concise ones, even if the latter are more precise or accurate.
- Self-Preference Bias: Some LLM judges show a bias towards responses they generate.
- Limited Mathematical and Logical Evaluation: LLMs struggle to accurately grade math and logic questions due to their inherent knowledge limitations.
Evaluating Agreement
- Strong Alignment Between GPT-4 and Human Judgment:
- GPT-4’s assessments align with expert human opinions in MT-bench and Chatbot Arena.
- Agreement levels with humans reached up to 85%, surpassing human-to-human agreement (81%), indicating GPT-4’s close alignment with the majority human viewpoint.
- In some instances, human decisions were swayed by GPT-4’s evaluations, with a 75% agreement rate and a 34% willingness among humans to reconsider their choices based on GPT-4’s input.
Bridging Human Preferences and Standard Benchmarks
- The paper advocates for a dual-method approach in future LLM benchmarking, integrating ability and preference assessments with LLM-as-a-judge. This strategy is designed to thoroughly evaluate LLMs in terms of both core competencies and alignment with human expectations.
- It proposes incorporating human preference benchmarks like MT-bench and Chatbot Arena into the existing standardized LLM benchmarks, addressing various model aspects.
- A comprehensive evaluation framework is suggested, leveraging both benchmark types to effectively assess LLMs’ fundamental abilities and human alignment.
- The findings suggest the practicality of using LLM-as-a-judge for approximating human preferences, potentially setting a new standard in future benchmarking.
The approach delineated in the paper offers valuable insights into the nuanced aspects of model assessment, particularly in terms of aligning with human preferences and addressing inherent biases.
Translating these insights to the practical functionalities of the DatasetEvaluator class, we can see a complementary relationship. The DatasetEvaluator leverages specific evaluators — a labelled score string evaluator and a chain of thought (COT) question-answering evaluator — akin to the multi-dimensional assessment advocated in the paper. This alignment is particularly evident in the COT Evaluation (evaluate_cot) and Coherence Evaluation (evaluate_coherence) methods.
These methods echo the paper’s emphasis on both the accuracy and the human-like coherence of responses, ensuring a comprehensive and balanced evaluation of language models that is not only methodologically sound but also reflective of the evolving benchmarks in the field, as suggested by the recent research.
The DatasetEvaluator class wraps evaluation metrics derived from two specialized evaluators, both of which are LangChain String Evaluators.
- A labelled score string evaluator
- A chain of thought (COT) question-answering evaluator
Each row corresponds to a dataset entry that includes a prediction, a reference label (ground truth), and an input context.
A string evaluator is a component used to assess the performance of a language model by comparing its generated text output (predictions) to a reference string or input text. These evaluators provide a way to systematically measure how well a language model produces textual output that matches an expected response or meets other specified criteria.
🎯 Zero Shot Evaluation
Based on the table and graph below, it’s clear that DeciLM-7B-instruct is the winner in the zero-shot setting.
Coherence score
We’re using GPT-4-Turbo and asking it: Is the submission coherent, well-structured, and organized?.
GPT-4-Turbo gives a score between 1 and 10 to the generation based on the ground truth reference label. In the zero-shot setting, DeciLM-7B-instruct scores 0.30 points higher on coherence than Mistral-7b-instruct-v0. 1.
Number correct
We’re using GPT-4 to grade answers to questions using chain of thought ‘reasoning’ based on a reference answer. It then evaluates whether the submission is correct, accurate, and factual, and returns one of the following evaluation results: CORRECT or INCORRECT. In the zero-shot setting, DeciLM-7B-instructanswers correct more frequently than Mistral-7b-instruct-v0. 1.
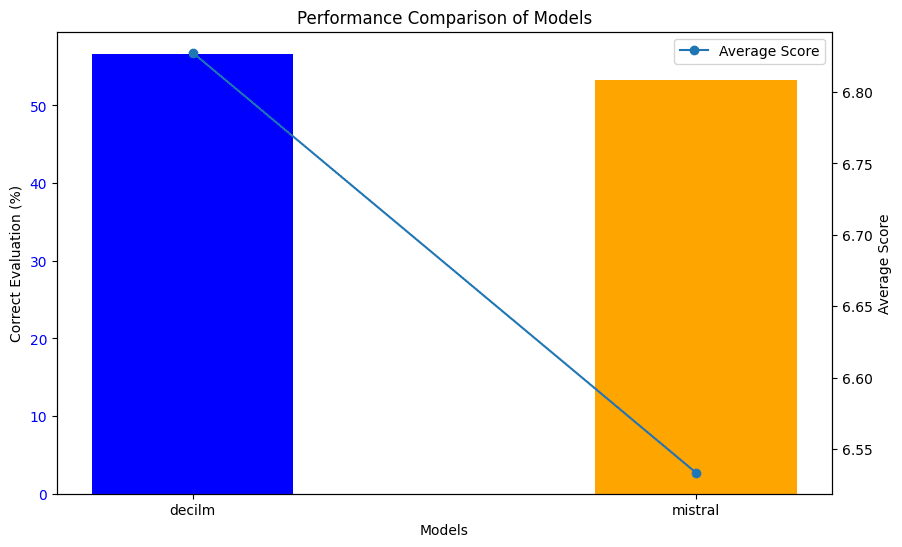
🧩 One Shot Evaluation
Based on the table and graph below, it’s clear that DeciLM-7B-instruct is also a winner in the one-shot setting.
We observe that DeciLM-7B-instruct outperforms Mistral-7b-instruct-v0. 1 in both coherence and correctness. DeciLM-7B-instruct maintains a stable average coherence score of 6.80 and a correctness percentage of 56.67%, which is consistent with its performance in the zero-shot setting. In contrast, Mistral exhibits a significant drop in coherence, scoring only 5.28, and a decrease in correctness percentage to 50.00%.
These results suggest that DeciLM-7B-instruct has a notable advantage in adapting to one-shot learning scenarios, maintaining its ability to generate coherent and accurate responses even with minimal context.
Mistral-7b-instruct-v0. 1’s decreased performance indicates potential areas for improvement in utilizing single examples for learning and generating responses.
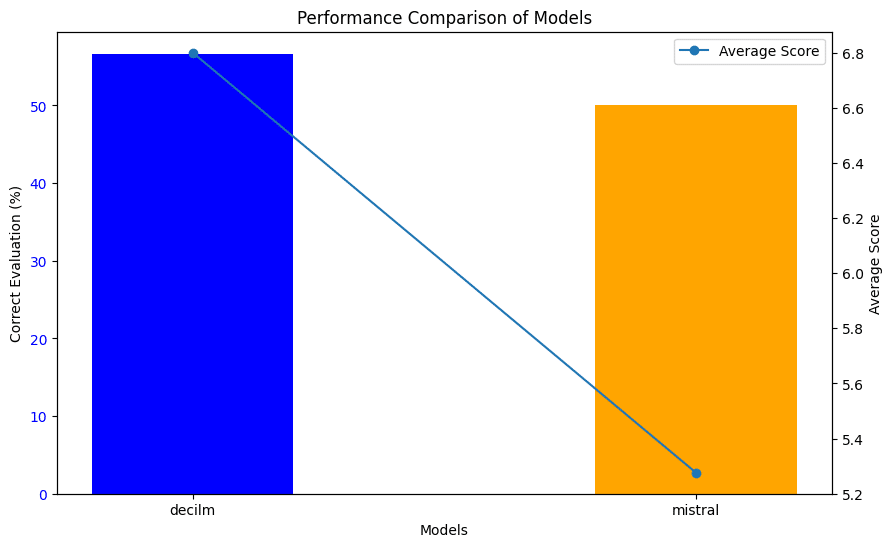
🌟 Three Shot Evaluation
Analyzing the three-shot setting results, it’s evident that DeciLM-7B-instruct continues to outperform Mistral-7b-instruct-v0. 1, albeit with some changes in its performance metrics compared to the zero-shot and one-shot settings.
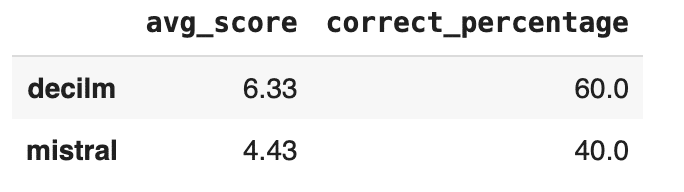
In the three-shot setting, DeciLM-7B-instruct shows a notable decrease in its average coherence score to 6.33 but an increase in its correctness percentage to 60.0%. This shift suggests that while DeciLM’s response coherence slightly declines with more examples, its ability to provide correct answers improves.
On the other hand, Mistral-7b-instruct-v0. 1 scores significantly lower in coherence with an average of 4.43 and also trails in correctness, achieving only a 40.0% correctness rate. These results indicate that Mistral’s performance continues to lag behind DeciLM-7B-instruct, especially in effectively utilizing multiple examples to enhance its text generation and reasoning capabilities.
This pattern of results highlights DeciLM-7B-instruct’s superior adaptability and robustness across different shot settings, maintaining a balance between coherence and correctness. Mistral-7b-instruct-v0. 1’s performance, meanwhile, suggests a need for improvement in leveraging multiple examples for better coherence and accuracy in its responses.
🔍 Trend Analysis of Coherence Metric Across Different Shot Settings for DeciLM and Mistral
Introduction: In this analysis, we examine the coherence scores of two language models, DeciLM-7B-instruct and Mistral-7b-instruct-v0. 1, across varying shot settings: Zero, One, and Three. The coherence metric evaluates how well-structured and organized a model’s predictions are, serving as a key indicator of its performance in generating coherent text.
Data Overview: The coherence scores for each model in different shot settings are as follows:
- DeciLM-7B-instruct: Zero Shot – 6.83, One Shot – 6.80, Three Shot – 6.33
- Mistral-7b-instruct-v0. 1: Zero Shot – 6.53, One Shot – 5.28, Three Shot – 4.43
Analysis of Trends:
DeciLM-7B-instruct
- We observe a gradual decline in DeciLM-7B-instruct’s coherence scores from Zero to Three shot settings. This trend suggests that while DeciLM starts strong, its ability to maintain coherence slightly diminishes with the introduction of more context.
- Despite this decline, DeciLM-7B-instruct’s scores remain relatively high, indicating a robust baseline capability in coherence.
Mistral-7b-instruct-v0. 1
- Mistral-7b-instruct-v0. 1 displays a more significant drop in coherence scores, especially moving from the Zero to the One and Three shot settings. This indicates a challenge for Mistral in preserving coherence as it processes more contextual information.
- When compared with DeciLM-7B-instruct, Mistral-7b-instruct-v0. 1 starts at a lower baseline in the zero-shot setting and experiences a steeper decline.
🔎 Recap of Correctness Scores Across Different Shot Settings
Data Overview: The correctness percentages for DeciLM-7B-instruct and Mistral-7b-instruct-v0. 1l in each shot setting are as follows:
- DeciLM-7B-instruct: Zero and One Shot – 56.67%, Three Shot – 60.0%
- Mistral-7b-instruct-v0. 1: Zero Shot – 53.33%, One Shot – 50.0%, Three Shot – 40.0%
Analysis of Trends:
DeciLM-7B-instruct
- DeciLM-7B-instruct demonstrates a stable performance in Zero and One shot settings, maintaining a correctness percentage of 56.67%. This consistency suggests a strong baseline capability in generating accurate responses.
- In the Three shot setting, DeciLM-7B-instruct shows an improvement, with its correctness percentage rising to 60.0%. This indicates that additional context enhances DeciLM’s ability to provide correct answers.
Mistral-7b-instruct-v0. 1
- Mistral-7b-instruct-v0. 1 starts with a slightly lower correctness percentage than DeciLM-7B-instruct at 53.33% in the Zero shot setting.
- There is a noticeable decline in Mistral-7b-instruct-v0. 1’s performance in the One and Three shot settings, with correctness percentages dropping to 50.0% and 40.0%, respectively. This trend suggests that Mistral faces challenges in maintaining accuracy as more context is introduced.
✅ Faithfulness Metric
Faithfulness as an evaluation for language models assesses how well a model’s responses align with the given context or source material, ensuring relevance and factual correctness.
Faithfulness for evaluating chain of thought (CoT) reasoning within language models helps assess accuracy and reliability of outputs.
This metric evaluates whether the CoT provided by a model genuinely represents its internal reasoning process, rather than being a superficial layer atop its decision-making. The research paper “Measuring Faithfulness in Chain-of-Thought Reasoning” highlights the variability and complexity inherent in this process. It reveals that the dependence of a model on its CoT reasoning can vary significantly, influenced by factors like the model’s size and the specific nature of the task.
Interestingly, as models grow larger and more capable, they often exhibit less faithful reasoning in many tasks.
🔣 Methodology for Measuring Faithfulness
- Statement Analysis: A “judge” LLM conducts an initial examination of the model’s answer. This analysis identifies and isolates key statements that constitute the core of the response. It breaks down the answer into distinct claims or assertions that can be individually assessed.
- Verification: Each identified statement is verified, where its accuracy and alignment with the original context or source material is assessed. This step determines if the statements are factually correct and contextually relevant, adhering to the actual information contained in the source.
Scoring Model
The evaluation culminates in assigning a faithfulness score, which ranges from 0 (completely unfaithful) to 1 (fully faithful).
The generated answer is regarded as faithful if all the claims that are made in the answer can be inferred from the given context. To calculate this, a set of claims from the generated answer is first identified. Then each one of these claims are cross checked with given context to determine if it can be inferred from given context or not.
This score is computed based on the ratio of context-consistent statements to the total number of statements made in the response. A higher score indicates a greater degree of faithfulness, reflecting the model’s ability to provide accurate and contextually appropriate answers.
Application in the ragas Framework
In the ragas framework, a specialized class named Faithfulness is dedicated to automating this evaluation process. From customer service chatbots to information retrieval systems, ensuring the faithfulness of responses is crucial in maintaining the quality and reliability of AI interactions.
Preparing a dataset for use in ragas
You want to use the evaluate function from the ragas library to assess the performance of different text generation models on a dataset.
This function requires the dataset to be structured in a specific way:
question: A list of strings, each representing a question your RAG pipeline will be evaluated on.answer: A list of strings, each being an answer generated by the RAG pipeline.contexts: A list of lists of strings, where each inner list is the contexts used by the LLM to generate the corresponding answer.
Your task involves evaluating the performance of different generation models (‘decilm_generation’, ‘mistral_generation’, ‘mpt_generation’), and adding the evaluation results (like faithfulness scores) back to your dataset.
To achieve this, we need to:
- Prepare the Dataset: Format your dataset according to the
evaluatefunction’s requirements. - Run the Evaluation: Use the
evaluatefunction to assess each model. - Update the Dataset: Append the evaluation results to your dataset.
⚖️ Analysis of the Faithfulness Metric Results
Analyzing the faithfulness metric across different shot settings for DeciLM-7B-instruct and Mistral-7b-instruct-v0. 1 reveals interesting patterns:
0️⃣ Zero-Shot Setting
- DeciLM-7B-instruct has a faithfulness score of 0.4764, indicating that just under half of its generated statements are fully consistent with the given context.
- Mistral-7b-instruct-v0. 1 scores slightly lower in faithfulness at 0.4214, suggesting its responses are less frequently aligned with the source material compared to DeciLM-7B-instruct.
1️⃣ One-Shot Setting
- DeciLM-7B-instruct shows a marginal decrease in faithfulness to 0.4728. This slight drop could indicate a negligible impact of additional context on its ability to generate faithful responses.
- Mistral-7b-instruct-v0. 1 again scores lower than DeciLM-7B-instruct, with a faithfulness score of 0.4095, maintaining a consistent gap between the two models.
3️⃣ Three-Shot Setting
- DeciLM-7B-instruct demonstrates an improvement in faithfulness, scoring 0.5194. This suggests that providing more context (three shots) enhances DeciLM-7B-instruct’s alignment with the source material.
- Mistral-7b-instruct-v0. 1 also shows a notable increase in faithfulness to 0.4667, which is its highest score across the settings. This improvement indicates that Mistral benefits more noticeably from additional context than DeciLM-7B-instruct.
🔭 Observations and Implications
- DeciLM-7B-instruct consistently outperforms Mistral-7b-instruct-v0. 1 in faithfulness across all settings, albeit with marginal differences in one-shot and three-shot settings.
- Impact of Additional Context: Both models show an improvement in faithfulness with more context (three-shot), but the effect is more pronounced for Mistral-7b-instruct-v0. 1.
- Model Capabilities: These results reflect on each model’s inherent capabilities in contextual understanding and factual alignment, with DeciLM-7B-instruct generally maintaining a slight edge.
This analysis underscores the importance of faithfulness as a metric, revealing how different models may respond to the amount of context provided, and their inherent abilities to generate responses that are not just coherent or relevant, but also factually aligned with the source material.
🌟 DeciLM-7B-instruct: A Cost Effective and Efficient Choice
Upon completing our analysis, it is clear that DeciLM-7B-instruct has a distinct edge over Mistral-7B-instruct-v0.1 in several critical areas. This advantage makes it a more suitable option for tasks including but not limited to customer service chat applications.
DeciLM-7B-instruct’s performance is notably more consistent in zero, one, and three-shot settings, paired with higher coherence and correctness scores. These qualities position it as a practical choice for customer service chatbots, where understanding and accurately responding to customer queries is essential. Selecting DeciLM-7B-instruct reflects a decision to employ a tool that can competently handle these requirements.
DeciLM-7B-instruct’s proficiency in zero-shot and few-shot scenarios is a defining factor in its operational efficiency, establishing it as the superior choice for businesses prioritizing ease of use and cost-effectiveness. This capability enables the model to be deployed effectively straight out of the box, circumventing the need for extensive and often time-consuming fine-tuning. Such an attribute is not only a boon in terms of resource management but also translates into substantial cost savings and time efficiencies. Companies opting for DeciLM-7B-instruct can, therefore, anticipate notable improvements in customer interaction quality. This is largely due to the model’s adeptness at addressing a wide range of inquiries with minimal initial setup, making it an ideal solution for enhancing customer engagement through AI.
Discover Deci’s LLMs and GenAI Development Platform
In addition to DeciLM-7B, Deci offers a suite of fine-tunable high performance LLMs, available through our GenAI Development Platform. Designed to balance quality, speed, and cost-effectiveness, our models are complemented by flexible deployment options. Customers can access them through our platform’s API or opt for deployment on their own infrastructure, whether through a Virtual Private Cloud (VPC) or directly within their data centers.
If you’re interested in exploring our LLMs firsthand, I encourage you to sign up for a free trial of our API.
For those curious about our VPC and on-premises deployment options, you’re invited to book a 1:1 session with our experts.