Introduction
The widespread adoption of Large Language Models (LLMs) faces a significant challenge: high LLM inference costs. These costs, primarily due to the need for substantial computational resources, hinder the broader adoption of LLMs. In this blog post, we address this crucial issue by introducing Infery-LLM, a novel solution designed to reduce LLM inference costs. We will explain why traditional optimization strategies fall short for LLMs, provide a detailed technical insight into Infery-LLM, and show how it can help lower computational expenses, enabling more cost-effective operations for models like DeciLM-7B and facilitating the transition to more affordable hardware.
The Trouble with LLM Inference and Why Traditional Optimization Techniques Fail
The deployment of LLMs into real-world applications offers a paradigm shift in human-computer interaction. However, translating the power of LLMs into practical solutions necessitates confronting the challenges of optimizing them for inference, especially at scale. Applying traditional optimization techniques like post-training quantization, compilation with autotuning, and multithreading or multi-streaming to LLMs reveals distinct inefficiencies and limitations due to the unique demands of these complex systems.
Post-training quantization
Post-training quantization is often used to make models run more efficiently and reduce inference cost. However post-training quantization in LLMs involves significant complexities and challenges. Converting floating-point representations such as FP32 to lower precision formats like FP16 or INT8 is fraught with challenges. LLMs often contain components that are extremely sensitive to reduced precision, which can exacerbate quantization errors. When dealing with the vast number of parameters typical in LLMs, even small inaccuracies per parameter can accumulate, leading to significant overall errors and degradation in model fidelity. This issue is especially pronounced in normalization layers, where precision loss directly impacts the model’s ability to generate coherent and contextually accurate outputs.
Compilation
Compilation with frameworks like TensorRT or OpenVINO is also problematic for LLMs. Unlike simpler neural networks, autoregressive LLMs comprise multiple, interdependent modules that must work in tandem. This architectural complexity requires an additional orchestration layer to manage the interactions between different components effectively. Moreover, the need to accommodate input sequences of varying lengths often necessitates custom solutions or workarounds, which can significantly impair the model’s runtime performance. Such adaptations can result in inefficient memory use and processing bottlenecks, undermining the potential speedups offered by these advanced compilation tools.
Multithreading and Multistreaming
Applying traditional optimization techniques like multithreading and multi-streaming (CUDA streams) to LLMs presents significant challenges, particularly due to the high memory demands of these models. Multithreading, which involves running multiple computational threads concurrently, becomes impractical for LLMs, if trying to parallelize multiple LLM batches. The reason lies in the substantial memory consumption required for processing each data batch; alternating between batches in a multi-threaded environment leads to excessive memory usage, rendering this approach ineffective.
Similarly, multi-streaming, designed to execute parallel operations on a GPU, faces hurdles with LLMs. While it aims to enhance processing efficiency by managing multiple tasks simultaneously, the extensive memory requirements of LLMs complicate this parallelization, making it challenging to synchronize and manage the workload effectively. This complexity is further amplified in multi-GPU setups, where orchestrating a workload across several GPUs introduces additional layers of complexity. Coordinating these GPUs to work in tandem on large-scale LLMs requires careful management to avoid significant overheads in synchronization and communication. As a result, while these techniques offer potential improvements in efficiency, their practical implementation in the context of memory-intensive LLMs remains a formidable challenge, necessitating innovative solutions to optimize their performance effectively.
What is Infery-LLM?
To address the challenge of high LLM inference cost, Deci offers Infery-LLM.
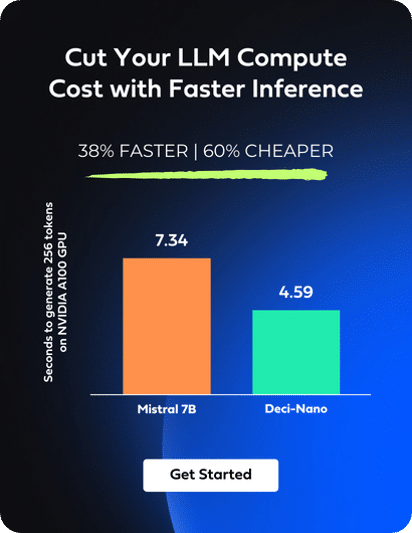
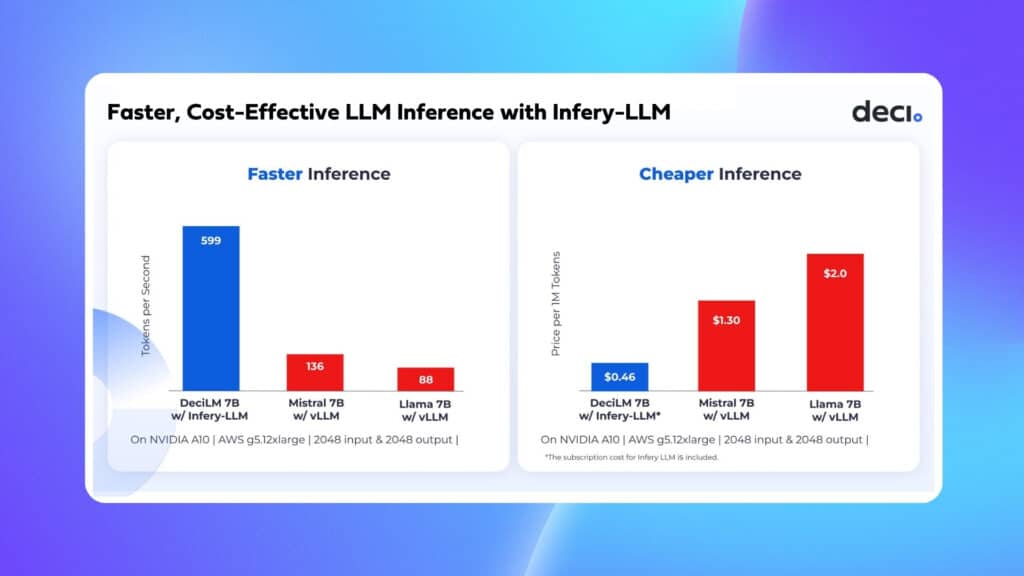
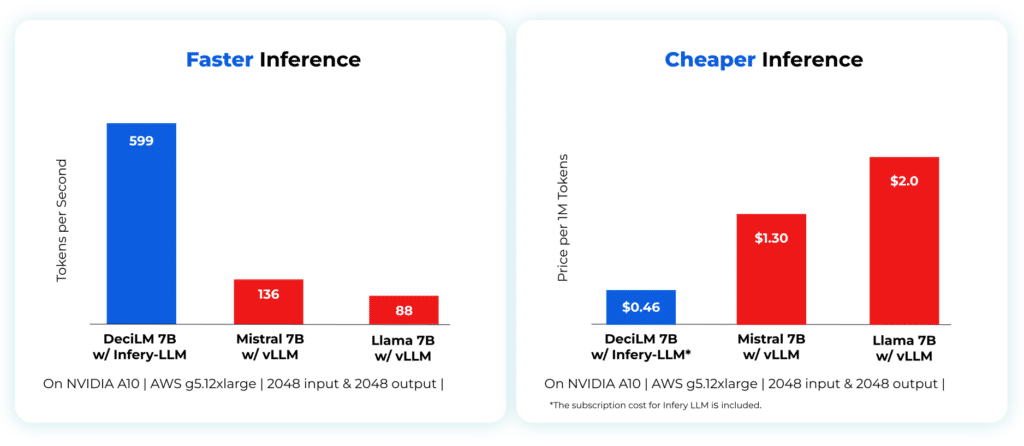
Infery-LLM is an inference runtime engine that enables inference in production on various hardware and frameworks easily. Engineered to enhance performance while maintaining accuracy, Infery-LLM’s comprehensive library includes advanced techniques for compiling and optimizing LLMs for inference, from selective quantization to runtime optimizations like continuous batching. Enabling inference with just three lines of code, Infery-LLM makes it easy to deploy into production and into any environment. Its optimizations unlock the true potential of LLMs, as exemplified when it runs DeciLM-7B, achieving 4.4x the speed of Mistral 7B with vLLM and saving 64% in LLM inference costs.
What you can do with Infery-LLM
Cut Compute Costs with Faster LLM Inference
Infery-LLM significantly reduces high compute costs associated with LLM inference by enabling faster processing with throughput and low latency optimizations. For high batch scenarios, Infery-LLM achieves up to 5 times higher throughput compared to other approaches. This increase in throughput is particularly beneficial for applications that require processing vast amounts of information quickly, such as data analysis tools or content recommendation engines. In scenarios where small batches are the norm, Infery-LLM excels by maintaining low latency, ensuring more efficient processing and better utilization of hardware resources. Its dynamic batching is pivotal in managing variable input loads, effectively balancing throughput and latency, and ensuring consistent performance even under fluctuating demand.
Moreover, the auto-tuning feature in Infery-LLM plays a pivotal role in optimizing performance. It automatically identifies and employs the optimal kernels for a given GPU setup, tailoring the computation to the specific characteristics of the hardware. This optimization ensures that each GPU is used to its full potential, reducing the need for over-provisioning of hardware resources and thus lowering the compute costs associated with LLM inference.
Migrate to More Affordable Hardware
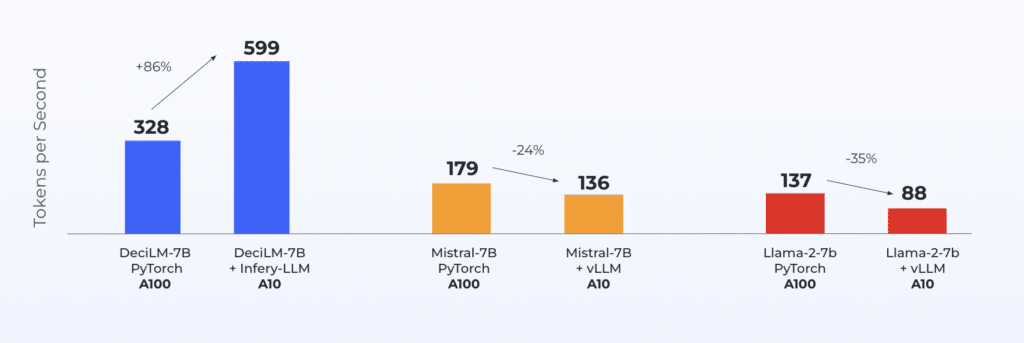
Infery’s approach to optimizing LLMs enables significant performance improvements on less powerful hardware, as compared to other approaches on vLLM or PyTorch even on high-end GPUs, significantly reducing the overall cost of ownership and operation. This shift not only makes LLMs more accessible to a broader range of users but also opens up new possibilities for applications with resource constraints.
High Performance Across Diverse Environments and Hardware
Infery-LLM addresses the challenges of achieving high performance at scale, and in practical, real-world applications. It optimizes LLMs for various hardware platforms with advanced quantization techniques ensuring that models are scalable while drastically reducing the computational load and memory requirements.
Furthermore, Infery-LLM incorporates custom kernel optimizations that are tailored to the specifics of the target hardware, maximizing processing efficiency. This is crucial for deploying complex LLMs across diverse environments, from cloud-based servers to edge devices.
Simplify Deployment
Beyond reducing the cost of LLM inference, Infery-LLM greatly simplifies the deployment process of LLMs, making it accessible and efficient even for those with limited technical expertise in machine learning infrastructure. Its automated, precompiled installation and deployment process streamlines the setup, significantly reducing the time and effort typically required to get LLMs up and running. This automation ensures that all necessary components are correctly configured, minimizing potential errors or compatibility issues. Additionally, Infery-LLM allows users to run inference with just three lines of code, a feature that dramatically lowers the barrier to entry for implementing complex LLMs. This ease of use is especially beneficial for developers looking to quickly integrate LLM capabilities into their applications without delving into the intricacies of model deployment.
Under the Hood of Infery-LLM
Selective Quantization
With kernels that support all quantizations, Infery enables selective quantization, a sophisticated technique that enhances the efficiency and performance of LLMs during deployment. Selective quantization is a process that involves compressing a model’s parameters, thereby reducing the memory footprint required for inference. It achieves this by converting the parameters from a higher precision format, like FP32 (32-bit floating point), to a lower precision format, such as INT8 (8-bit integer). However, unlike traditional quantization that applies uniformly across the entire model, selective quantization in Infery-LLM is more nuanced and targeted.
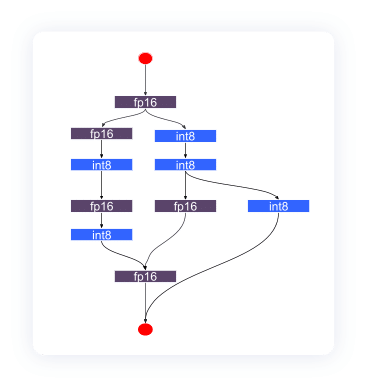
By adopting this selective approach, Infery-LLM allows for a fine-tuned balance between the model’s performance and efficiency. AI teams can take advantage of the speed-up offered by quantization without incurring the usual cost in terms of accuracy and quality often associated with lower precision formats. This means that models can be deployed more efficiently on cost-effective hardware instances, thereby cutting LLM inference cost, without compromising the fidelity and reliability of the outputs.
Optimized Sampling
Sampling in natural language processing refers to the method of selecting new tokens based on a model’s output probabilities. Infery’s optimized sampling method, utilizing a vectorized approach, significantly enhances the performance of language models. This method, by removing the need for CPU-GPU synchronization, allows for asynchronous sampling on the GPU. Such an approach frees up the CPU to manage other critical tasks, such as tokenization and detokenization, thereby streamlining the overall processing workflow. Moreover, the incorporation of parameters like temperature, top p, and top k in Infery’s sampling process allows for control over the model’s output. Temperature adjusts the distribution’s narrowness from which tokens are sampled, directly influencing the model’s creativity. Meanwhile, top p and top k parameters determine the pool size of candidate tokens for selection, offering a balance between randomness and predictability in the model’s responses. This optimized method results in a more efficient and precise generation of language model outputs.
KV Caching
In LLMs, each token processed during inference involves calculating certain key and value pairs, which are essential for the model’s attention mechanisms to function well. However, recalculating these pairs for tokens that have already been seen in the same context can be highly inefficient and time-consuming. KV caching addresses this issue by storing the keys and values of previously seen tokens in a cache. When a new token is inserted into the model, the KV cache calculates its attention with all previously seen token keys and values without having to recalculate. This not only speeds up the inference process but also reduces the computational load on the system, making the operation of LLMs more resource-efficient.
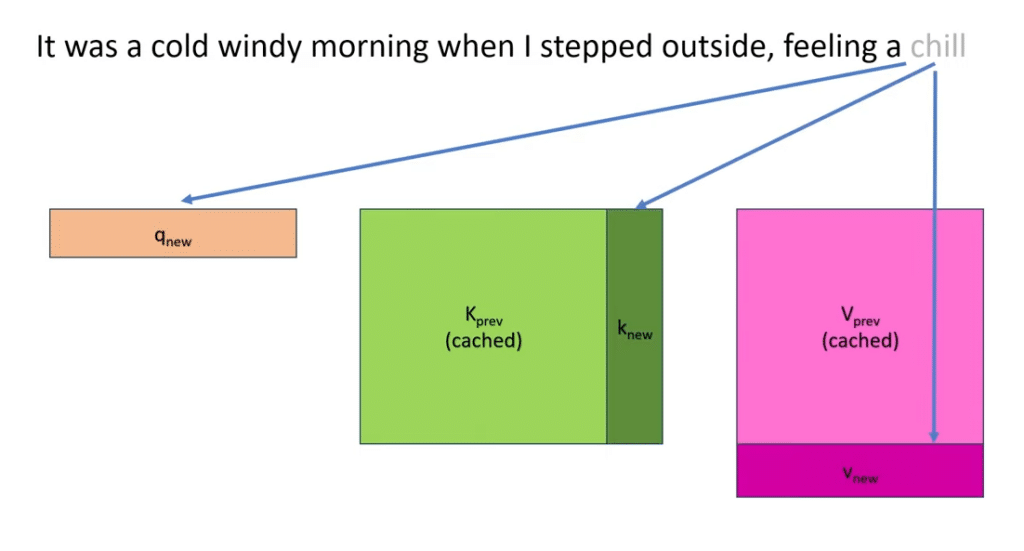
By implementing KV caching, Infery-LLM significantly optimizes the performance of LLMs, particularly in scenarios involving repetitive or similar input sequences, thereby enhancing the overall responsiveness and throughput of these models in practical applications.
Continuous Batching
Infery-LLM, equipped with state-of-the-art (SOTA) performance capabilities, excels in executing continuous batching with remarkably low overhead. This process is designed to handle variable-length sequences by grouping them together in an efficient manner. As soon as a response is generated for a sequence, it is swiftly replaced by a new sequence, optimizing the batching process. This mechanism ensures that every generated token is actively utilized and that hardware consistently operates at its maximum batch size.This translates to enhanced resource efficiency, particularly in terms of hardware utilization, ensuring that processing power is fully harnessed for continuous, active decoding. This blend of high-capacity handling at large batch sizes and low-latency performance for smaller batches caters to diverse operational needs and scenarios.
Optimized CUDA Kernels
Infery-LLM leverages custom-optimized CUDA kernels to substantially improve the efficiency of LLMs, particularly during the critical prefill and decoding stages of text generation. These stages are essential for delivering accurate and contextually relevant outputs from LLMs. However, they are also computationally demanding, substantially contributing to the overall cost of LLM inference. Infery-LLM addresses this challenge by employing CUDA kernels that are specifically optimized for grouped query attention, a technique commonly employed in LLMs such as DeciLM-7B and Mistral-7B. This optimization allows for more efficient handling of the queries in the attention layers, resulting in faster processing and reduced latency.
The custom CUDA kernels can be configured to various decoder architectures, making Infery-LLM versatile and suitable for a wide range of LLMs with different structural designs. This adaptability is crucial, as it allows for the optimization to be effective regardless of the specific characteristics or complexities of the decoder in use. By focusing on speeding up the prefill and decoding stages, Infery-LLM ensures that the generation process is not only faster but also maintains the high quality of outputs expected from advanced LLMs.
Getting Started with Infery-LLM and DeciLM-7B
Infery-LLM supports not only Deci-built models like DeciLM-7B and DeciCoder 1B, but also common open-source LLMs, including Mistral 7B and Llama 2 variants.
In the following code snippets, you can see just how easy it is to speed up your LLM models with Infery-LLM:
Run an InferyLLM server:
# Serve Deci/DeciLM-7b (from HF hub) on port 9000 infery-llm serve --model-name Deci/DeciLM-7b --port 9000
Simple prompting of the server:
from infery_llm.client import LLMClient
client = LLMClient("http://0.0.0.0:9000")
result = client.generate(“Once upon a time”)
Conclusion
Infery-LLM addresses the challenge of high LLM inference costs, paving the way for more efficient and cost-effective applications. From enhancing advanced chatbots to facilitating large-scale content creation, Infery-LLM empowers businesses and AI teams to harness the complete capabilities of LLMs, bypassing the traditional complexities and cost constraints associated with their deployment and operation.
For those interested in experiencing the full potential of Infery-LLM, we invite you to get started today.