In an era where language models are becoming integral to how we interact with technology, Deci is excited to unveil DeciLM-7B . Licensed under Apache 2.0, DeciLM-7B emerges as the fastest and most proficient 7-billion-parameter base LLM available today, redefining the benchmarks for speed and accuracy.
DeciLM-7B at a Glance
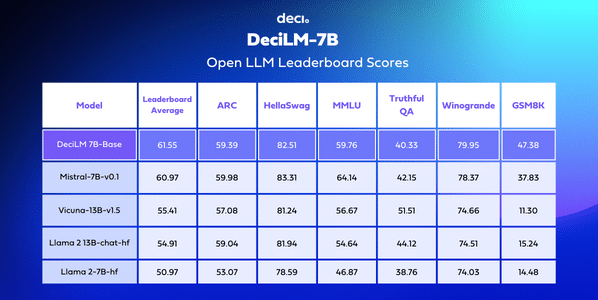
- Unparalleled Accuracy: Achieving an average score of 61.55 on the Open LLM Leaderboard, DeciLM-7B surpasses its competitors in the 7 billion-parameter class, including the previous frontrunner, Mistral 7B. This accuracy improvement can potentially lead to more reliable and precise responses in various applications, from customer service bots to complex data analysis.
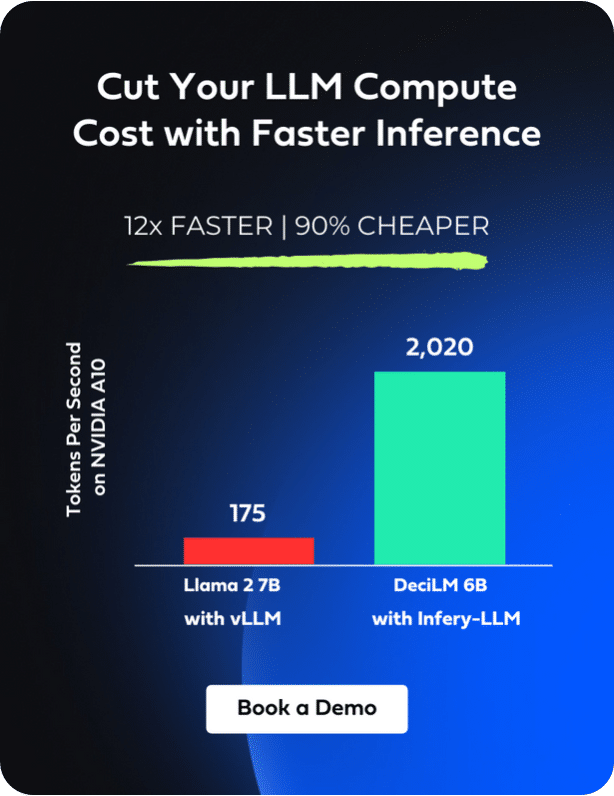
- Enhanced Throughput Performance: In a head-to-head PyTorch benchmark, DeciLM-7B demonstrates a notable performance enhancement, outpacing Mistral 7B with a 1.7x higher throughput and surpassing Llama 2 7B by 2.78x in handling sequences of 2048 tokens in both input and output when running on NVIDIA A10 GPUs.
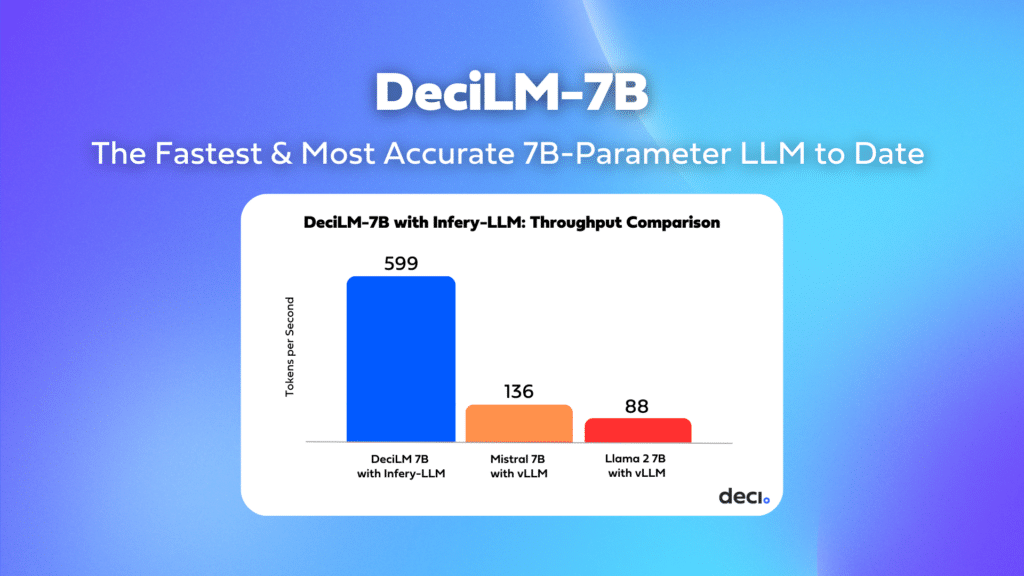
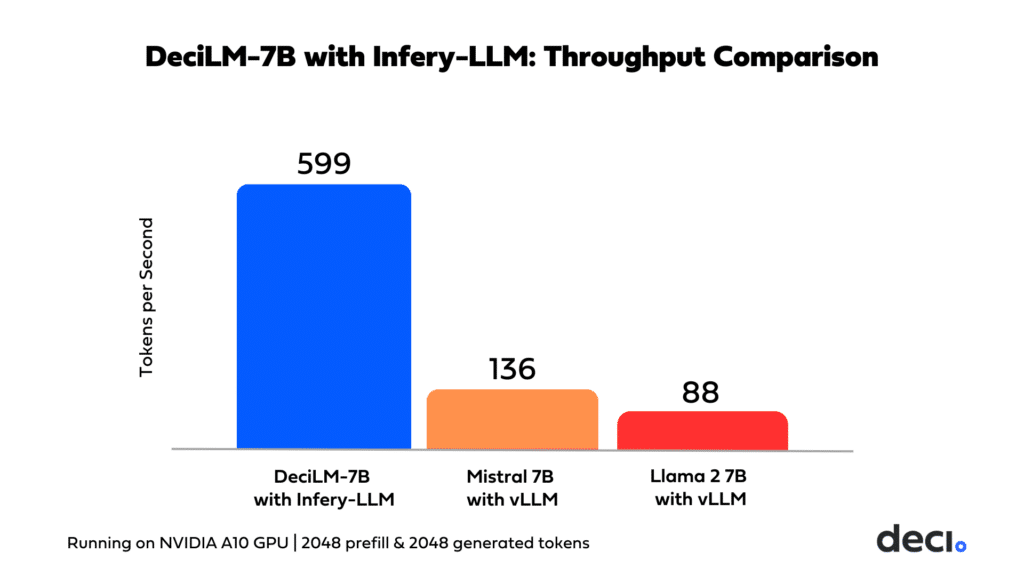
- Accelerated Speed with Infery-LLM: DeciLM-7B performance can be further accelerated as a result of its synergistic relationship with Infery-LLM, Deci’s inference SDK, designed to deliver high throughput, low latency, and cost-effective inference on widely available GPUs. This powerful duo sets a new standard in throughput performance, achieving speeds 4.4x greater than Mistral 7B with vLLM. This synergy is highly beneficial for sectors that demand the capacity to serve numerous customers concurrently. The integration of DeciLM-7B with Infery-LLM creates an environment where high-speed, high-volume customer interactions become a reality. This is especially crucial in sectors like telecommunications, online retail, and cloud services, where the ability to respond to a massive influx of customer inquiries in real-time can significantly enhance user experience and operational efficiency.
- Innovative Architecture: Developed with the assistance of our Neural Architecture Search-powered engine, AutoNAC, DeciLM-7B employs variable Grouped Query Attention, a breakthrough in achieving an optimal balance between accuracy and speed.
- Instruction-Tuned Variant: DeciLM-7B was instruction-tuned using LoRA on the SlimOrca dataset. The resulting model, DeciLM-7B-instruct, achieves an average of 63.19 on the Open LLM Leaderboard and is one the best 7B instruct models obtained using simple LoRA fine-tuning, without relying on preference optimization techniques such as RLHF and DPO.
- Language (NLP): English
- License: Apache 2.0
Businesses can leverage DeciLM-7B ’s remarkable combination of efficiency and accuracy to create more effective, user-friendly AI tools at a lower cost, driving innovation across sectors. From enhancing high-volume customer service with real-time chatbots and personalized recommendations to facilitating workflow automation for text-heavy professional domains, DeciLM-7B paves the way for smarter, more responsive, cost-effective, and scalable AI solutions.
Join us as we delve deeper into the capabilities and potential of DeciLM-7B and its instruction-tuned variant, DeciLM-7B-Instruct.
Superior Accuracy
DeciLM-7B is among the top text generation models in the 7 billion-parameter class in terms of both accuracy and throughput. DeciLM 7B achieves an average score of 61.55 on the Open LLM Leaderboard, surpassing Mistral 7B. It also scores higher than popular 13 billion-parameter models, such as Llama 2 and Vicuna.
Enhanced Throughput and Efficiency
DeciLM-7B is a highly efficient language model, designed for handling large batches with impressive throughput. The table below provides a comprehensive look at DeciLM-7B’s performance across different scenarios, including operations on both NVIDIA A10G and NVIDIA A100 GPUs. It further breaks down the results based on tasks involving a prompt and generation length of either 512 or 2048 tokens, offering a clear view of its capabilities under varying conditions.
| Inference Tool | Hardware | Prompt Length | Generation Length | Generated tokens/sec | Batch Size |
| HF (Pytorch) | A100 (SXM4-80GB-400W) | 512 | 512 | 1174 | 352 |
| HF (Pytorch) | A100 (SXM4-80GB-400W) | 2048 | 2048 | 328 | 72 |
| HF (Pytorch) | A10G | 512 | 512 | 400 | 48 |
| HF (Pytorch) | A10G | 2048 | 2048 | 97 | 8 |
The Infery-LLM Edge: Unparalleled Acceleration at High Volumes
The integration of the Infery-LLM optimization and Inference SDK takes DeciLM-7B’s performance to new heights. DeciLM-7B combined with Infery-LLM achieves a 4.4x increase in throughput over Mistral 7B and a 5.8x increase in throughput over Llama-2-7B. This comparison holds when Mistral 7B and Llama-2-7B are augmented with inference and serving libraries such as vLLM.
The synergy between DeciLM-7B and Infery-LLM’s suite of advanced optimization techniques, including selective quantization, optimized beam search, continuous batching, and custom kernels, enable high speed inference even at high batches. This capability is key for sectors like telecommunications, online retail, and customer service, where the ability to respond to a massive influx of customer inquiries in real-time can significantly enhance user experience and operational efficiency.

Cost-Effective Deployment with DeciLM-7B
Opting for DeciLM-7B in conjunction with Infery-LLM isn’t just a step towards better performance; it’s also a strategic financial decision. This combination not only enhances the model’s capabilities but significantly reduces costs compared to the solutions offered by other inference endpoint providers. The economic efficiency of DeciLM-7B and Infery-LLM is an ideal solution for businesses focused on building, deploying, and scaling LLM-based applications while minimizing compute costs.
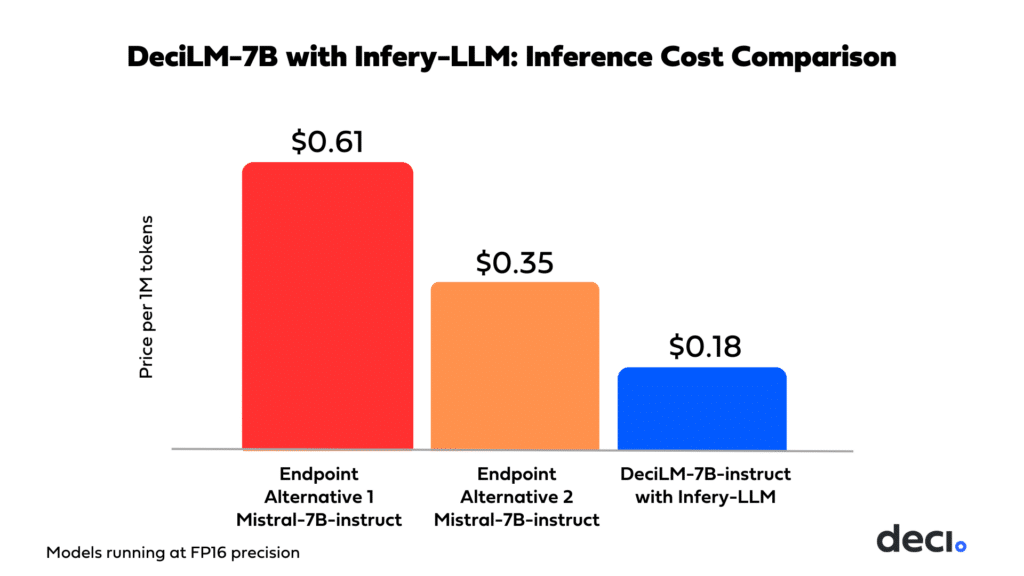
With the proficiency displayed by DeciLM-7B and the accelerated performance afforded by Infery-LLM, the applications are vast across diverse industries, helping to revolutionize operations and drive innovation. In the realm of customer service, this combination can power sophisticated chatbots that understand and respond to customer queries more efficiently, enhancing user experience. Within text and research-heavy professional domains such as healthcare, legal, marketing, and finance, the combination of DeciLM-7B and Infery-LLM can be particularly impactful, undertaking tasks such as text summarization, predictive analytics, document analysis, trend forecasting, and sentiment analysis.
Accessibility: DeciLM-7B’s Apache 2.0 License
In a move towards greater transparency and accessibility in the AI field, DeciLM-7B is released under a commercial license of Apache 2.0, making it available to the open-source community for commercial use. This step aligns with our mission to democratize AI and make it affordable and accessible to everyone.
DeciLM-7B’s Architectural Advantage: The Role of Variable Grouped Query Attention
DeciLM-7B’s superior performance is rooted in its strategic implementation of variable Grouped Query Attention (GQA), a significant enhancement over traditional Multi-Query Attention (MQA) and standard GQA.
Multi-Query Attention (MQA) and Its Limitations
MQA involves multiple query heads sharing the same keys and values, reducing memory usage and computational overhead. While this design improves inference speed, it can sometimes compromise model quality, as the uniform key-value pairs across all heads limit the model’s ability to capture diverse data patterns and relationships.
Grouped Query Attention: An Improved Approach
GQA addresses MQA’s limitations by grouping queries and allowing each group to have its distinct set of keys and values. This approach offers a more nuanced attention mechanism, as different groups can focus on varied aspects of the input data. GQA thus strikes a more effective balance between computational efficiency and the quality of the model, leading to better accuracy without a significant sacrifice in speed.
Variable GQA in DeciLM-7B: Optimizing the Trade-off
DeciLM-7B elevates this approach with variable GQA. While maintaining a consistent number of queries/heads per layer (32), it introduces variability in the GQA group parameter across different layers. This means some layers may operate similarly to MQA with a single group, while others use multiple groups, optimizing the attention mechanism according to the specific needs of each layer. This layer-specific variation allows DeciLM-7B to achieve an optimal speed-accuracy balance.
The NAS Engine Behind DeciLM-7B: AutoNAC
The architecture of DeciLM-7B was developed using Deci’s advanced Neural Architecture Search (NAS) engine, AutoNAC. Traditional NAS methods, while promising, typically require extensive computational resources. AutoNAC circumvents this challenge by automating the search process in a more compute-efficient manner.
This engine has played a key role in developing a variety of high-efficiency models across the AI spectrum. This includes the code generation LLM, DeciCoder 1B, the ultra-efficient text-to-image model DeciDiffusion 1.0, and the state-of-the-art object detection and pose estimation models YOLO-NAS and YOLO-NAS pose. Specifically for DeciLM-7B, AutoNAC was crucial in determining the optimal configuration of the GQA group parameters across each transformer layer, ensuring the model’s architecture is ideally suited for its intended tasks.
Conclusion
We believe and hope that DeciLM-7B’s exceptional performance, coupled with significant cost savings and a commitment to open-source principles, will lead to a significant advancement in the development of LLM-based applications. As we continue to push the boundaries of what’s possible in AI, DeciLM-7B stands as a testament to our commitment to innovation and accessibility in the field.
- Dive Deeper: Delve into our fine-tuning notebook for a detailed guide on fine-tuning DeciLM-7B.
- Get Started: Access and download the model seamlessly from the Hugging Face repository.
Interested in exploring the synergistic benefits of DeciLM-7B and Infery-LLM further? We encourage you to get started today.