
Quick links:
- GitHub ReadMe: https://github.com/Deci-AI/super-gradients/blob/master/YOLONAS-POSE.md
- Fine tuning notebook: https://colab.research.google.com/drive/1agLj0aGx48C_rZPrTkeA18kuncack6lF
- Inference notebook: https://colab.research.google.com/drive/1O4N5Vbzv0rfkT81LQidPktX8RtoS5A40
Introduction
At Deci, our mission has always been about advancing the technological horizon of deep learning and ensuring that the broader community benefits from the cutting-edge tools we develop. Living up to this promise, we’re elated to introduce our newest contribution to pose estimation: the YOLO-NAS Pose model.
The field of pose estimation is integral to computer vision, serving a spectrum of crucial applications. From healthcare’s need to monitor patient movements and the intricate analysis of athlete performances in sports, to creating seamless human-computer interfaces and enhancing robotic systems – the demands are vast. Not to mention, sectors like entertainment and security where swift and accurate posture detection is paramount.
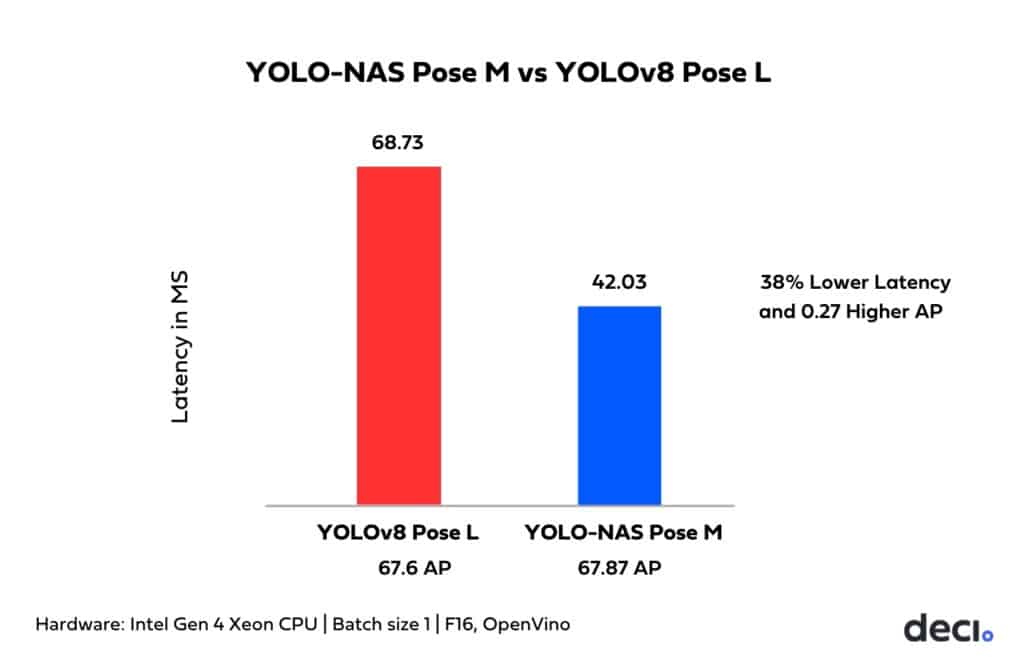
Earlier this year, Deci introduced YOLO-NAS, a groundbreaking object detection foundation model that gained widespread recognition. Building on YOLO-NAS, we are releasing its pose estimation sibling: YOLO-NAS Pose. This model offers a superior latency-accuracy balance compared to YOLOv8 Pose. Specifically, the medium-sized version, YOLO-NAS Pose M, outperforms the large YOLOv8 variant with a 38.85% reduction in latency on an Intel Xeon 4th gen CPU, all while achieving a 0.27 boost in [email protected] score.
This remarkable combination of speed and accuracy is no accident. It emerges from Deci’s proprietary NAS (Neural Architecture Search) engine, AutoNAC, coupled with cutting-edge training methodologies. Together, they elevate YOLO-NAS Pose to redefine the standards of pose estimation.
Advancing the Efficiency Frontier of Pose Estimation with YOLO-NAS Pose
YOLO-NAS Pose offers four distinct size variants, each tailored for different computational needs and performances:
| Number of Parameters (In millions) | [email protected] | Latency (ms) Intel Xeon gen 4th (OpenVino) | Latency (ms) Jetson Xavier NX (TensorRT) | Latency (ms) NVIDIA T4 GPU (TensorRT) | |
| YOLO-NAS N | 9.9M | 59.68 | 14 | 15.99 | 2.35 |
| YOLO-NAS S | 22.2M | 64.15 | 21.87 | 21.01 | 3.29 |
| YOLO-NAS M | 58.2M | 67.87 | 42.03 | 38.40 | 6.87 |
| YOLO-NAS L | 79.4M | 68.24 | 52.56 | 49.34 | 8.86 |
These variants collectively establish a new efficiency frontier for pose estimation, pushing the envelope of what’s achievable in terms of performance and efficiency. The strides made by YOLO-NAS Pose in this frontier are depicted in the following graph.
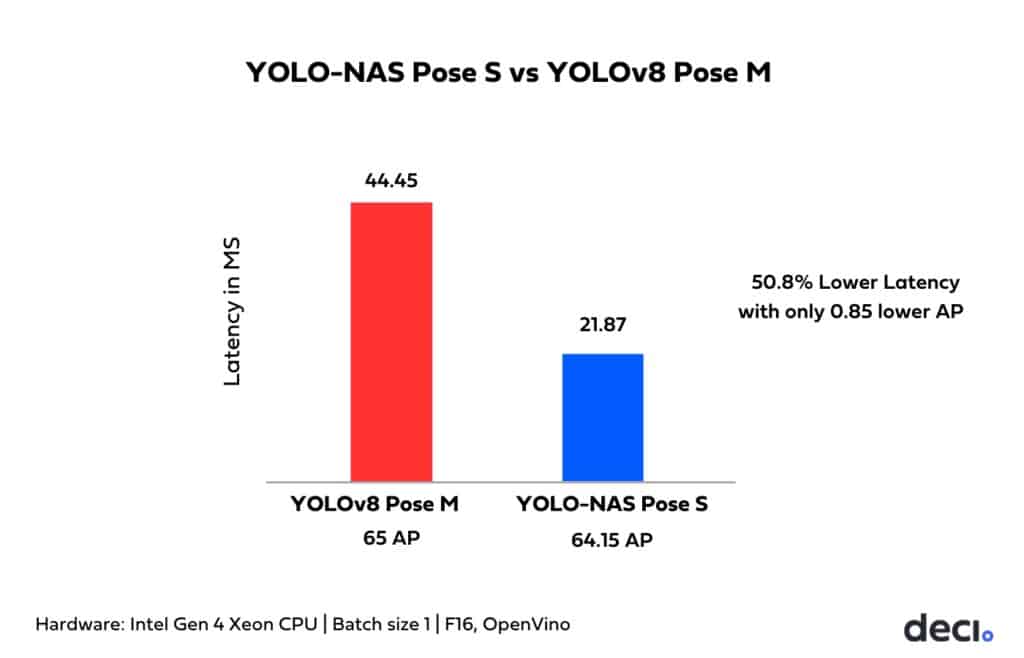
All the four variants deliver significantly higher accuracy with similar or better latency compared to their YOLOv8 Pose equivalent model variants. When comparing across variants, a significant boost in speed is evident. For example, the YOLO-NAS Pose M variant boasts 38% lower latency and achieves a +0.27 AP higher accuracy over YOLOV8 Pose L, measured on Intel Gen 4 Xeon CPUs. YOLO-NAS Pose excels at efficiently detecting objects while concurrently estimating their poses, making it the go-to solution for applications requiring real time insights.
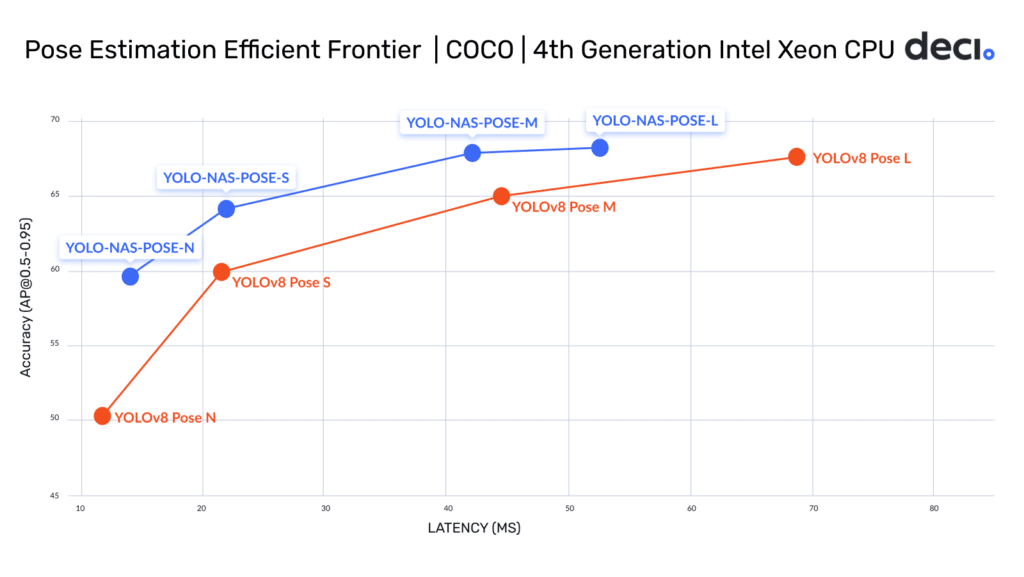
Measured on 4th generation Intel Xeon CPUs, OpenVino. (Batch size 1, FP 16).
Further into this technical blog, we dive into the intricacies of YOLO-NAS Pose’s architecture, post-processing, and training. Our aim? To offer you a transparent glimpse into the mechanisms that propelled its groundbreaking performance.
A New Pose Estimation Paradigm: Simultaneous Detection and Estimation
Two Traditional Pose Estimation Paradigms
In the realm of pose estimation, two primary methodologies have traditionally dominated:
Top-down methods: The process begins by first pinpointing the object (often a person) within the scene. Following this identification, the algorithm then delves into detecting its specific keypoints. This method shines in scenarios with a smaller number of subjects, delivering remarkable accuracy. However, its inherent drawback lies in scalability. As the number of subjects or objects in a scene grows, so do the computational demands, introducing latency and reducing real-time responsiveness.
Bottom-up methods: Taking an inverted approach, these methods first catalog all discernible key points across the scene. Once this repository of key points is established, the algorithm pieces them together to recreate individual poses. This technique is notably efficient in situations with large crowds. However, its Achilles’ heel emerges when subjects overlap or when certain body parts remain occluded. Furthermore, the need for detailed post-processing to consolidate the key points into coherent poses adds layers of complexity.
The YOLO-NAS Pose Paradigm
YOLO-NAS Pose follows neither the top-down or bottom-up methods. Instead, it executes two tasks simultaneously: detecting persons and estimating their poses in one swift pass. This unique capability sidesteps the two-stage process inherent to many top-down methods, making its operation akin to bottom-up approaches. Yet, differentiating it from typical bottom-up models like DEKR, YOLO-NAS Pose employs a streamlined postprocessing, leveraging class NMS for predicted person boxes. The culmination of these features delivers a rapid model, perfectly primed for deployment on TensorRT.
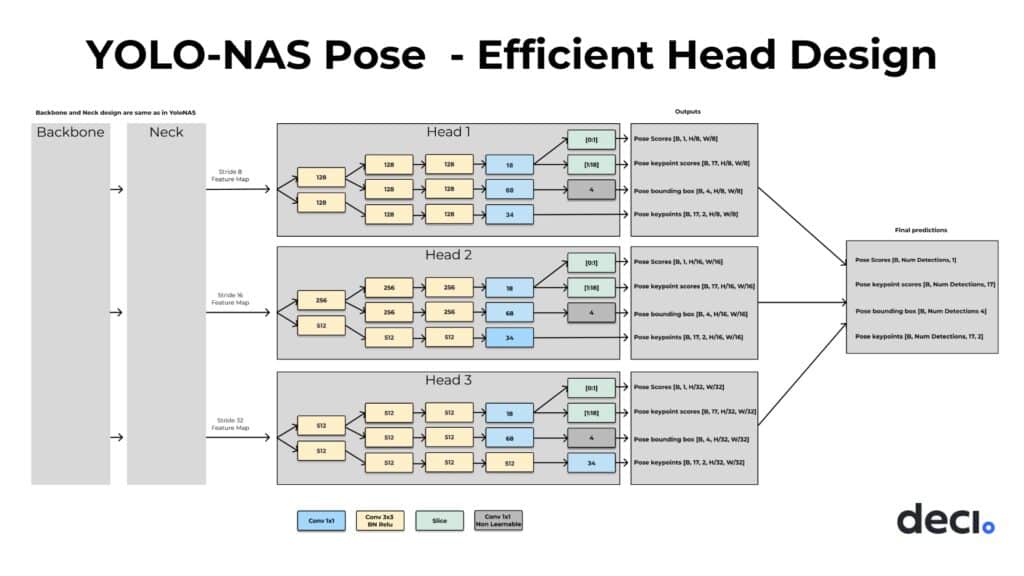
YOLO-NAS Pose’s Architectural Innovation
YOLO-NAS Pose’s architecture is based on the YOLO-NAS architecture used for object detection. Both architectures share a similar backbone and neck design, but what sets YOLO-NAS Pose apart is its innovative head design crafted for a multi-task objective: simultaneous single-class object detection (specifically, detecting a person) and the pose estimation of that person.
Crafting a Novel Head for Simultaneous Detection and Estimation
Through extensive experimentation, we discerned the pivotal role the head design plays. Achieving a harmonious balance between robust runtime performance and the capacity to make precise pose and bounding box predictions is a nuanced task. To find an optimal, novel head design, we harnessed AutoNAC, our proprietary NAS-powered engine.
Harnessing AutoNAC for novel head design
Finding an optimal architecture requires navigating the vast architecture search space. But doing so manually is not only tedious but often inefficient. The traditional Neural Architecture Search showed promise in this arena, automating the development of superior neural networks. However, its insatiable thirst for computational resources rendered it impractical for many, confining its usage to a select few with vast computational power.
AutoNAC emerged as a transformative solution to this challenge. Developed by Deci, AutoNAC is a streamlined and compute-efficient version of NAS, designed to efficiently discover optimized architectures tailored to specific hardware.
What truly distinguishes AutoNAC is its capacity to systematically and swiftly explore potential architectures and its ability to predict a network’s accuracy without having to train it. It eliminates reliance on human intuition, instead employing its algorithmic prowess to unearth novel configurations that strike the perfect balance between accuracy, speed, and complexity. This efficiency has been pivotal, enabling the creation of a myriad of groundbreaking models like YOLO-NAS, the state-of-the-art code generation LLM, DeciCoder, the hyper-efficient text generation model, DeciLM 6B, and the advanced text-to-image model, DeciDiffusion.
In the case of YOLO-NAS Pose, we employed AutoNAC to find the optimal head design, ensuring powerful representation while adhering to predefined runtime constraints. Our search space included several hyperparameters:
- Number of Conv-BN-Relu blocks for both pose and box regression paths.
- Number of intermediate channels for both paths
- Decision between a shared stem for pose/box regression or distinct stems
Deci’s AutoNAC engine is used to find the most optimal model architectures, it’s noteworthy that in this case, the AutoNAC search was solely focused on the head design.
A Deep Dive into YOLO-NAS Pose’s Advanced Training Process
In training YOLO-NAS Pose to deliver state-of-the-art pose estimation performance, we faced a set of notable training procedures and techniques. Let’s delve into them in detail.
Refining the YOLO-NAS Loss Function
As mentioned above, YOLO-NAS Pose’s architecture is inherently multi-task, with a head designed for simultaneous detection and estimation. To align these tasks during training, we refined the YOLO-NAS loss function, incorporating not only the IoU score of assigned boxes but also the Object Keypoint Similarity (OKS) score of predicted key points compared to the ground truth. This integration compels the model to yield accurate predictions for both bounding box and pose estimation. Additionally, we employed direct OKS regression for training pose estimation, outclassing traditional L1/L2 losses. This method offers several benefits:
- It parallels box IoU, operating within a [0..1] range, signifying pose similarity.
- It encompasses prior knowledge on the ease of annotating specific keypoints. Each keypoint aligns with a unique sigma score, reflecting annotation accuracy variance, and dataset specificity. These scores determine the extent of the OKS penalty for inaccurate predictions.
- Using a loss function that mirrors the validation metric allows us to precisely target and optimize that specific measurement.
Leveraging the YOLO-NAS Weights and Mosaic Data Augmentation
We leveraged the fact that YoloNAS-Pose shares the same backbone as YOLO-NAS model so we used weights of YOLO-NAS to initialize the backbone and neck of the model and trained the final model from there.
We found that mosaic data augmentation, random 90 degree rotations and severe color augmentations improved final AP score by ~2AP.
Additional Training Details
Training Time, Learning Rate, and Batch Size Per Size Variant
| Variant | Training Time | Learning Rate | Batch Size | Remarks |
| YoloNAS-Pose N | 93h | 2e-3 | 60 | Trained from scratch |
| YoloNAS-Pose S | 52h | 2e-3 | 48 | Used YOLO-NAS pre-trained weights |
| YoloNAS-Pose M | 57h | 1e-4 | 32 | Used YOLO-NAS pre-trained weights |
| YoloNAS-Pose L | 80h | 8e-5 | 24 | Used YOLO-NAS pre-trained weights |
General Training Settings
- Training Hardware: 8x NVIDIA GeForce RTX 3090 GPUs with PyTorch 2.0.
- Training Schedule: Up to 1000 epochs with early stopping if no improvement over the last 100 epochs.
- Optimizer: AdamW with Cosine LR decay, reducing LR by a factor of 0.05 by the end.
- Weight Decay: 0.000001 (excluding bias and BatchNorm layers).
- EMA Decay: Beta factor of 50.
- Image Resolution: Processed to 640 pixels on the longest side and padded to 640×640 with (127,127,127) padding color.
Simplified Post Processing
The YOLO-NAS Pose model outputs raw predictions that encompass four key components:
Predicted bounding boxes in the XYXY format,
Detection scores for predicted objects,
Predicted keypoints for 17 distinct body parts given in (X,Y) coordinates, and
Confidence scores for each of these keypoints.
Given that the model is trained to align the two tasks, box detections and pose predictions in the same spatial location are consistent. The first post processing step involves running Non-Maximum Suppression on the box detections and pose predictions, resulting in a list of high confidence predictions. The second step involves selecting the corresponding boxes and poses, which constitute the final output of the model.
Additional Capabilities
YOLO-NAS Pose emerges as a standout in the realm of human pose estimation, offering a blend of flexibility, efficiency, and precision.Beside its unparalleled performance, there are additional key features that make YOLO-NAS Pose shine:
- Seamless Deployment: YOLO-NAS Pose’s deploy-friendly architecture ensures effortless integration, especially with its one-line exportation to ONNX/TRT engines.
- Scenarios with Fluctuating Crowd Density: YOLO-NAS Pose is very suitable for tasks that involve environments with varying numbers of subjects—from solitary individuals to large crowds. Its ability to accurately estimate poses for both single and multiple persons makes it invaluable.
- Comprehensive Solution: In situations where an end-to-end solution is desired to merge both object detection and pose estimation, YOLO-NAS Pose’s integrated capability provides a streamlined approach with an excellent accuracy/latency tradeoff.
YOLO-NAS Pose Availability to the Community
In alignment with our commitment to propel the wider adoption of efficient models, Deci is proud to release YOLO-NAS pose to the community. The YOLO-NAS Pose architecture is available under an open-source license. Its pre-trained weights are available for research use (non-commercial) on SuperGradients, Deci’s PyTorch-based, open-source, computer vision training library. We encourage researchers, developers, and enthusiasts to leverage this state-of-the-art foundation model in their work.
Further, the open-source SuperGradients training toolkit facilitates easier model refinement for specific use cases, broadening its appeal and encouraging its widespread use across different scenarios.
Conclusion
Deci’s groundbreaking YOLO-NAS Pose model stands as a testament to our relentless pursuit of pushing the boundaries in deep learning. By seamlessly blending the benefits of speed, accuracy, and efficiency, this model paves the way for transformative advancements in the realm of human pose estimation. With its distinctive architecture, novel head design, and sophisticated training methodologies, YOLO-NAS Pose is an optimal solution in a myriad of applications.
We’re excited to see what you build with it!
Looking to use YOLO-NAS Pose for a commercial application?
Talk with our team about the commercial license.









