Generative AI models have emerged as a transformative force capable of creating human-like text, images, and code with remarkable precision. As businesses across industries recognize the potential of generative AI to revolutionize their operations and drive revenue growth, the challenges associated with the operational costs and environmental impact of scaling generative AI applications come to the forefront. This article delves into these challenges and discusses ways to make generative AI more scalable and sustainable.
The Challenges of Scaling Generative AI
Generative AI models can create polished, engaging, expert-level outputs, making them invaluable assets in various industries. Their potential to drive business growth or even determine an organization’s survival is recognized by forward-thinking leaders who understand the need to embrace this transformative technology. However, harnessing the full potential of generative AI models through large-scale deployment presents considerable challenges.
The Operational Cost Challenge
Generative AI models are more power-hungry than traditional, non-generative models due to their larger and more computationally complex architectures. Take for instance the GPT-4 model, the exact size of which OpenAI has yet to divulge. But all estimates suggest that this giant model contains at least 5 times the number of parameters of its predecessor, GPT-3, which already boasts a staggering 175 billion parameters.
The high computational demand is further compounded by the fact that generating responses to prompts during inference requires multiple forward passes through the model. The result? Steep training and inference costs. To put it into perspective, the training cost of ChatGPT is estimated to hover around the $4-5 million mark, while a recent analysis suggests that at its current scale, it incurs a hefty inference cost of approximately $700,000 per day.
A noteworthy aspect impacting the cost of generative AI models is the length of prompts. Longer prompts and context windows are desirable, as they provide richer context, personalizing responses and enhancing model accuracy and performance for various applications. However, it’s crucial to note that they also increase the cost of inference. For instance, GPT-4’s operation cost per 1k sampled tokens doubles when the context window expands from 8K to 32K, underlining the correlation between prompt length and cost.
Clearly, the expenses associated with training and training and scaling generative AI applications pose a significant obstacle, restricting scaling to large enterprises with virtually unlimited resources. This leaves many businesses with innovative concepts but limited budgets, unable to fully harness the transformative capabilities of generative AI.
The Environmental Impact and Sustainability Challenge
Another challenge presented by scaling generative AI applications lies in the environmental repercussions of their substantial energy consumption.
Research conducted in recent years has shed light on the significant contribution of the Information and Communications Technology (ICT) sector to global greenhouse gas emissions, estimated to be around 2% to 4%. The energy-intensive nature of today’s mammoth generative models results in a high carbon footprint, which becomes even more pronounced as they increase in size and scale.
How to Meet the Challenges of Scaling Generative AI Models
Reducing the operational and environmental costs associated with scaling generative AI applications requires a multi-faceted approach. Below we explore three promising pathways.
Building Specialized Models
The field of generative AI is witnessing a shift toward making generative models smaller and more computationally efficient without compromising on performance. One promising strategy under examination involves the development of specialized models that are optimized for specific tasks and applications. These models are designed to be more computationally thrifty and can be trained on smaller datasets.
Think of large, general models as ‘Renaissance scholars,’ possessing a wide but possibly surface-level knowledge base. On the other hand, specialized models can be compared to ‘modern-day experts,’ honing in-depth understanding within a distinct domain. While Renaissance scholars have their merits, it’s often the profound insights of modern experts that answer today’s pressing issues. In a similar vein, while the expansive output capabilities of larger models are notable, they may not always provide the most efficient or tailored solution for every scenario.
Adopting specialized models offers practical advantages in inference cost and speed that address the challenges of scaling generative AI applications. By focusing on building specialized models, we can unlock the potential for more accessible, sustainable, and boundary-pushing solutions in the realm of generative AI.
Inference Acceleration through Quantization and Compilation
In addition to building specialized models, techniques like quantization and compilation can optimize generative models, reducing costs and promoting sustainability.
Quantization reduces memory and computational requirements by reducing the precision of numerical values in the model without a significant loss in performance. This technique significantly lowers the cost of inference for both specialized and general generative models.
Compilation is a process where the abstract representation of a neural network (often described in terms of high-level operations or layers) is translated into a form that can be efficiently executed on a specific type of hardware (such as a CPU, GPU, or dedicated AI accelerator). It involves optimizations such as operator fusion that reduce the computational complexity of the model and lead to lower latency and faster inference.
Faster inference enables greater scalability for generative AI applications. When a model can process more prompts per second, the required GPU processing time per query decreases, reducing cloud costs per query. As a result, generative AI applications that leverage models with faster inference capabilities can accommodate increased usage for every dollar spent on compute power.
Moreover, faster inference also reduces the carbon footprint of generative AI applications. Reducing GPU processing time means decreasing the kW consumption per hour which leads to a lower CO2 emission.
The Need for Generative AI Optimization and Scaling Solutions
By implementing the above methods, businesses can effectively reduce the operational and environmental costs associated with scaling generative AI models.
However, developing specialized generative models and implementing optimization techniques necessitates a high degree of technical expertise. Additionally, the process can be time-consuming, even for experienced machine learning professionals with extensive deep learning backgrounds. To mitigate risks, shorten development timelines, and avoid missing market opportunities or losing competitive advantages, companies require rapid and efficient solutions.
Efficiently Scaling Generative AI Workloads with Deci
Deci’s platform provides robust tools, including advanced compilation and quantization, to reduce inference costs and ensure fast and efficient deployment without compromising performance. It enables organizations to scale their generative AI workloads cost-effectively, reducing unnecessary cloud spend while delivering exceptional results.
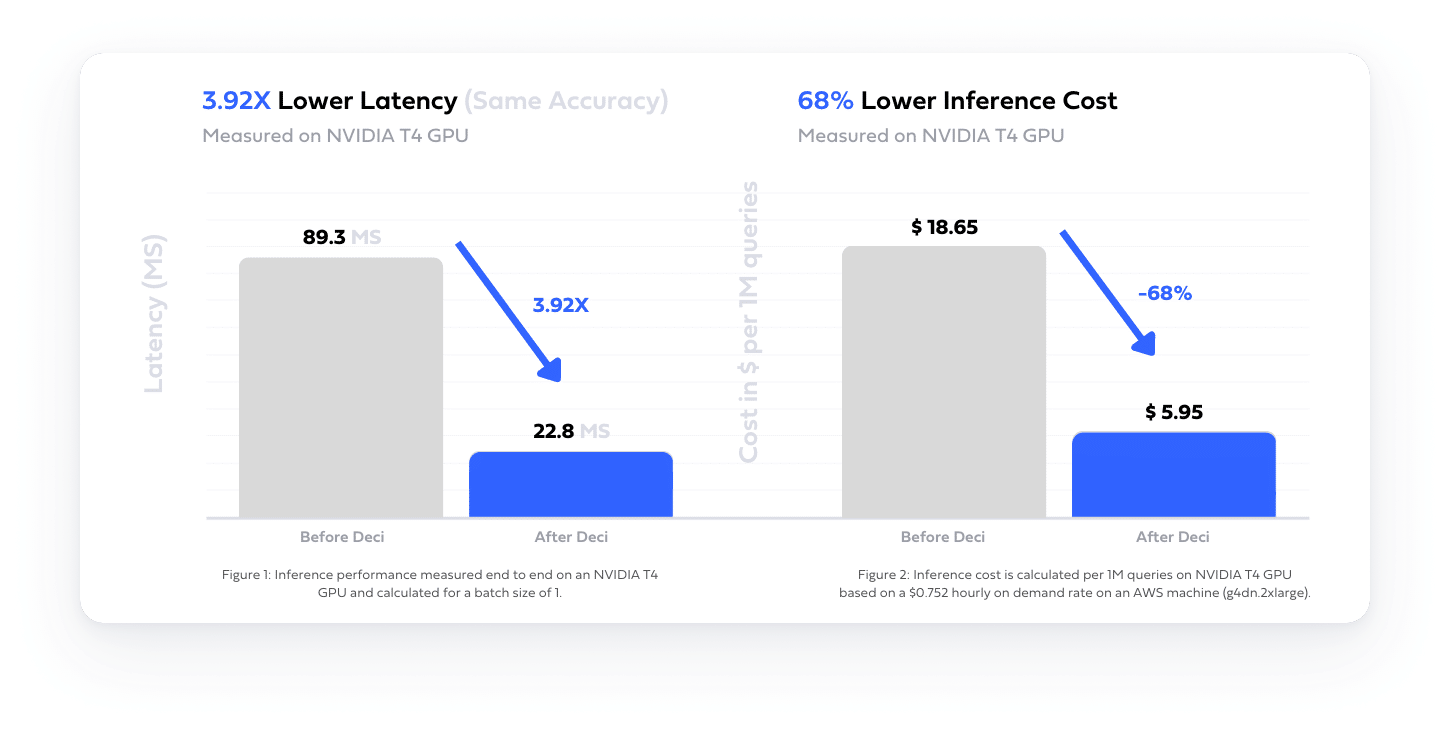
Leveraging Deci’s platform, various companies have substantially improved their model latency, yielding significant reductions in their cloud expenses and carbon footprint. Take, for example, a customer offering an AI platform for text summarization. By utilizing Deci’s capabilities, they managed to shrink their model size by 50% and accelerate latency by 3.92%. This optimization led to a striking 68% decrease in their cloud costs.
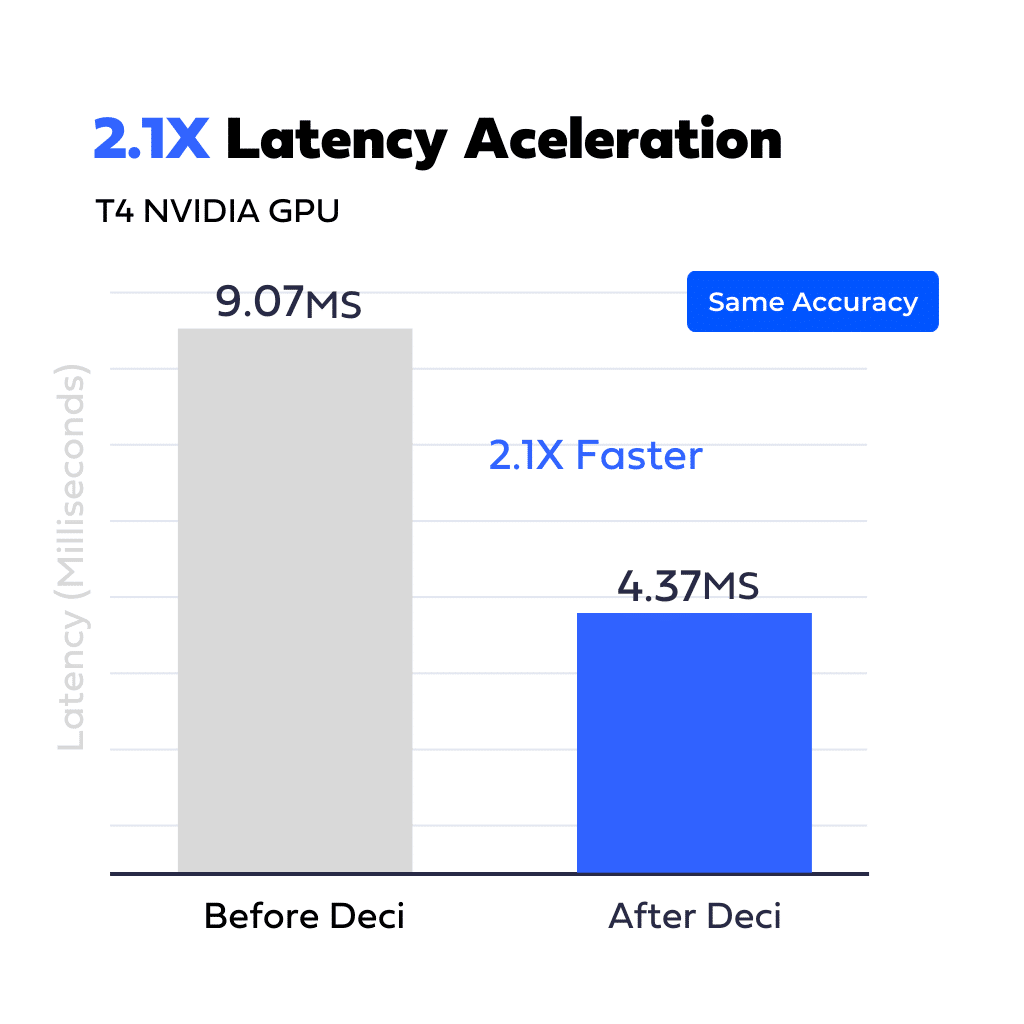
Another customer, offering a video generation application powered by a GAN model for image generation, was struggling to reach their throughput target. By deploying Deci’s robust compilation and quantization tools, they optimized the model’s latency and achieved a performance boost of 2.1x. Consequently, they were able to process their videos using fewer machines, leading to a substantial 40% reduction in their cloud costs.
In addition to optimizing LLMs, Deci’s platform also supports substantially accelerating other generative models such as Stable Diffusion. The following video shows how Deci’s optimized Stable Diffusion Stable model achieves x3.3 more iterations per second leading to a 66% reduction in cloud costs and a 30.8% reduction in CO2 kg emitted per year.
The significant enhancements achievable through Deci’s platform play a pivotal role in democratizing generative AI. By making inference more efficient, the platform allows emerging tech enterprises and startups across various industries to quickly and efficiently scale their applications. This empowers them to win new markets, establish or fortify their competitive edge, and deliver superior value to their customers through improved products.
To learn more about Deci’s solution, book a demo today.