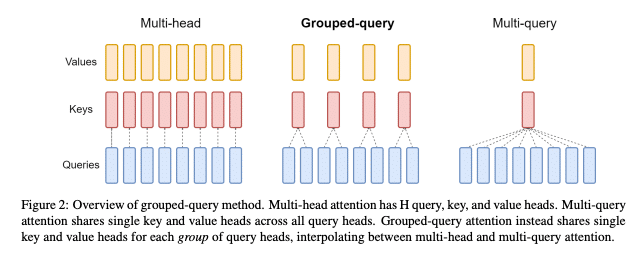
Grouped Query Attention (GQA) is a technique introduced to optimize the balance between computational efficiency and model performance within Transformer architectures. Developed as an evolution of the Multi-Query Attention (MQA) technique, GQA addresses the inefficiencies inherent in the traditional attention mechanism using Multi-Head Attention (MHA), particularly concerning memory bandwidth demands during inference.
Multi-Query Attention is an earlier attempt to address these inefficiencies by employing a single key-value head across multiple query heads. While effective in speeding up inference, MQA can lead to quality degradation due to reduced capacity for capturing complex patterns, compared to MHA.
GQA adopts an intermediate approach between MHA and MQA, reducing the number of key-value heads without diminishing the model’s capacity to capture complex data relationships. This reduction is achieved by dividing the query heads into groups, each sharing a single key and value head.
Key Features of GQA:
- Query Head Grouping: GQA partitions query heads into groups, with each group sharing a single key and value head. This grouping significantly reduces the computational and memory overhead compared to traditional MHA, allowing for faster inference times without a substantial loss in model quality.
- Memory Bandwidth Optimization: By minimizing the number of key-value pairs across groups, GQA mitigates the memory bandwidth challenge associated with key-value caching in MHA. This optimization ensures efficient loading and storing of data during inference, thereby enhancing overall computational efficiency.
- Balanced Trade-off: GQA strikes a balance between the efficiency of MQA and the model expressiveness of MHA. It maintains a higher level of model capacity than MQA while offering speed benefits.

Variable GQA is an advanced version of GQA, where the number of key-value heads per attention layer is not fixed. This results in an even better balance between speed and accuracy than standard GQA. This technique is used in the DeciCoder-6B and DeciLM-7B models.