The T5 model is built on the Transformer architecture. Its primary component is the self-attention mechanism, which calculates the weights based on the pairwise affinity between the query of each element and the keys of all other elements in the sequence. This allows the model to focus differently on various parts of the input when processing each element. Refer this article to get more details on the math and more indepth intuition behind the attention mechanism.
The original Transformer model was designed as an encoder-decoder architecture, primarily for sequence-to-sequence tasks. However, more recent versions of Transformer models have been simplified to include just a single stack of Transformer layers. These streamlined models are specifically optimized for tasks like language modeling and text classification.
The T5 closely follows the original Transformer’s encoder-decoder structure, with some modifications. It maps an input sequence of tokens to a sequence of embeddings, which is then passed to the encoder. This encoder is made up of blocks, each containing a self-attention layer followed by a shallow feed-forward network.
Layer normalization is applied to each subcomponent’s input, and a residual skip connection adds each subcomponent’s input to its output.
The decoder mirrors the encoder but includes a standard attention mechanism post each self-attention layer, focusing on the encoder’s output.
The self-attention mechanism in the decoder uses autoregressive or causal self-attention, allowing the model to attend only to past outputs.
One of the T5’s unique features is its position embedding scheme. While the original Transformer used fixed or learned absolute position embeddings, the T5 employs relative position embeddings. These produce different learned embeddings based on the offset between the key and query in the self-attention mechanism. This model also uses a simplified form of position embeddings, where each embedding is a scalar added to the corresponding logit for computing attention weights.
Expected Input
The T5 model expects textual prompts that are tailored to specific NLP tasks. The format of the input is designed to guide the model in understanding the desired task:
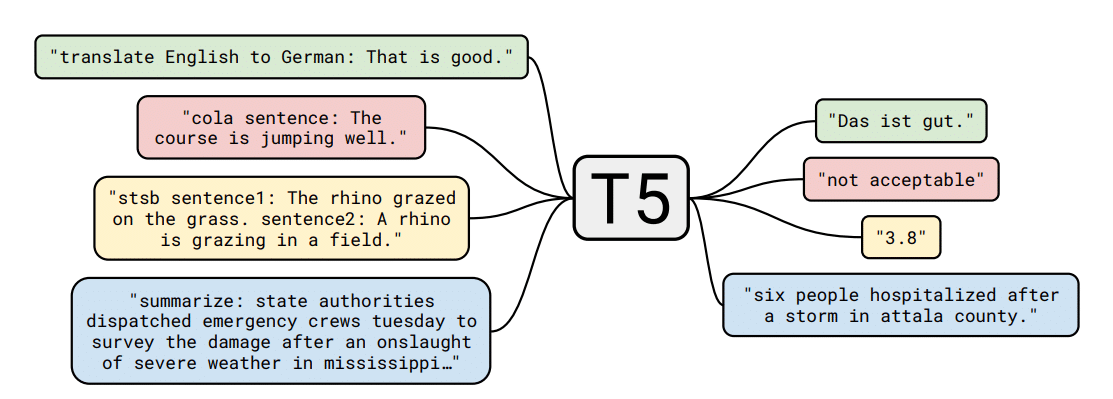
For translation tasks, the input is structured as “translate [source language] to [target language]: [sentence]”. An example would be “translate English to German: ‘That is good.'”.
For summarization tasks, the input is given as “summarize: [text]”. For instance, “summarize: state authorities dispatched emergency crews Tuesday to survey the damage after an onslaught of severe weather in Mississippi…”.
For sentiment analysis or classification tasks, the input might be given in the format “cola sentence: [sentence]”. An example is “cola sentence: The course is jumping well.”.
For tasks like semantic textual similarity, the input could be “stsb sentence1: [sentence1] sentence2: [sentence2]”. An example is “stsb sentence1: The rhino grazed on the grass. sentence2: A rhino is grazing in a field.”.
The model’s flexibility allows it to handle a wide range of tasks, and the input format plays a crucial role in directing the model’s attention to the desired output format.
Expected Output
The T5 model produces textual outputs corresponding to the specified task:
For translation tasks, the output is the translated text in the target language. Using the earlier example, the output would be the translated text in German, such as “Das ist gut.”.
For summarization tasks, the output is a concise summary of the provided text. For the example mentioned, the output might be “six people hospitalized after a storm in Attala county.”.
For sentiment analysis or classification tasks, the output is a classification label or sentiment score. For instance, the output for the “cola sentence” example could be “not acceptable”.
For semantic textual similarity tasks, the output is a similarity score between the two provided sentences. Using the previous example, the output might be “3.8”, indicating the degree of similarity between the two sentences.
In essence, the T5 model’s output is a textual representation that aligns with the specified task, providing relevant information or results based on the input prompt.
History and Applications
Originated from Google Research Brain Team.
Used for a variety of NLP tasks including but not limited to translation, question answering, and summarization.
The model’s unified approach has made it one of the benchmarks in NLP.
Metrics and Performance
Training and Evaluation Data, and Metrics
The model was trained using a combination of supervised and unsupervised tasks, with a significant emphasis on the C4 dataset. This dataset was derived from web-extracted text from Common Crawl, and various heuristics were employed to filter the content. The model was pre-trained on C4 for 524,288 steps before fine-tuning. The training process utilized a maximum sequence length of 512 and a batch size of 128 sequences. This approach was designed to ensure that the model never encountered repeated data during pre-training.
For validation, the model was tested across several benchmarks, including GLUE, SuperGLUE, and SQuAD. These benchmarks are renowned for their rigorous evaluation of NLP models across various tasks, providing a comprehensive assessment of the model’s capabilities.
The model’s performance was evaluated using standard NLP benchmarks. On the GLUE benchmark, the model achieved an impressive score of 82.9.
For the SQuAD benchmark, which assesses a model’s question-answering capabilities, the model secured a score of 80.65.
These scores are indicative of the model’s robustness and its ability to generalize across different NLP tasks.
The results also underscored the importance of pre-training. When the model was trained without any pre-training, there was a significant drop in performance across almost all benchmarks. This highlights the value of transfer learning and the benefits it brings, especially for tasks with limited data.
Performance of the different pre-training objectives
Comparison with variants of BERT-style pre-training objective
Overall the largest (11 billion parameter) T5 model performed best among across all other model size variants and across all tasks. It set a new standard by achieving an average GLUE score of 90.3, outperforming previous state-of-the-art models, especially in challenging tasks like MNLI, RTE, and WNLI.
Despite its large size, our 11B model variant is computationally more efficient than ensembled models like ALBERT. In the SQuAD benchmark, we surpassed the previous best score by over one point in the Exact Match metric.
Inference Performance
With its comprehensive training on the C4 dataset and validation across multiple benchmarks, t5 showcases its potential as a versatile tool for various NLP tasks. The emphasis on transfer learning and the benefits it brings, especially in data-limited scenarios, makes it a valuable asset for the NLP community.
How to Use
Prerequisites:
Before you begin, ensure you have the necessary dependencies installed. If not, you can install them using pip:
pip install transformers tensorflow
The transformers library provides interfaces for various pre-trained models, including T5. tensorflow is the backend on which the T5 model in this example runs.
T5 requires its specific tokenizer. Load the tokenizer and the model using the from_pretrained method. For this example, we’ll use the ‘t5-small’ version, but you can replace it with other versions if needed.
# import tensorflow as tf
from transformers import T5Tokenizer, TFT5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('t5-small')
model = TFT5ForConditionalGeneration.from_pretrained('t5-small')
input_text = "translate English to German: Hello, World!"
input_ids = tokenizer(input_text, return_tensors="tf").input_ids
outputs = model.generate(input_ids)
translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(translated_text)
The return_tensors=”tf” argument ensures that the tokens are returned as TensorFlow tensors. The outputs variable contains the model’s generated output in tokenized form. Decode this output to get the translated text or the result of any other text-to-text task.
Remember to adjust the model and tokenizer type if you’re using a different variant of T5 or another language model.