YOLO-NAS Pose is a pose estimation model trained on the COCO2017 dataset.
Publishers Deci AI Team
Submitted Version November 7, 2023
Latest Version N/A
Size N/A
Pose Estimation
Overview
Performance
How to Use
License
Resources
Overview
YOLO-NAS Pose is a pose estimation model trained on the COCO2017 dataset. Emerging from Deci’s proprietary NAS (Neural Architecture Search) engine, AutoNAC, coupled with cutting-edge training methodologies, it offers a superior latency-accuracy balance compared to YOLOv8 Pose. Specifically, the medium-sized version, YOLO-NAS Pose M, outperforms the large YOLOv8 variant with a 38.85% reduction in latency on an Intel Xeon 4th gen CPU, all while achieving a 0.27 boost in [email protected] score.
Model Highlights
Task: Pose estimation
Model type: Deep Neural Network
Languages (NLP): PyTorch
Dataset: Trained on COCO2017 dataset
Model Architecture
In pose estimation, two primary methodologies have traditionally dominated: top-down methods and bottom-up methods. YOLO-NAS Pose follows neither. Instead, it executes two tasks simultaneously: detecting persons and estimating their poses in one swift pass. This unique capability sidesteps the two-stage process inherent to many top-down methods, making its operation akin to bottom-up approaches. Yet, differentiating it from typical bottom-up models like DEKR. YOLO-NAS Pose employs a streamlined postprocessing, leveraging class NMS for predicted person boxes. The culmination of these features delivers a rapid model, perfectly primed for deployment on TensorRT.
YOLO-NAS Pose’s architecture is based on the YOLO-NAS architecture used for object detection. Both architectures share a similar backbone and neck design, but what sets YOLO-NAS Pose apart is its innovative head design crafted for a multi-task objective: simultaneous single-class object detection (specifically, detecting a person) and the pose estimation of that person. AutoNAC wasa employed to find the optimal head design, ensuring powerful representation while adhering to predefined runtime constraints.
YOLO-NAS Pose offers four distinct size variants, each tailored for different computational needs and performances:
YOLO-NAS Pose takes an image or video as an input.
Expected Output
YOLO-NAS Pose outputs bounding boxes and confidence scores for detected persons and predicted coordinates (X,Y) for each keypoint of the skeleton and confidence score of each keypoint (indicating whether model is confident specific keypoint is visible).
History and Applications
The field of pose estimation is integral to computer vision, serving a spectrum of crucial applications. From healthcare’s need to monitor patient movements and the intricate analysis of athlete performances in sports, to creating seamless human-computer interfaces and enhancing robotic systems – the demands are vast. Not to mention, sectors like entertainment and security where swift and accurate posture detection is paramount.
Earlier this year, Deci introduced YOLO-NAS, a groundbreaking object detection foundation model that gained widespread recognition. Building on YOLO-NAS, the team unveiled its pose estimation sibling: YOLO-NAS Pose.
Some real-world applications of YOLO-NAS Pose include:
Human pose estimation (action recognition in video analysis, fitness and healthcare monitoring)
3D object tracking (autonomous vehicles for pedestrian and vehicle tracking, robotics for tracking objects in 3D space)
Sports analysis (analyzing and improving sports techniques, motion capture for animation and video games)
Retail and marketing (customer behavior analysis in stores, virtual fitting rooms for online shopping)
Metrics and Performance
Training Details
In training YOLO-NAS Pose to deliver state-of-the-art pose estimation performance, the Deci team faced a set of notable training procedures and techniques.
Refining the YOLO-NAS Loss Function
As mentioned above, YOLO-NAS Pose’s architecture is inherently multi-task, with a head designed for simultaneous detection and estimation. To align these tasks during training, we refined the YOLO-NAS loss function, incorporating not only the IoU score of assigned boxes but also the Object Keypoint Similarity (OKS) score of predicted key points compared to the ground truth. This integration compels the model to yield accurate predictions for both bounding box and pose estimation. Additionally, we employed direct OKS regression for training pose estimation, outclassing traditional L1/L2 losses. This method offers several benefits:
It parallels box IoU, operating within a [0..1] range, signifying pose similarity.
It encompasses prior knowledge on the ease of annotating specific keypoints. Each keypoint aligns with a unique sigma score, reflecting annotation accuracy variance, and dataset specificity. These scores determine the extent of the OKS penalty for inaccurate predictions.
Using a loss function that mirrors the validation metric allows us to precisely target and optimize that specific measurement.
Leveraging the YOLO-NAS Weights and Mosaic Data Augmentation
We leveraged the fact that YOLO-NAS Pose shares the same backbone as YOLO-NAS model so we used weights of YOLO-NAS to initialize the backbone and neck of the model and trained the final model from there.
We found that mosaic data augmentation, random 90 degree rotations and severe color augmentations improved final AP score by ~2AP.
Additional Training Details
Training Time, Learning Rate, and Batch Size Per Size Variant
Variant
Training Time
Learning Rate
Batch Size
Remarks
YoloNAS-Pose N
93h
2e-3
60
Trained from scratch
YoloNAS-Pose S
52h
2e-3
48
Used YOLO-NAS pre-trained weights
YoloNAS-Pose M
57h
1e-4
32
Used YOLO-NAS pre-trained weights
YoloNAS-Pose L
80h
8e-5
24
Used YOLO-NAS pre-trained weights
General Training Settings
Training Hardware: 8x NVIDIA GeForce RTX 3090 GPUs with PyTorch 2.0.
Training Schedule: Up to 1000 epochs with early stopping if no improvement over the last 100 epochs.
Optimizer: AdamW with Cosine LR decay, reducing LR by a factor of 0.05 by the end.
Weight Decay: 0.000001 (excluding bias and BatchNorm layers).
EMA Decay: Beta factor of 50.
Image Resolution: Processed to 640 pixels on the longest side and padded to 640×640 with (127,127,127) padding color.
Performance
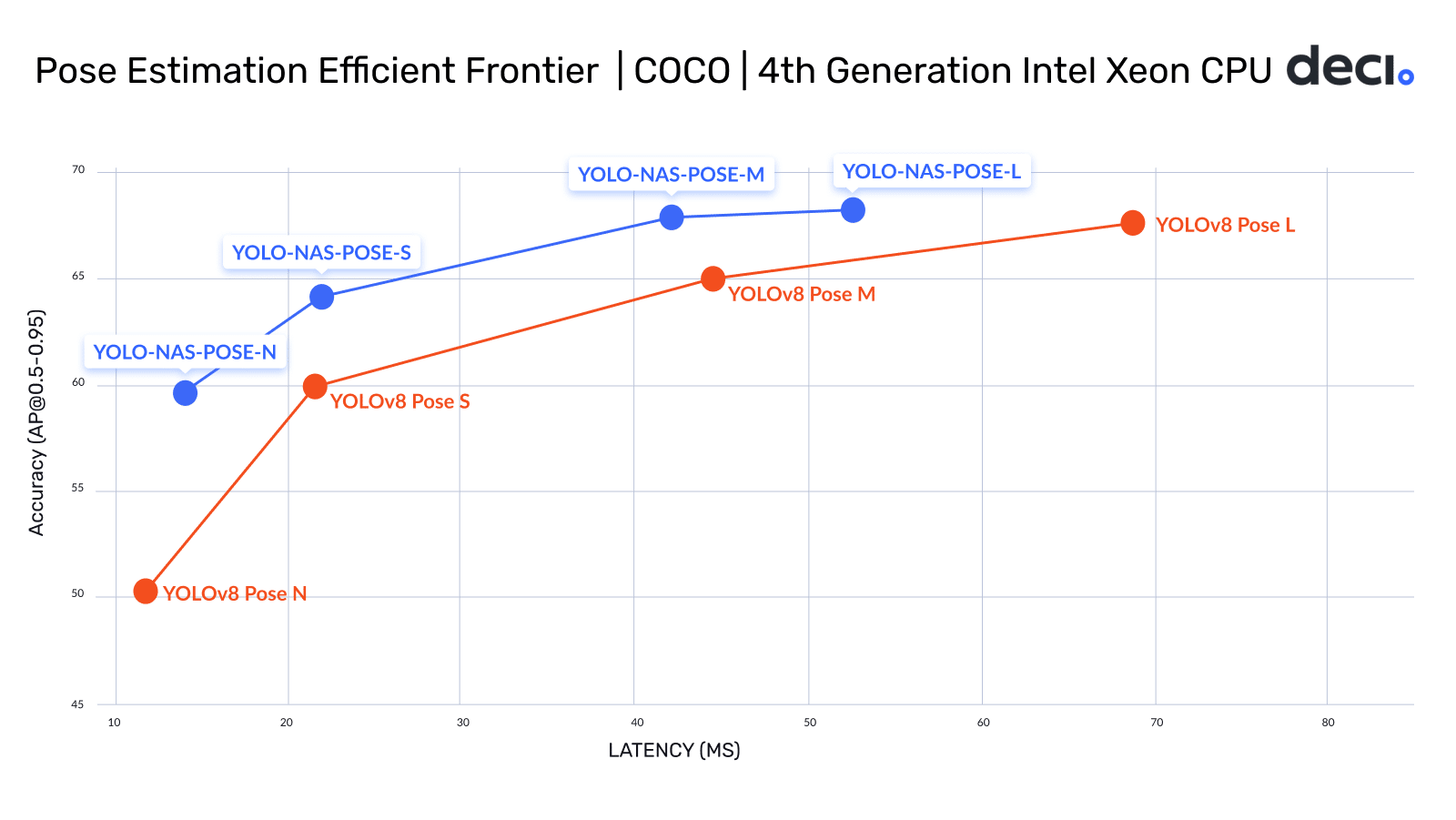
YOLO-NAS Pose variants collectively establish a new efficiency frontier for pose estimation, pushing the envelope of what’s achievable in terms of performance and efficiency. The strides made by YOLO-NAS Pose in this frontier are depicted in the following graph.
All the four variants deliver significantly higher accuracy with similar or lower latency compared to their YOLOv8 Pose equivalent model variants. When comparing across variants, a significant boost in speed is evident. For example, the YOLO-NAS Pose M variant boasts 38% lower latency and achieves a +0.27 AP higher accuracy over YOLOV8 Pose L, measured on Intel Gen 4 Xeon CPUs. YOLO-NAS Pose excels at efficiently detecting objects while concurrently estimating their poses, making it the go-to solution for applications requiring real time insights.
The YOLO-NAS Pose architecture is available under an open-source license. Its pre-trained weights are available for research use (non-commercial) on SuperGradients, Deci’s PyTorch-based, open-source, computer vision training library.