Following the release of DeciCoder 1B, one of the fastest and most accurate codeLLM within its size class, we at Deci are excited to unveil DeciCoder-6B. This new model represents a leap forward in balancing accuracy and cost-efficiency and is one of the most capable and advanced multi-language code LLMs in the 7-billion parameter class. The Apache 2.0 licensed DeciCoder-6B supports a 2k sequence length and excels in 8 code languages, including C, C# C++, GO, RUST, Python, Java, and Javascript. With this release, our objective is to deliver a more powerful and efficient model that not only serves as a robust foundation for code generation applications but also significantly improves user experience and cost efficiency, enabling the scaling of these applications more effectively.
Model Highlights
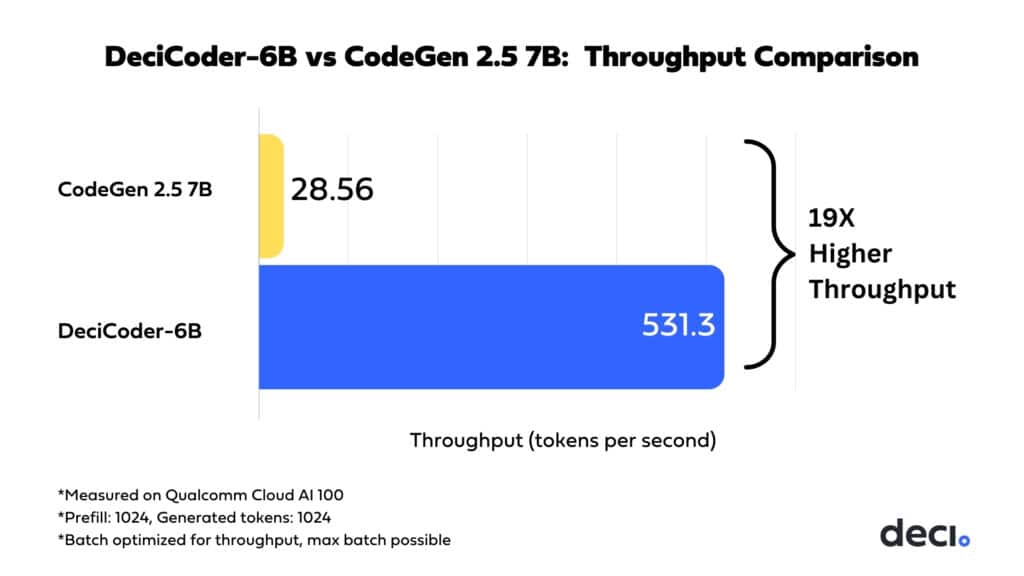
DeciCoder-6B is engineered with a focus on performance at scale. This 6-billion parameter model stands out for its remarkable memory and computational efficiency, which supports low latency even when running at large batch sizes. Compared with peers such as CodeGen 2.5 7B and CodeLlama 7B, DeciCoder-6B demonstrates a clear lead in speed, achieving a 19x higher throughput when running on Qualcomm’s Cloud AI 100.
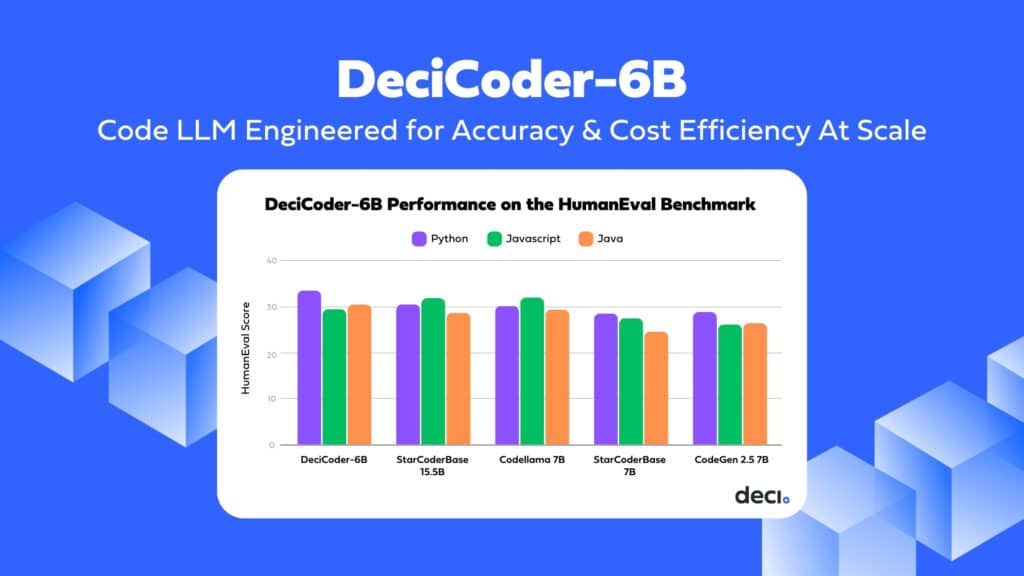
In terms of accuracy, DeciCoder-6B also sets a new standard. On the HumanEval evaluation benchmark, DeciCoder-6B outperforms models like CodeGen 2.5 7B and StarCoder 7B across nearly all languages it supports. In fact, in Python, DeciCoder achieves a 3-point lead over models more than twice its size, such as StarCoderBase 15.5B
DeciCoder’s superior balance between efficiency and accuracy is attributable to its groundbreaking architecture, which is a product of Deci’s cutting-edge Neural Architecture Search-based AutoNAC engine.
The enhancements in inference and memory efficiency brought by DeciCoder-6B have a wide array of positive implications. Key among these is the improved user experience for applications built using the model, directly benefiting end-users. Additionally, there’s a significant reduction in inference costs, primarily due to the model’s ability to perform optimally on more cost-effective hardware. DeciCoder-6B’s design is optimal for performance on Qualcomm’s Cloud AI 100, known for its cost efficiency. To illustrate, the following chart provides a comparative analysis of DeciCoder-6B’s throughput on the Qualcomm Cloud AI 100, set against the performance of Salesforce’s CodeGen 2.5 7B.
Continue reading to uncover the key factors contributing to DeciCoder-6B’s superior memory efficiency and edge over competitors.
DeciCoder-6B’s Performance on Evaluation Benchmarks
DeciCoder-6B was trained on the Python, Java, Javascript, Rust, C++, C, and C# subset of the Starcoder Training Dataset. The model demonstrates exceptional proficiency in these languages, either matching or surpassing competing models in its class. In Python, its HumanEval score is higher than that of the significantly larger StarCoderBase 15.5B.
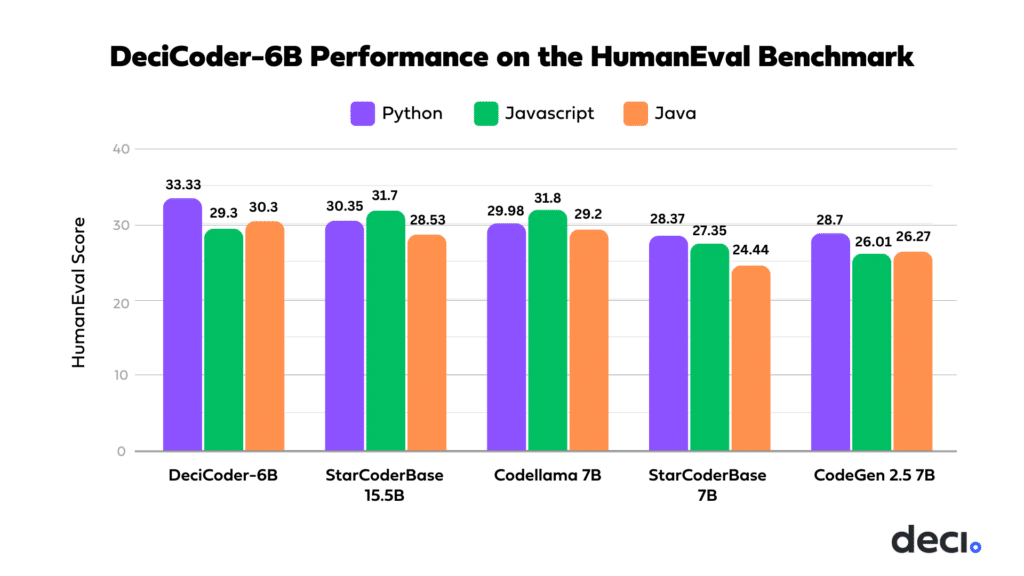
The following table displays DeciCoder-6B’s HumanEval scores:
| Python | Javascript | Java | C++ | C# | Rust | Go |
| 33.33 | 29.3 | 30.3 | 26.93 | 20.31 | 20.5 | 77.47 |
DeciCoder-6B’s Unparalleled Inference Speed and Efficient Batching
In the context of LLMs in production, efficient batching on inference servers is critical. The goal is to maximize the number of user requests processed concurrently. Efficient batching maximizes computational resource use and increases throughput while maintaining acceptable latency. Achieving the right balance between batch size and latency hinges on two factors: the architecture of the model and the capabilities of the hardware used for inference.
The standout feature of DeciCoder-6B is its unique architecture, optimized for low latency, particularly during the processing of large batches. DeciCoder-6B boasts a smaller parameter count than its counterparts, resulting in a reduced memory footprint and freeing up an extra 2GB of memory compared to CodeGen 2.5 7B and 7 billion parameter models. Additionally, it features variable Grouped Query Attention, which enhances its efficiency in scaling batch sizes and ensures the effective utilization of this additional 2 GB of memory. This leads to a remarkably high throughput, surpassing other models in its class.
DeciCoder’s Throughput
When deployed on hardware with powerful processing cores, like Qualcomm’s Cloud AI 100, the model fully leverages the hardware’s computational strengths.The following throughput comparison illustrates the latter point:
When running on the Cloud AI 100, CodeGen 2.5 7B reaches a maximal throughput of only 28.56 tokens per second. DeciCoder-6B, on the other hand, reaches an impressive maximal throughput of 531.3 tokens per second.
This is a direct result of DeciCoder-6B’s efficient design, tailored for Qualcomm’s Cloud AI 100’s powerful core. DeciCoder-6B is ideally suited for this hardware due to several key reasons:
- DeciCoder’s smaller size (6 billion parameters) compared to other models (7 billion parameters) ensures additional free memory for efficient batching.
- Its batching process scales effectively without substantial memory consumption or notable increases in latency.
- The batch sizes are large enough to fully harness the computational power of the Cloud AI 100’s core, optimizing performance.
The Key to DeciCoder’s Accuracy and Efficiency: Strategic Use of Variable GQA
What distinguishes DeciCoder-6B in achieving such high accuracy at remarkable speeds compared to its peers? The answer lies in its architecture, notably its strategic implementation of variable Grouped Query Attention (GQA).
Last month, Deci introduced DeciLM 7B, a highly efficient and performant text-generation LLM outperforming Mistral 7B in both accuracy and throughput. The key architectural breakthrough in DeciLM 7B was the adoption of variable GQA. DeciCoder-6B follows suit, also leveraging this innovative approach.
To appreciate the significance of this innovation, let’s delve into the evolution of transformer architecture, with a specific focus on the development and application of attention mechanisms.
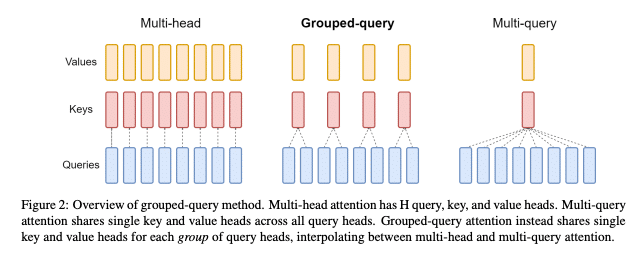
From Multi-Head Attention to Grouped-Query Attention
Multi-Head Attention
Attention mechanisms in neural networks function by processing word embeddings, taking into account the context provided by surrounding words. The concept of attention was revolutionized by the 2017 paper ‘Attention Is All You Need.’ This groundbreaking work not only underscored the significance of attention mechanisms but also introduced Multi-Head Attention (MHA). In MHA, several ‘attention heads’ operate simultaneously, each with its own set of weight matrices generating queries (Q), keys (K), and values (V) from the input. This multi-faceted approach is vital because it allows the model to capture diverse aspects of context and relationships within the data. Different attention heads can focus on various factors influencing a word’s meaning, enabling the model to construct a more nuanced and comprehensive understanding of language.
Multi-Head Attention (MHA) significantly enhances understanding in neural network models, but this comes at a cost: it requires a substantial amount of data to be stored in memory between iterations of the inference process. To grasp this, it’s crucial to understand the role of key-value caching. Key-value caching is implemented to reduce latency in decoder-only transformers, typically used for tasks like next-word prediction and token-by-token generation. This method involves storing the results of previous computations so they can be quickly accessed in subsequent iterations, eliminating the need for repetitive recalculations. However, while key-value caching aids in reducing processing time, it also substantially increases the memory needed for storing this data, a challenge that is particularly pronounced in models employing MHA. As a result, models such as CodeGen 2.5 7B and Llama 2 7B, which utilize MHA, face limitations in their batch size and thus experience lower throughput.
Multi-Query Attention
To facilitate key-value caching without necessitating extensive memory usage during inference, Multi-Query Attention (MQA) was developed. In MQA, while the attention layer retains multiple query heads, it introduces a significant change: all heads share the same keys and values, rather than having separate Ks and Vs for each head.
MQA offers notable benefits, such as improved latency, reduced computational overhead, and less data storage required in memory between inference iterations. However, these advantages often come with a trade-off in terms of quality. An example of this trade-off can be seen in StarCoder 7B, which utilizes MQA. While MQA enables StarCoder 7B to achieve a higher batch size, the model compensates for potential quality degradation by increasing the number of attention layers to 40, compared to the 32 layers used in models like DeciCoder-6B, CodeGen, and LlamaCoder. This increase in layers, in turn, enlarges the memory footprint and diminishes the model’s overall computational efficiency, ultimately affecting its latency.
Grouped-Query Attention
Grouped Query Attention (GQA) emerges as an advancement over Multi-Query Attention (MQA), explicitly engineered to strike a better balance between memory and computational efficiency, and the quality of the model:
- Query Grouping: In GQA, queries are categorized into groups, and each group utilizes a shared set of keys (K) and values (V) for its computations. This setup allows for some degree of parameter sharing, though it is less extensive than in MQA.
- Specialized Attention Patterns: GQA’s approach of assigning distinct keys and values to each query group enables the model to discern a wider array of relationships within the input. This results in more nuanced and sophisticated attention patterns compared to those achieved with MQA, enhancing the model’s ability to accurately interpret and process information.
Variable Grouped Query Attention for A Better Accuracy/Speed Trade Off
Variable Grouped Query Attention offers an enhanced balance between speed and accuracy, surpassing even the fixed Grouped Query Attention (GQA) in terms of efficiency.
DeciCoder-6B, following the innovative path of DeciLM-7B, employs variable GQA to further refine the balance between operational efficiency and the quality of the model. While it consistently uses 32 queries/heads per layer, DeciCoder-6B introduces variability in the GQA group parameter across different layers. Some layers mimic Multi-Query Attention with only a single group, while others incorporate multiple groups.
This layer-specific variation is crucial. By customizing the grouping according to the specific needs of each layer, DeciCoder-6B achieves an ideal equilibrium between the speed of inference and the fidelity of its outputs. It effectively leverages the computational and memory efficiencies of grouped attention, while also benefiting from the detailed and varied attention patterns that this approach facilitates.
The NAS Engine Behind DeciCoder-6B: AutoNAC
The architecture of DeciCoder-6B was developed using Deci’s advanced Neural Architecture Search (NAS) engine, AutoNAC. Traditional NAS methods, while promising, typically require extensive computational resources. AutoNAC circumvents this challenge by automating the search process in a more compute-efficient manner.
This engine has played a key role in developing a variety of high-efficiency models across the AI spectrum. This includes the state-of-the-art object detection model YOLO-NAS, the innovative text-to-image model DeciDiffusion, and the best text generation LLM in the 7 billion parameter class, DeciLM-7B. Specifically for DeciCoder-6B, AutoNAC was crucial in determining the optimal configuration of the GQA group parameters across each transformer layer, ensuring the model’s architecture is ideally suited for its intended tasks.
Setting a New Benchmark in Speed and Cost Efficiency for Code Generation Applications
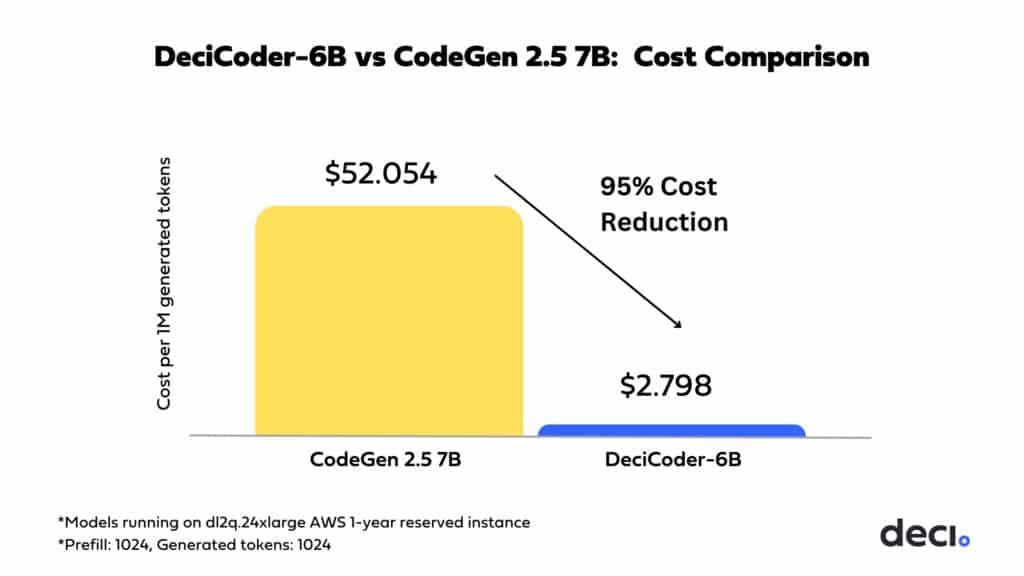
For applications built on multi-language code LLMs to be truly effective, they need to be not just accurate but also exceptionally fast. Before DeciCoder-6B, striking this balance of accuracy and speed often meant relying on expensive, high-end hardware. DeciCoder-6B, with its optimized architecture, changes this paradigm. It delivers outstanding performance even on more cost-effective hardware options, such as the Qualcomm Cloud AI 100, marking a significant advancement in the cost-effective scaling of code generation applications. The following cost comparison underscores the substantial savings realized when opting for DeciCoder over its competitors. This advantage, combined with DeciCoder’s superior accuracy compared to other models, makes its selection a clear and obvious choice.
Experience DeciCoder-6B Firsthand
To experience DeciCoder-6B and Deci’s other high-performance LLMs, visit our interactive playground.
For those curious about our VPC and on-premises deployment options, we encourage you to book a 1:1 session with our experts.
Additional Resources:
- Visit the DeciCoder-6B model on Hugging Face to see its full capabilities.
- Follow a step-by-step tutorial to implement the model on Qualcomm Cloud AI 100.
- Run DeciCoder on AWS DL2q instances using the Qualcomm Cloud AI Platform SDK.
- Delve into the technical details with our comprehensive Google Colab notebook.