
Authors:
- Natan Bagrov, Computer Vision Team Lead
- Tomer Keren, Deep Learning Engineer
- Borys Tymchenko, PhD, Deep Learning Research Engineer
Deci is thrilled to present DeciDiffusion 1.0, our cutting-edge text-to-image latent diffusion model, which we’re proudly sharing with the open-source community. With 1.02 billion parameters, DeciDiffusion outpaces the comparably-sized 1.07 billion parameter Stable Diffusion v1.5 and achieves equal quality in 40% fewer iterations. Combined with our Inference SDK, Infery, DeciDiffusion is 3x faster than Stable Diffusion v1.5, producing Stable Diffusion-caliber images in under a second on affordable NVIDIA A10G GPUs. This leap in performance is driven by DeciDiffusion’s innovative architecture and specialized training techniques optimized for top-tier inference quality. DeciDiffusion’s architecture was designed for optimal inference efficiency, leveraging the power of AutoNAC, Deci’s proprietary Neural Architecture Search engine.
The implications of DeciDiffusion’s heightened capabilities are profound. The domain of text-to-image generation, with its transformative potential in design, art, and advertising, has captivated both experts and laypeople. This technology’s allure lies in its ability to effortlessly transform text into vivid images, marking a significant leap in AI capabilities. While Stable Diffusion’s open-source foundation has spurred many advancements, it grapples with practical deployment challenges due to its heavy computational needs. These challenges lead to notable latency and cost concerns in training and deployment. In contrast, DeciDiffusion stands out. Its superior computational efficiency ensures a smoother user experience and boasts an impressive reduction of nearly 66% in production costs. The result? Making text-to-image generative applications more accessible and feasible.
Below, we’ll compare DeciDiffusion 1.0’s efficiency and quality to Stable Diffusion v1.5, explore its architectural innovations and advanced training techniques, and discuss its heightened efficiency’s cost and environmental benefits.

Examples of images generated by DeciDiffusion 1.0
DeciDiffusion’s Efficiency Gains
DeciDiffusion outperforms Stable Diffusion in efficiency on two main fronts.
Faster per iteration
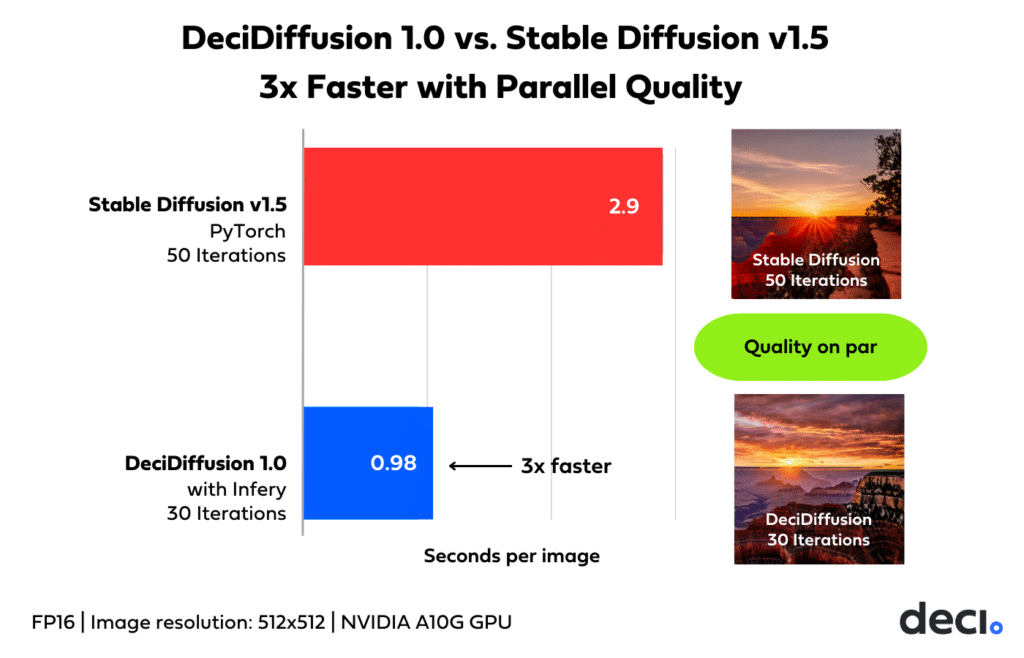
Firstly, its quicker image generation is undeniable. When we benchmark both models at a consistent iteration count, say 50, DeciDiffusion is found to be 1.4 times faster than Stable Diffusion in completing those iterations.
Generates quality images in fewer iterations
Secondly, DeciDiffusion’s advantage becomes even more pronounced when considering image quality. Its ability to achieve the same image quality in fewer iterations means that, when comparing the time each model takes to reach a desired quality level, DeciDiffusion can produce top-tier images in almost half the time of Stable Diffusion.
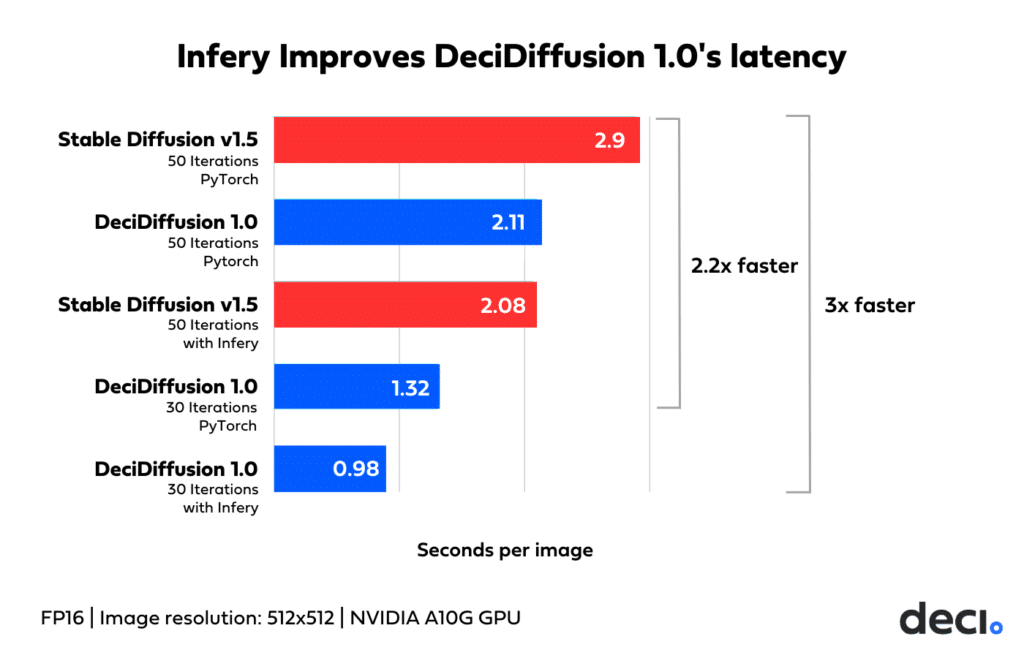
The graph below shows the cumulative impact of these two advantages: DeciDiffusion 1.0 generates Stable Diffusion-caliber images 2.2x faster.

Enhanced Speed with Infery
Deci’s Infery supercharges DeciDiffusion’s already impressive efficiency. This state-of-the-art inference SDK, tailored for generative AI models, seamlessly incorporates advanced techniques such as selective quantization, hybrid compilation, and specialized CUDA kernels. This technical prowess sets Infery apart as a pivotal tool in generative inference acceleration.
Empowered by Infery, DeciDiffusion produces a quality image in under a second, three times faster than it takes a vanilla Stable Diffusion 1.5 to produce an image of equal quality and 2.1 times faster than Stable Diffusion 1.5 with Infery.
DeciDiffusion’s Quality Advantage
Based on subjective evaluation surveys and FID score, DeciDiffusion 1.0’s quality at 30 iterations is either on par with or better than Stable Diffusion v1.5 at 50 iterations.
On average, DeciDiffusion’s generated images after 30 iterations achieve comparable Frechet Inception Distance (FID) scores to those generated by Stable Diffusion v1.5 after 50 iterations. FID is used to assess text-to-image models, comparing the distribution of model-generated images with real, or “ground truth,” images. A lower FID score is taken to signify that the generated images bear a closer resemblance to real images.
However, many recent articles question the reliability of FID scores, warning that FID results tend to be fragile, that they are inconsistent with human judgments on MNIST and subjective evaluation surveys, that they are statistically biased, and that they give better scores to memorization of the dataset than to generalization beyond it.
Survey results: DeciDiffusion 1.0 emerges ahead of Stable Diffusion v1.5
Given reservations regarding the reliability of FID, we opted to evaluate the generation quality of DeciDiffusion 1.0 through a comparative survey against Stable Diffusion v1.5. Our user study mirrored the approach taken by Stable Diffusion researchers when they compared Stable Diffusion XL to Midjourney. Our source for image captions was the PartiPrompts benchmark, which was introduced to compare large text-to-image models on various challenging prompts.
For our study, we chose 10 random prompts and, for each prompt, generated 3 images by Stable Diffusion v1.5 configured to run for 50 iterations, and 3 images by DeciDiffusion configured to run for 30 iterations.
We then presented 30 side-by-side comparisons to a group of professionals, who voted based on adherence to the prompt and aesthetic value. The results of these votes are illustrated below.
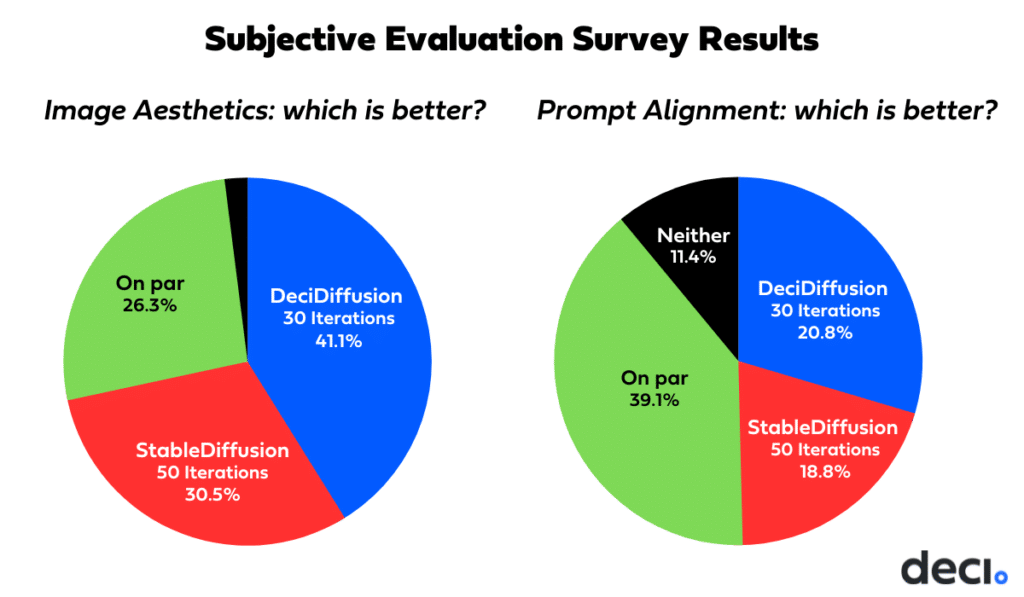
Overall, DeciDiffusion at 30 iterations exhibits an edge in aesthetics, but when it comes to prompt alignment, it’s on par with Stable Diffusion at 50 iterations. Below are some examples of comparisons from the survey.

Our survey results suggest that DeciDiffusion 1.0 is more sample efficient than Stable Diffusion v1.5, producing superior or on-par results with fewer diffusion timesteps during inference. A direct comparison of images generated by each model at varying iteration counts further underscores this observation.

DeciDiffusion’s Architectural Innovation: U-Net-NAS
Like Stable Diffusion, DeciDiffusion is a latent diffusion model, but it replaces the traditional U-Net component with a more streamlined variant, U-Net-NAS, conceived by Deci.
U-Net-NAS vs. U-Net: Understanding the Differences
To understand the role and significance of the the U-Net component, it’s worth diving into the latent diffusion architecture:
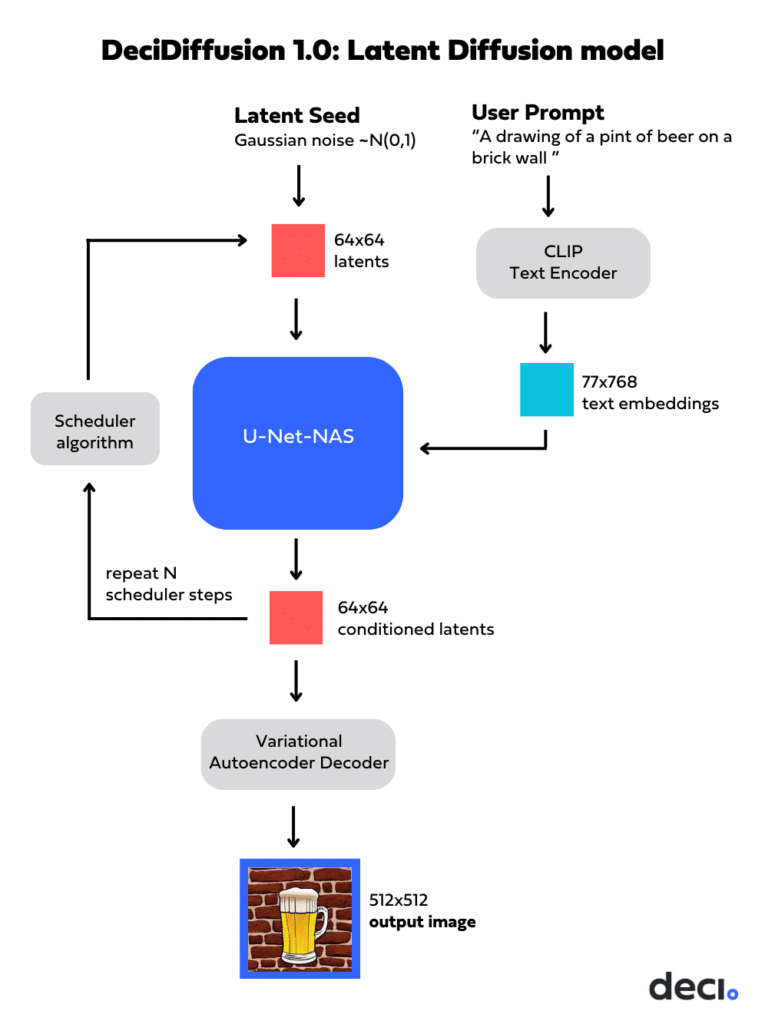
Latent diffusion starts with a rudimentary, “noisy” image representation in latent space. With textual guidance, like “A drawing of a pint of beer on a brick wall,” the model progressively refines this representation, gradually unveiling a denoised image representation. After sufficient iterations, this representation in latent space is expanded into a high-resolution image.
Latent diffusion comprises three primary components:
Variational Autoencoder (VAE): Transforms images into latent representations and vice versa. During training, the encoder converts an image into a latent version, while the decoder reverses this during both training and inference.
U-Net: An iterative encoder-decoder mechanism that introduces and subsequently reduces noise in the latent images. The decoder employs cross-attention layers, conditioning output on text embeddings linked to the given text description.
Text Encoder: This component transforms textual prompts into latent text embeddings, which the U-Net decoder uses.
U-Net is a resource-intensive component during training and inference. The repetitive noising and denoising processes incur substantial computational costs at every iteration.
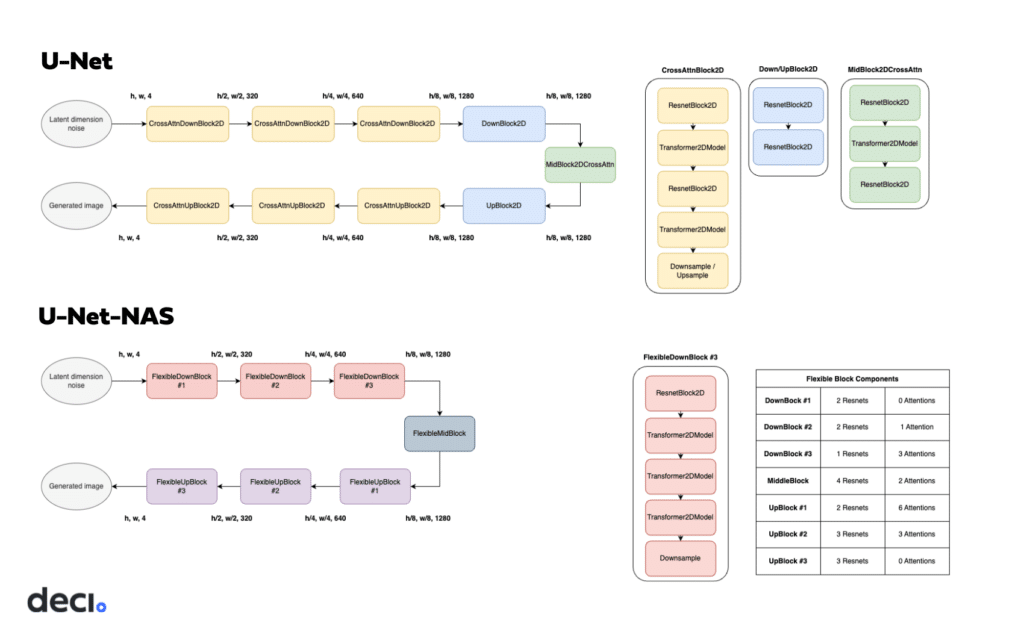
U-Net-NAS features two fewer up and down blocks than U-Net. Its distinctive feature is the variable composition of each block, where the number of ResNet and Attention blocks is optimized to achieve the best overall model performance using the fewest computations. With DeciDiffusion’s incorporation of U-Net-NAS — characterized by fewer parameters and enhanced computational efficiency — the overall model’s computational demands are reduced. This renders DeciDiffusion a leaner and more resource-savvy alternative to Stable Diffusion.
Behind DeciDiffusion’s U-Net-NAS: The Role of AutoNAC
U-Net-NAS’s architecture was generated using Deci’s specialized Neural Architecture Search (NAS) tool, AutoNAC. While traditional NAS approaches show potential, they often demand significant computational resources. AutoNAC overcomes this limitation by streamlining the search process for greater efficiency. It has played a key role in developing a variety of efficient foundational models, including the cutting-edge object detection model YOLO-NAS, the code generation LLM, DeciCoder, and DeciLM, the hyper efficient text generation LLM. For DeciDiffusion’s U-Net-NAS, AutoNAC crucially determined the best combination of ResNet and Attention blocks for each U-Net segment.
DeciDiffusion’s Cutting-Edge Training Approach
DeciDiffusion’s U-Net-NAS was trained from scratch on a 320 million-sample subset of the LAION dataset. It was fine-tuned on a 2 million sample subset of the LAION-ART dataset.
In training DeciDiffusion, we used specialized training techniques to shorten training time as well as to arrive at a high-quality image in fewer iterations or steps.
Techniques we used to speed up training:
1. Using precomputed VAE and CLIP latents
As we trained only the U-Net part of the latent diffusion model, we didn’t need to compute VAE latents and CLIP embeddings every time for every image. We computed them once before training and used the stored version later. This way, we saved 25-50% of computation every epoch.
Stable Diffusion’s VAE outputs both mean and variance of latent codes, so we save both moments and sample latents during training. This way, we can introduce stochasticity even with precomputed latents.
2. Using EMA only for the last phase of the training
We noticed that with EMA, early weight updates contribute very little to the final resulting weights. EMA is a costly operation, which requires us to keep copies of weights in memory and spend time syncing EMA and non-EMA weights. With the long training, it does not make sense to use EMA in the first ~95% of the training iterations. This allowed us to fit ~10% bigger batch size and make training ~15% faster altogether.
How we generate images on par with Stable Diffusion with 40% fewer iterations
We trained our model to be sample-efficient, i.e., to produce high-quality results using fewer diffusion timesteps during the inference process.
We did this by combining a number of techniques.
1. Techniques to enhance intermediate step performance
In our efforts to improve our diffusion model for image generation, we focused on improving the intermediate steps of the process.
When using Stable Diffusion’s beta scheduling, we observed that we can omit up to a third of the last steps without a significant decrease in the FID score, a commonly used metric for evaluating the quality of text-to-image models. This indicated to us that the linear betas schedule may not be optimizing model capacity usage effectively, potentially causing the model to predict noise from noise.
By transitioning to a cosine betas schedule, introduced by A. Nichol and P. Dhariwal, we enhanced the allocation of model capacity, which allows for more precise noise predictions and the possibility of skipping more steps during inference. This schedule adjustment enables our model to make more efficient use of its capacity and generate higher-quality images.
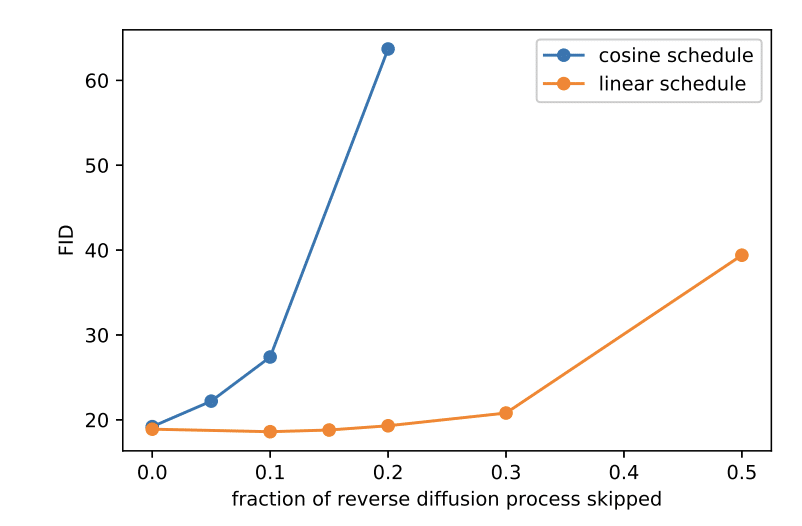
The following image compares the result of employing a linear variance schedule (top) to that of employing a cosine variance schedule (bottom).

In combination with the cosine schedule, we employ a Min-SNR-gamma loss weighting strategy, introduced in T. Hang et al., 2023. This weighting strategy assigns greater importance to the intermediate timesteps, allowing the model to learn them more effectively. Simultaneously, we use this strategy to downweight timesteps with minimal noise levels to ensure a balanced focus, considering that humans are less sensitive to noise with small variances in the images.
2. Techniques to efficiently capture data distribution
Our training and inference procedures were optimized to better capture the data distribution, following S. Lin et al., 2023. Better capturing data distribution is crucial, especially when working with a small number of timesteps during inference.
At the last timestep in the forward diffusion process, our model focuses on a specific target known as v-prediction, which holds special significance. In this context, v-prediction represents the image itself, given the initial noise as input. Thus, the model’s task during this final timestep is not to denoise pure Gaussian noise but to predict the mean of the image distribution conditioned on the input prompt. This is distinct from epsilon prediction, where gradual denoising is necessary over several steps.

3. Techniques to generate images with sharper details and diverse characteristics
We implemented additional optimization, proposed in S. Lin et al., 2023 et al.: the deliberate omission of Step 0, corresponding to the last step, in the reverse diffusion process. This noise level is imperceptible to humans, making the generated image at timestep 1 practically indistinguishable from timestep 0.
By omitting Step 0 during inference, we aim to allocate our model’s capacity more efficiently. This allocation enables the model to focus toward the steps that have a more pronounced impact on the final image’s appearance and quality. This decision results in our model generating images with sharper details and a wider range of characteristics, which is a testament to the importance of the earlier timesteps in shaping the image’s overall structure and content.
The Cost and Environmental Implications of DeciDiffusion’s Heightened Efficiency
DeciDiffusion’s enhanced latency can be attributed to its architectural advancements, training techniques that boost sample efficiency, and the integration of Infery.
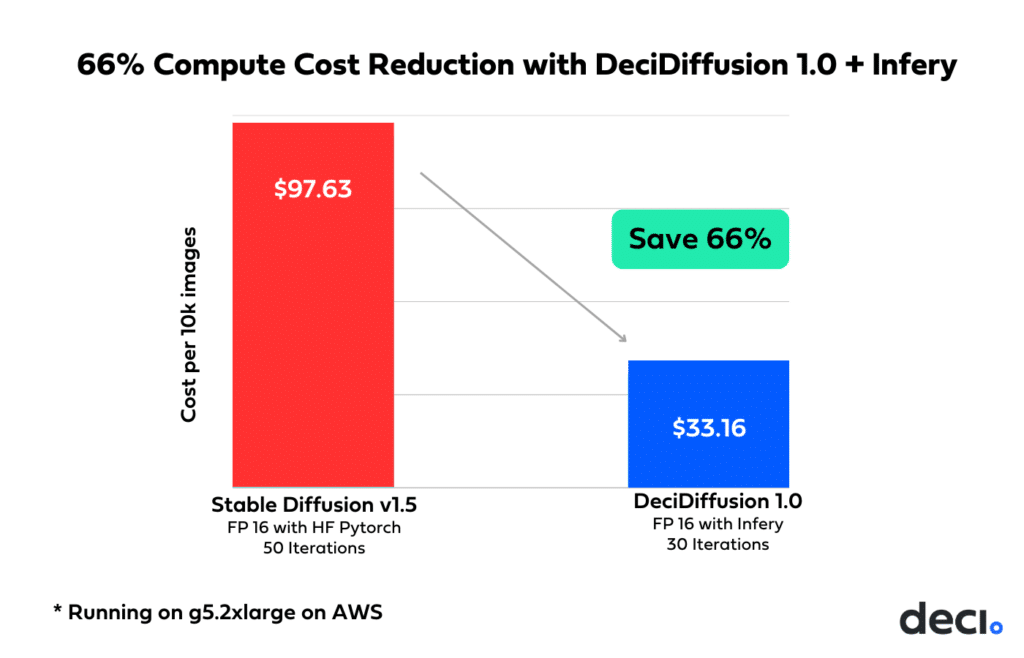
Together, these lead to substantial cost savings in inference operations. Firstly, their combination offers flexibility in hardware choices, allowing for a shift from the high-end A100/H100 GPUs to the more cost-effective A10G without compromising performance. Furthermore, when benchmarked on identical hardware, DeciDiffusion demonstrates remarkable affordability, costing 66% less than Stable Diffusion for every 10,000 images generated.
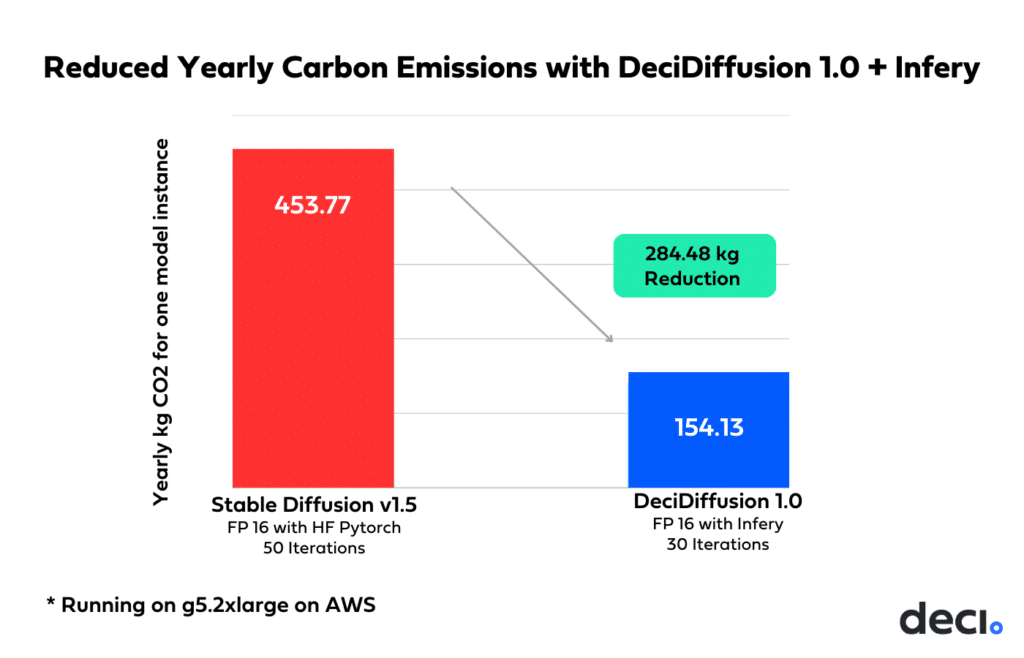
DeciDiffusion’s efficiency champions environmental responsibility by dramatically cutting carbon emissions. Specifically, each model instance on the A10G GPU reduces yearly CO2 emissions by an impressive 300 kg, highlighting the synergy between performance optimization and sustainable practices.
What This Means for Generative AI Use Cases
Infery’s acceleration, particularly in tandem with DeciDiffusion, is a pivotal shift for generative AI applications. Beyond just streamlining real-time projects in content creation and advertising, it significantly reduces associated operational costs. The rapid response time opens doors for its use in time-critical tasks without incurring extra expenses. Whether in interactive media, instant design tweaks, or quick prototyping, Infery ensures generative AI operates efficiently and economically.
Explore Infery.
Book a Demo.
DeciDiffusion’s Availability to the AI Community
In alignment with our commitment to propel the wider adoption of efficient models, Deci is proud to release DeciDiffusion to the AI community. Our intent is to ensure it remains easily accessible and user-friendly, fostering a culture of learning and innovation. DeciDiffusion is available for free download; its code is released under the Apache 2.0 license and its weights are released under the CreativeML Open RAIL++-M License. We encourage researchers, developers, and enthusiasts to leverage this state-of-the-art foundation model in their work.
Conclusion
DeciDiffusion’s exceptional efficiency and superior image quality ensure it seamlessly integrates into real-world applications, all while conserving computational resources. The pioneering architectural choices and training strategies employed by DeciDiffusion not only redefine the benchmarks for the industry but also serve as a rich repository of insights for ensuing endeavors in the realm of efficient AI modeling. As we step forward, it’s evident that solutions like DeciDiffusion will be the guiding stars in our quest for more streamlined and resource-friendly AI tools.
- Experience in Action: Test the model’s capabilities with our interactive demo.
- Get Started: Access and download the model directly from its Hugging Face repository.
To learn more about Infery SDK and how to use it to accelerate DeciDiffusion, book a demo.
Prompt Examples










