1. Introduction
As the deep learning community continues to push the boundaries of Large Language Models (LLMs), the computational demands of these models have surged exponentially for both training and inference. This escalation has not only led to increased costs and energy consumption but also introduced barriers to their deployment and scalability. Achieving a balance between model performance, computational efficiency, and latency has thus become a focal point in recent LLM development.
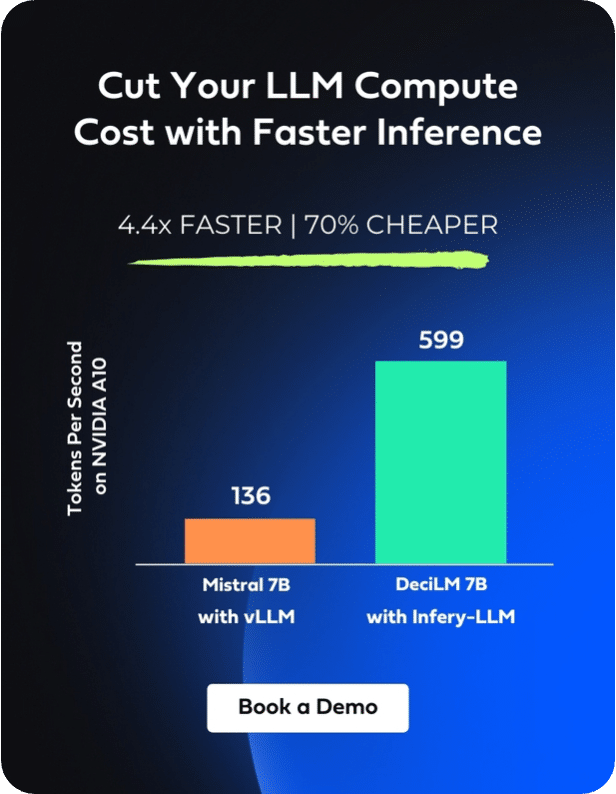
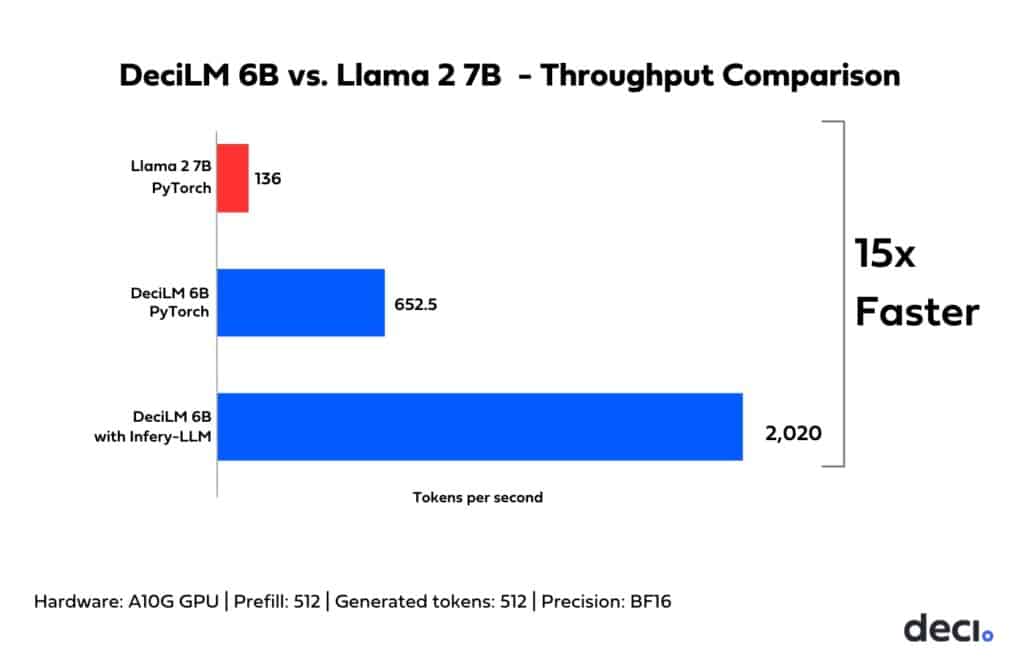
Within this landscape, we are thrilled to introduce DeciLM 6B, a permissively licensed foundation LLM, and DeciLM 6B-Instruct, fine-tuned from DeciLM 6B for instruction-following use cases. With 5.7 billion parameters, DeciLM 6B delivers a throughput that’s 15 times higher than Llama 2 7B while maintaining comparable quality. Impressively, despite having significantly fewer parameters, DeciLM 6B and DeciLM 6B-Instruct consistently rank among the top-performing LLMs in the 7 billion parameter category across various LLM evaluation tasks. Our models thus establish a new benchmark for inference efficiency and speed. The hallmark of DeciLM 6B lies in its unique architecture, generated using AutoNAC, Deci’s cutting-edge Neural Architecture Search engine, to push the efficient frontier. Moreover, coupling DeciLM 6B with Deci’s inference SDK results in a substantial throughput enhancement.
The implications of such a significant increase in inference efficiency are far-reaching. They include a better user experience for applications built on top of the model, a meaningful reduction in inference cost due to the ability to run the models on more affordable GPUs, and a sizable reduction in carbon footprint.
DeciLM, with its remarkable evaluation results on standard LLM evaluation benchmarks, can be used in a wide range of generative AI applications—from support chatbots to content creation assistants, and more. The significant efficiency enhancement from DeciLM greatly elevates the viability and scalability of these generative AI applications.
In the subsequent sections, we delve into the technical intricacies that underlie DeciLM, elucidate the novel attention mechanisms it employs, and present empirical results that attest to its superior performance and efficiency.
2. DeciLM’s Architectural Innovations
DeciLM’s decoder-only transformer architecture features a unique implementation of variable Grouped-Query Attention (GQA). Unlike other transformer models utilizing GQA, such as Llama 2 70B, which maintains consistent attention groups per transformer layer, DeciLM varies the number of attention groups, keys, and values across transformer layers. To the best of our knowledge, DeciLM is the first language model where the transformer layers are not structural duplicates of one another.
2.1 Variable Grouped-Query Attention
Background
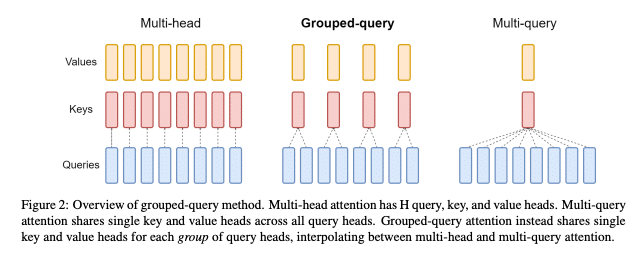
The 2017 paper “Attention Is All You Need” introduced the Transformer architecture, reshaping sequence-to-sequence modeling. One of its standout features, Multi-Head Attention (MHA), uses multiple parallel “heads.” Each attention head has its own distinct set of weight matrices that produce queries (Q), keys (K), and values (V) from the input data. The intuition is that each head captures different aspects or relationships in the data.
Multi-Query Attention
Despite MHA’s effectiveness, its increased parameters amplify computational and memory demands, especially in larger models. To mitigate this while preserving attention’s expressiveness, researchers introduced Multi-Query Attention (MQA). MQA reduces the number of parameters in the attention mechanism to make it more memory and computationally efficient and speed up inference:
- In MQA, the model still maintains multiple query (Q) heads.
- However, instead of having separate Ks and Vs for each head, all heads share the same K and V.
Grouped-Query Attention
While MQA increases the computational and memory efficiency of the model, it does lead to quality degradation. GQA was introduced as an enhancement over MQA, designed specifically to offer a superior balance between memory and computational efficiency and model quality:
- Query Grouping: The queries in GQA are divided into groups, with each group sharing a single K and V computation. This provides some level of parameter sharing, but not as much as MQA.
- Specialized Attention Patterns: By granting distinct keys and values to each query group, the model can identify a broader range of relationships in the input, which leads to more refined attention patterns than in MQA.
Variable Grouped-Query Attention in DeciLM
With DeciLM, we introduce Variable GQA to further optimize the tradeoff between efficiency and model quality. Unlike other models, such as Llama 2 70B, that consistently apply the same number of groups across all layers, DeciLM introduces variability in its approach. Specifically, while maintaining 32 queries/heads per layer, DeciLM’s layers vary in their GQA group parameter:
- Some layers utilize 4 groups, with 8 queries per group and only 4 K and 4 V heads per layer.
- Others apply 2 groups, with 16 queries per group and 2 K and 2 V parameters per layer.
- While certain layers have 1 group (as in MQA), with all 32 queries in that group and a single key and value head.
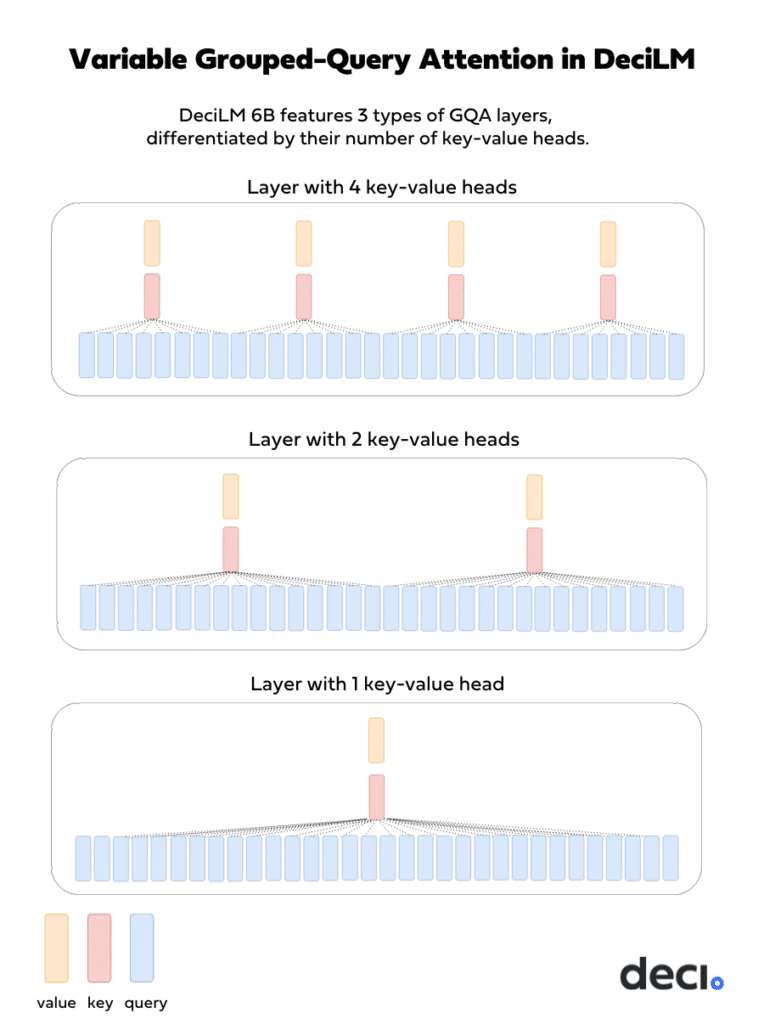
This strategic layer-specific variation is pivotal. By tailoring the grouping to each layer’s unique requirements, DeciLM strikes an optimal balance between inference speed and the quality of the model’s outputs. It capitalizes on both the computational and memory efficiency of grouped attention and the nuanced understanding derived from diverse attention patterns.
2.2. AutoNAC: The Engine Behind DeciLM’s Architectural Excellence
The architecture of DeciLM was generated using Deci’s proprietary Neural Architecture Search (NAS) engine, AutoNAC. Traditional NAS methods, albeit promising, are computationally intensive. AutoNAC addresses this challenge by automating the search process in a compute-efficient manner. The engine has been instrumental in generating a wide range of high-efficiency foundation models, including the state-of-the-art object detection model YOLO-NAS, the text-to-image model DeciDiffusion, and the code generation LLM, DeciCoder. In the case of DeciLM, AutoNAC was pivotal in selecting the optimal GQA group parameter for each transformer layer of the model.
3. DeciLM’s Training
DeciLM 6B underwent training utilizing a subset of the SlimPajamas dataset, leveraging advanced proprietary methodologies allowing for fast training. The SlimPajamas dataset is an extensive deduplicated, multi-corpora open-source dataset, publicly available on Hugging Face under the Apache 2.0 license. DeciLM 6B then underwent LoRA fine-tuning, resulting in DeciLM 6B-Instruct.
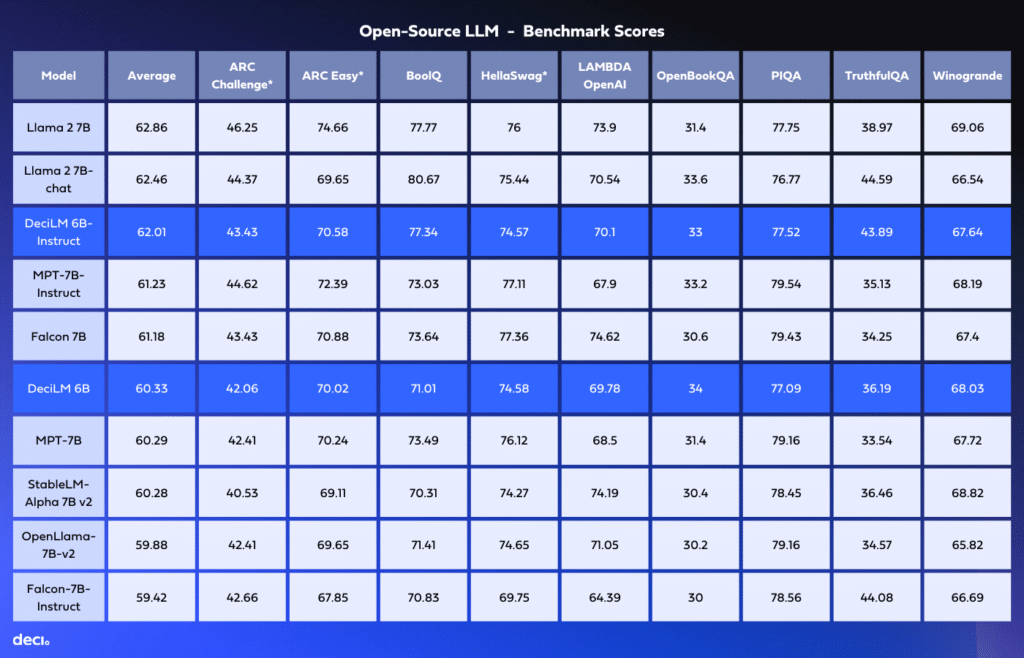
4. Performance Analysis: DeciLM’s Standout Metrics Among Peers
We benchmarked DeciLM 6B and DeciLM 6B-Instruct against leading open-source models in the 7-billion parameter class, such as Llama 2 7B, Llama 2 7B-Chat, Falcon 7B, and MPT-Instruct. Even with significantly fewer parameters, DeciLM 6B-Instruct clinched the third spot, trailing Llama 2 7B by just under a percentage point.
5. DeciLM’s Trailblazing Inference Efficiency
5.1 Comparative Analysis: DeclLM 6B vs. Llama 2 7B
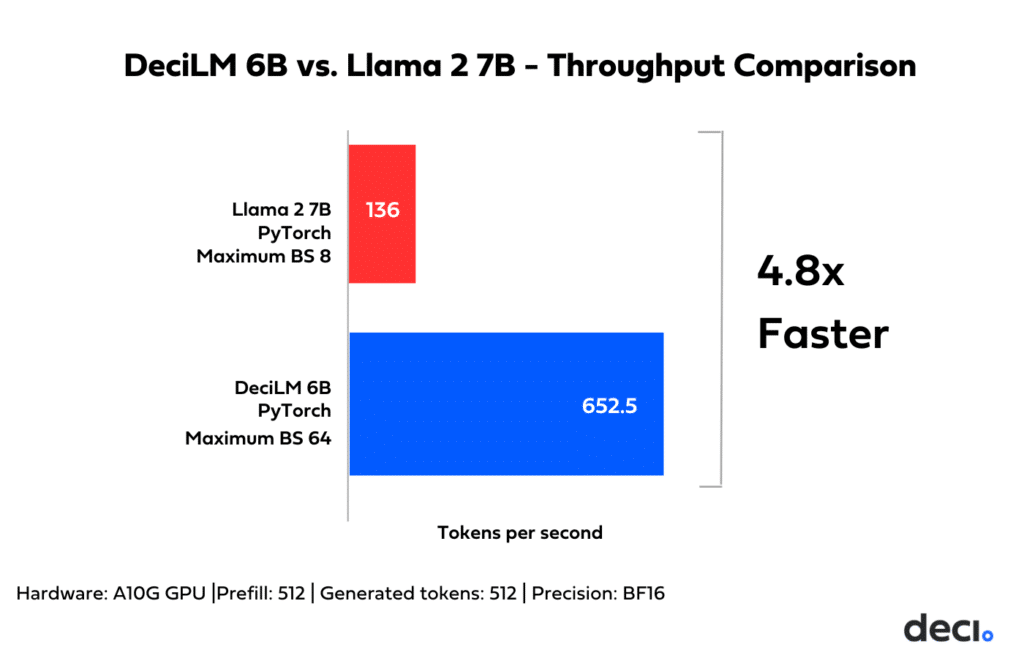
To assess the efficiency enhancements brought by DeciLM’s architecture, we performed a side-by-side PyTorch comparison with Llama 2 7B, utilizing an NVIDIA A10G GPU for the tests. Since the optimal throughput point at generation for each model is achieved at maximum batch size, we used the maximal possible batch size for each model when benchmarking throughput. The results reveal that DeciLM is both more memory efficient and has a higher throughput.
Memory Efficiency: DeciLM’s architecture showcases enhanced memory efficiency. Our empirical observations indicated that DeciLM optimally processes data at a batch size 64. In comparison, Llama 2 7B demonstrated a maximum batch size of 8. DeciLM’s capability to handle larger batch sizes translates into more efficient inference with better utilization of the GPU hardware, unhindered by the memory constraints that limited previous models.
Throughput: DeciLM 6B’s throughput (tokens per second measured with an optimal batch on A10G) is 4.8 times that of Llama 2 7B’s.
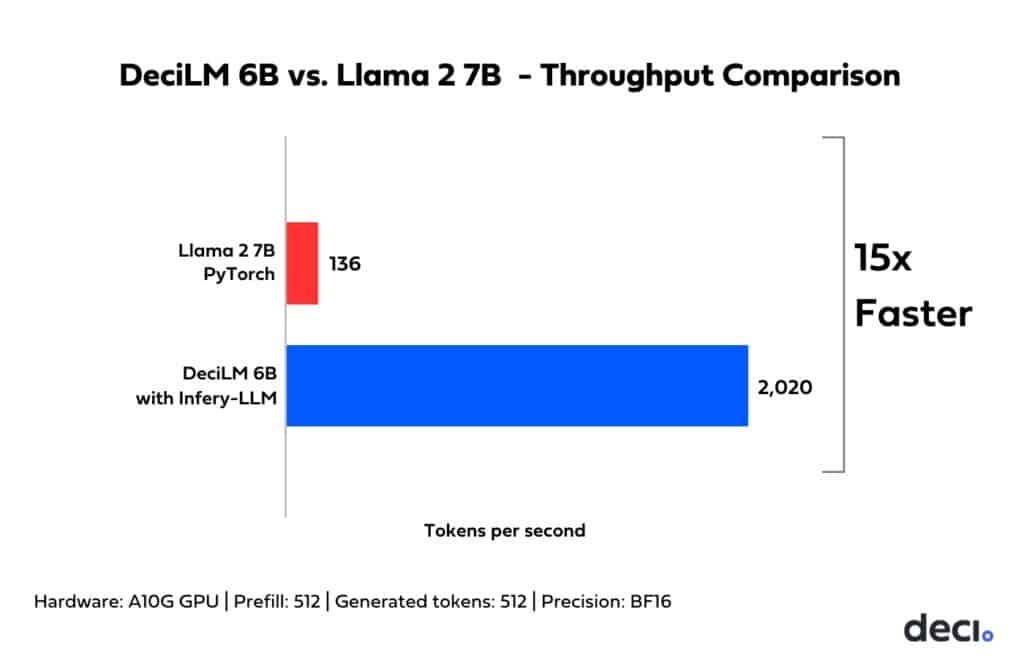
5.2 Infery-LLM: The Ultimate Turbo Boost for Large Language Model Inference
Background:
Infery-LLM is a specialized inference SDK developed by Deci, designed to enhance the computational processing of Large Language Models. Built upon advanced engineering techniques such as selective quantization and hybrid compilation and incorporating proprietary optimized kernels, fast beam search and more, Infery stands out as an instrumental tool for LLM inference acceleration.
Throughput Boost and Incomparable Efficiency:
When applied to LLMs such as DeciLM, Infery-LLM consistently delivers superior performance outcomes. The architecture and optimization strategies employed by Infery-LLM ensure that models achieve peak efficiency without compromising output quality. For instance, when running with Infery-LLM, DeciLM 6B’s throughput is 15 times that of Llama 2 7B’s on NVIDIA’s A10G GPU.
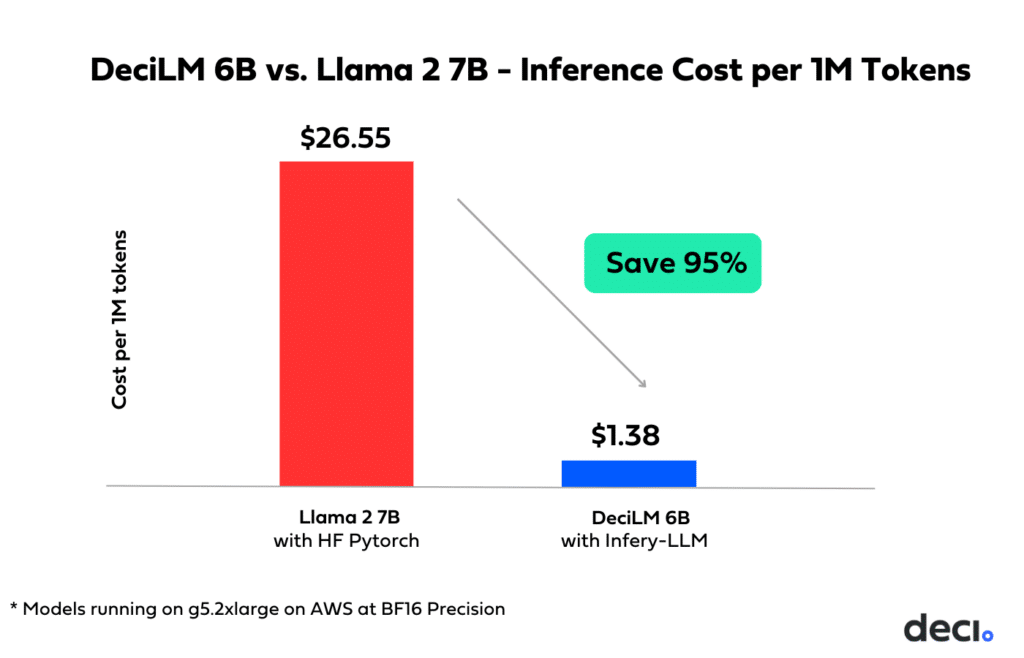
Cost and Environmental Implications:
The efficiency achieved through the combination of DeciLM and Infery-LLM results in a staggering reduction in inference costs. For one, it enables you to migrate workloads from the pricey A100/H100 GPUs to the more affordable A10G. Secondly, when running on the same hardware, DeciLM’s cost per 1M tokens is 95% lower than that of Llama 2 7B.
This efficiency also translates into a commendable environmental impact, cutting the carbon footprint by 516kg CO2 per model instance yearly on the A10G GPU.
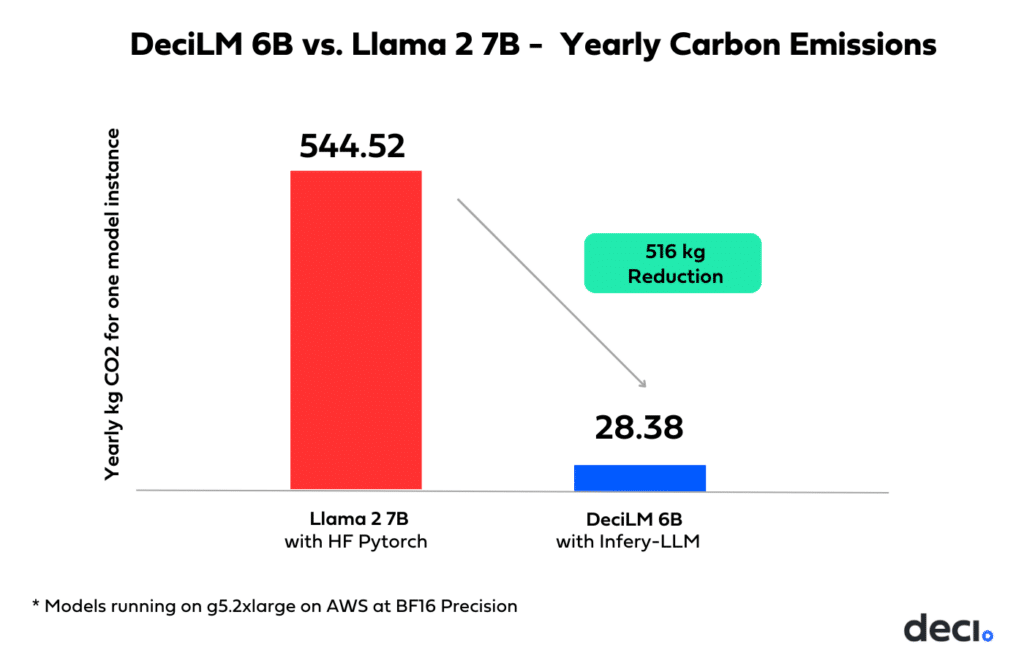
What This Means for Generative AI Use Cases:
For applications where real-time response and high throughput are paramount, the integration of Infery-LLM proves invaluable, with the potential to drastically improve user experience. Additionally, it provides a streamlined approach to achieving incomparable efficiency of DeciLM and comparable LLMs.
Explore Infery LLM.
Get Started.
6. DeciLM’s Availability to the Community
In alignment with our commitment to propel the wider adoption of efficient models, Deci is proud to release DeciLM to the community. Our intent is to ensure it remains easily accessible and user-friendly, fostering a culture of learning and innovation. DeciLM is available for free download and is permissively licensed under the Llama 2 Community License Agreement. We encourage researchers, developers, and enthusiasts to leverage this state-of-the-art foundation model in their work.
Conclusion
DeciLM 6B signifies a landmark development in the realm of LLMs, paving the way for models that can seamlessly integrate into real-world applications without taxing computational resources. Its innovative design sets new benchmarks and provides valuable insights for future explorations in the domain of efficient AI modeling.
- Dive Deeper: Navigate through our notebook for an in-depth exploration of using the model.
- Experience in Action: Test the model’s capabilities with our interactive demo.
- Get Started: Access and download the model directly from its Hugging Face repository.
To learn more about Infery-LLM and how you can use it to accelerate DeciLM, get started today.