Direct Preference Optimization (DPO) signifies a potential turning point in the realm of preference tuning for large language models (LLMs), introducing a streamlined approach that directly leverages human feedback. First detailed in “Direct Preference Optimization: Your Language Model is Secretly a Reward Model,” DPO presents a simplified yet effective alternative to the intricate processes of Reinforcement Learning from Human Feedback (RLHF). With RLHF serving as the foundation for groundbreaking AI like ChatGPT, it has established a benchmark for aligning AI outputs with human expectations. This raises an intriguing question: Is there a pathway that offers both greater efficiency and effectiveness in tuning models to human preferences?
This article explains DPO, outlines its differences from RLHF, and examines if DPO is invariably the superior choice for preference tuning LLMs.
An Overview of Reinforcement Learning from Human Feedback in Language Models
The process of RLHF is designed to align the outputs of language models more closely with human preferences and expectations. This method integrates human judgments into the model’s training loop, allowing it to learn from nuanced feedback beyond correct or incorrect labels. Here’s a breakdown of how RLHF operates with language models:
1. Pre-training and Fine-tuning
First, language models are pre-trained on large datasets composed of diverse text. This pre-training phase enables the model to learn a broad understanding of language, including grammar, syntax, and some level of semantic knowledge. After pre-training, models often undergo a fine-tuning phase, where they are further trained on a more specialized dataset to adapt their capabilities to specific tasks or domains.
2. Human Feedback Collection
The RLHF process begins after the initial pre-training and fine-tuning. Human reviewers are presented with outputs generated by the language model in response to various prompts or tasks. These reviewers then provide feedback on the outputs, which can take different forms, such as:
- Ranking Outputs: Reviewers might compare multiple responses to a single prompt and rank them based on quality, relevance, or adherence to specific criteria.
- Binary Feedback: Outputs could be labeled simply as acceptable or unacceptable.
- Graded Feedback: More nuanced feedback might involve grading responses on a scale to reflect varying degrees of quality or appropriateness.
3. Training the Reward Model
The feedback collected from human reviewers is used to train a reward model. This model learns to predict the quality of a language model’s output based on human judgments, assigning a scalar value score to each output generated by the LLM. Essentially, it translates subjective human preferences into a quantifiable format that the AI can understand. The reward model assesses how well the language model’s outputs align with what humans consider to be good or correct responses.
4. Policy Optimization
With the reward model in place, the language model undergoes another round of training. This time, however, the training is focused on maximizing the rewards (score) predicted by the reward model. Techniques from reinforcement learning, such as Proximal Policy Optimization (PPO), are used to adjust the language model’s parameters so that it produces outputs that are more likely to receive high rewards. This iterative process gradually guides the language model toward generating responses that better match human preferences.
5. Iterative Improvement
RLHF is typically an iterative process. The model’s improved outputs can be subjected to another round of human feedback, further refining the reward model and the language model’s performance. This cycle can be repeated multiple times, each iteration aiming to enhance the alignment of the model’s outputs with human expectations.

Understanding DPO:
DPO streamlines the alignment of language models with human preferences by leveraging a more direct approach.
Unlike RLHF, which involves a multi-step process of collecting feedback, training a reward model, and implementing an optimizing policy based on the reward model’s predictions, DPO simplifies the alignment process:
Direct Comparison of Outputs:
- DPO requires the collection of human feedback, where individuals assess pairs of responses generated by the language model in response to identical prompts. Reviewers designate one response as preferable over the other, creating a dataset of preference pairs. This dataset forms the basis for the optimization.
Optimization Based on Preferences:
- The core of DPO lies in using these direct preferences to optimize the model. Instead of training a separate reward model to interpret human judgments, DPO integrates the preference data directly into the model’s training process.
At the heart of DPO’s methodology is a reparameterization that significantly simplifies the reward function, eliminating the necessity for external baselines or the incorporation of complex normalization terms that are traditionally challenging to optimize. This reparameterization fundamentally changes how preference data is utilized, allowing for direct integration of this data into the model’s training regimen. - The optimization algorithm adjusts the model’s parameters to increase the likelihood of generating outputs similar to those preferred by the reviewers. This can be achieved by designing a loss function that directly penalizes the model for producing less-preferred outputs.
For a technical overview of DPO, visit our Google Colab Notebook.
Advantages of DPO:
DPO has several clear advantages over RLHF:
1. Simplicity and Familiarity in Implementation
DPO simplifies the process of aligning language models with human preference. Unlike the multi-layered process of RLHF, which involves detailed feedback collection, intricate reward model training, and complex policy optimization, DPO offers a straightforward path by directly embedding human preferences into the training loop.
This approach not only cuts through the procedural complexity but also aligns the training process more closely with the standard practices of pre-training and fine-tuning that developers and researchers are already accustomed to. In DPO, there’s no need to navigate the intricacies of constructing and adjusting reward functions or the challenges associated with reward model training. It makes the alignment stage more similar to the familiar stages of pre-training and fine-tuning.
2. Elimination of Reward Model Training
A significant advantage of DPO is the elimination of the need to train an additional reward model. This not only saves on computational resources but also sidesteps the challenges associated with reward model accuracy and maintenance. Developing a reward model that accurately interprets and quantifies human feedback into actionable signals for the AI is a non-trivial task. It requires substantial effort in not just initial training but also continuous updates and maintenance to reflect evolving human preferences accurately. DPO bypasses this requirement entirely, leveraging preference data in a way that the model can use directly.
3. Enhanced Stability in Training
In order to stitch together human-quality text, LLMs commonly use autoregressive generation, where each word is predicted based on the ones before it. However, this process presents a major computational challenge for efficient inference. Each token prediction relies on the previously generated text, creating a sequential dependency. As text length grows, the generation becomes progressively slower, impacting the scalability and efficiency of LLMs.
Why Stability Matters
Stability is paramount in aligning language models with human preferences for a few key reasons:
- Consistency in Learning: Stable training ensures that the model progressively learns from feedback without regressing or oscillating between different performance levels. Instability can cause the model to “forget” what it has learned or fail to converge to a desirable state, undermining the training’s overall effectiveness.
- Predictability: A stable training process is more predictable, allowing researchers and developers to better understand how changes in the model or training regimen will affect outcomes. This predictability is crucial for systematic improvements and iterations.
- Efficiency: Instability often leads to inefficient use of resources, as it can require more iterations and adjustments to achieve the desired model performance. Stability, on the other hand, enables a more direct path to optimization, saving time and computational resources.
Sources of Instability in RLHF
- Complex Reward Signals: The reward model in RLHF translates human feedback into numerical rewards that guide the language model’s training. If this translation captures human preferences inaccurately or inconsistently, it can lead to unstable reward signals, causing the language model to receive mixed messages about what constitutes desirable outputs.
- Policy Updates: The method used to update the model’s policy based on the reward signals can introduce instability. Large or poorly directed updates can cause the model to shift too drastically, disrupting the learning process. This is particularly challenging in the nuanced domain of language, where slight changes can significantly impact output quality.
- Variance in Feedback: Human feedback is inherently subjective and can vary widely between individuals or even for the same individual at different times. This variance introduces noise into the training data, making it harder for the model to discern clear patterns and adjust its policy consistently.
Addressing Instability with Proximal Policy Optimization
As mentioned above, PPO is a policy optimization technique often used in RLHF. It has gained favor in the community because it is specifically designed to address instability issues. PPO limits the size of policy updates through a clipping mechanism and optimizes a surrogate objective function, which helps prevent drastic changes in the model’s behavior between iterations. This controlled approach to policy updates promotes a more stable learning environment, allowing the language model to gradually and reliably improve its alignment with human preferences.
The Inherent Stability of DPO
While PPO is designed to address the potential instability in RLHF, DPO is inherently stable. The use of a simple classification loss function, combined with reparametrization that simplifies the optimization objective, eliminates the need for external baselines or complex normalization terms. This simplification reduces the chances of encountering the types of optimization challenges that can lead to instability, such as high variance in gradient estimates or difficulties in accurately estimating and optimizing a separate reward model. The reparametrized loss directly aligns with human preferences, ensuring a stable and consistent gradient signal for model updates.
4. Competitive or Superior Performance
Direct Preference Optimization can achieve performance levels that are equivalent to, and sometimes surpass, those attainable with RLHF and PPO, as evidenced by the results of the experiments reported in Direct Preference Optimization: Your Language Model is Secretly a Reward Model.
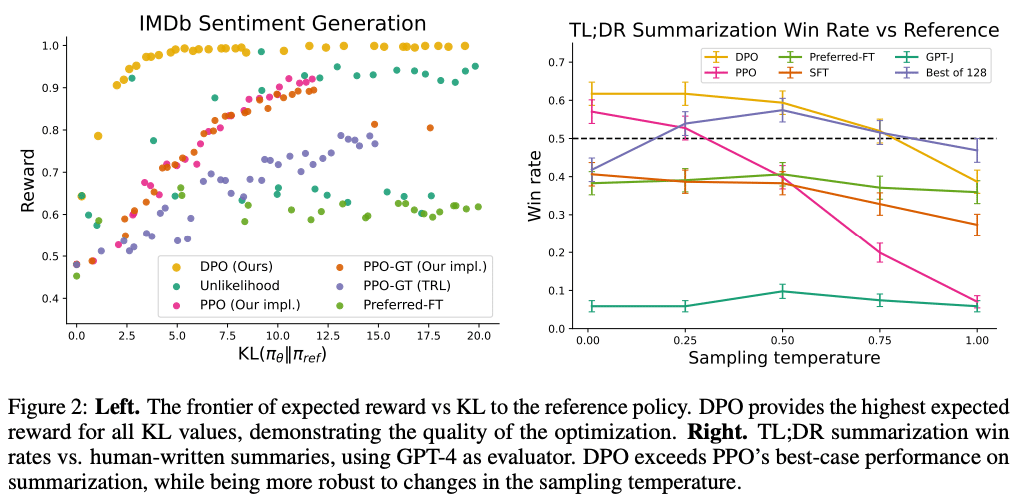
The results of the experiments indicate:
- DPO surpasses PPO-based RLHF in controlling the sentiment of generated text, effectively aligning it with desired emotional tones.
- DPO matches or improves upon the response quality in summarization and dialogue tasks.
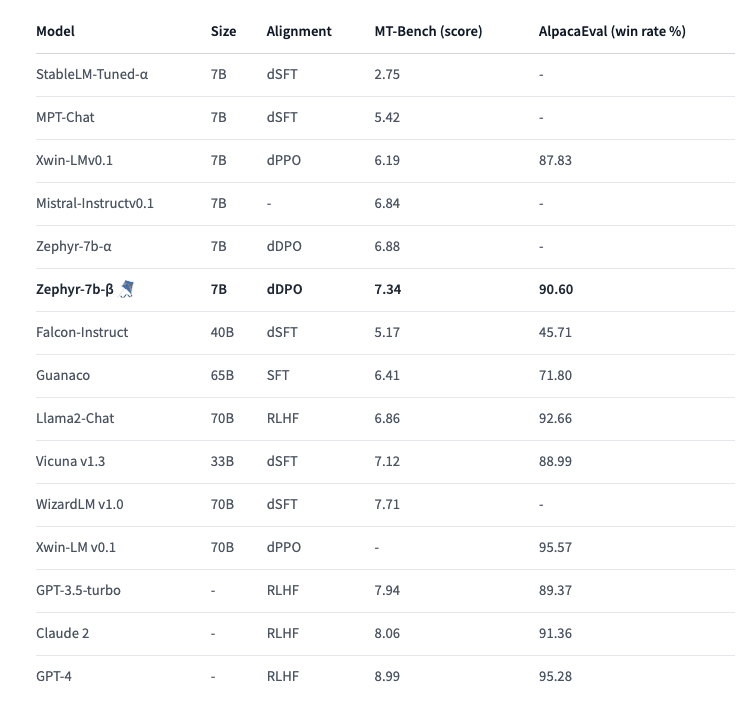
In addition to these experiments, there have already been several capable models aligned using DPO, including Zephyr-7B-𝛽, Intel’s Neural-Chat-7B-v3-3, Cerebras’ BTLM-3B-8k-chat, and Tulu V2 DPO 70B. Zephyr-7B-𝛽 is, at the time of the writing of this blog, the highest-ranked 7B chat model on the MT-Bench and AlpacaEval benchmarks, surpassing models that have been aligned using RLHF and PPO, including significantly larger models.
Is DPO always the better alignment method?
Despite the clear advantages of DPO in simplicity and computational efficiency and the evidence of its competitive performance, the choice between DPO and RLHF (PPO) is far from straightforward.
Choosing DPO May Be Dataset Dependent
There is evidence that at least for some datasets, alignment through RLHF produces better results than DPO. For instance, recent studies by NVIDIA indicate that DPO may not perform as well as PPO, specifically in their work with the SteerLM model and the accompanying HelpSteer dataset.
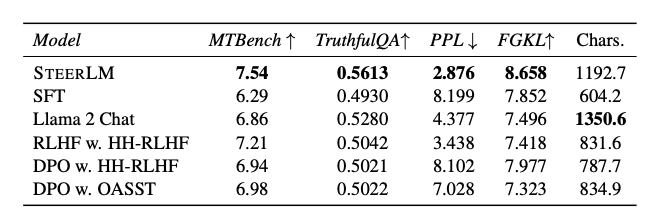
According to the findings, RLHF, utilizing PPO, appears to have a marginal advantage over DPO in the MT-Bench and TruthfulQA benchmark tests.This indicates that the choice between DPO and RLHF may in part depend on the nature of the dataset available.
Of course, there is another way in which the choice is dataset-dependent, since RLHF relies on datasets that include human feedback in various forms, including ratings, rankings, or binary choice, whereas DPO is particularly well-suited to datasets where preferences between pairs of outputs are explicitly stated.
Choosing DPO may depend on the degree of generalization required
The decision between utilizing DPO and PPO may hinge on the required level of generalization. A prevailing belief suggests that the process of training a reward model enhances the model’s ability to generalize effectively across a diverse range of data and prompts. This view, however, is put to the test in light of the findings presented in the DPO research, particularly when comparing the adaptability of DPO and PPO models to shifts in data distribution—such as the transition from summarizing Reddit posts to summarizing news articles from the CNN/DailyMail dataset.
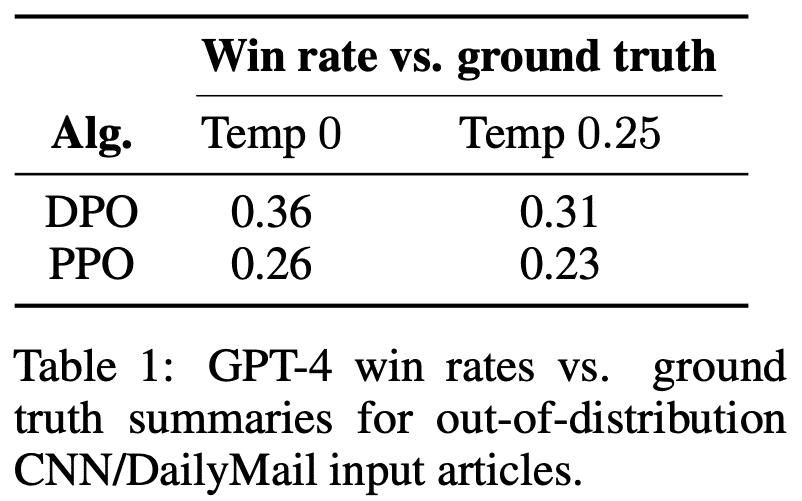
The above comparison reveals that DPO demonstrates an advantage over PPO in adapting to these distribution shifts, challenging the traditional view that a separate reward model is essential for broad generalization.
Despite these promising results favoring DPO’s capability to handle varied data types, it remains an open question whether DPO’s approach to generalization consistently matches or exceeds that of traditional RLHF methods across a wider spectrum of scenarios.
Assessing DPO’s Place in Aligning LLMs with Human Preferences
While it’s not definitively clear-cut that DPO surpasses RLHF in all aspects, DPO presents several compelling advantages:
- Simplicity: DPO offers a straightforward, less complex approach to model training, avoiding the intricate feedback loops of RLHF.
- Efficiency: It reduces computational demands by directly optimizing the model with preference data, eliminating the need for a separate reward model.
- Stability: DPO is inherently stable, thanks to its simplified loss function and optimization process.
- Competitive Performance: It has been shown to achieve performance levels that are on par with or even exceed those attainable with RLHF and PPO in certain benchmarks.
Moreover, the accessibility and ease of implementation of DPO have been significantly enhanced through community tools. Hugging Face’s DPO Trainer, available in the TRL (Transformer Reinforcement Learning) library, facilitates the application of DPO by providing a framework that is fully compatible with the Hugging Face transformers library. This tool is based on the methodology described in Your Language Model is Secretly a Reward Model, aiming to streamline the fine-tuning of language models from preference data. For a tutorial on using DPO Trainer, visit our Google Colab notebook.This advancement underscores the growing support for DPO within the AI research and development community, making it an increasingly viable and appealing option for projects seeking to align LLMs closely with human judgments. While the debate between DPO and RLHF continues, the unique strengths of DPO, coupled with the availability of robust tools for its implementation, highlight its significant role in the evolving landscape of language model alignment.
Discover Deci-Nano and GenAI Development Platform
If you are searching for an LLM to use in your GenAI application, we encourage you to explore our series of DPO-tuned, high-performance LLMs, available through our GenAI Development Platform. Designed to balance quality, speed, and cost-effectiveness, our models are complemented by flexible deployment options. Customers can access them through our platform’s API or opt for deployment on their own infrastructure, whether through a Virtual Private Cloud (VPC) or directly within their data centers.
If you’re interested in exploring our LLMs firsthand, we encourage you to sign up for a free trial of our API.
For those curious about our VPC and on-premises deployment options, we encourage you to book a 1:1 session with our experts.