Introduction
Since the introduction of ChatGPT, businesses everywhere have eagerly sought to leverage Large Language Models (LLMs) to elevate their operations and offerings. The potential of LLMs is vast, but there’s a catch: even the most powerful pretrained LLM might not always meet your specific needs right out of the box. Here’s why:
- Tailored Outputs: Your application might demand a unique structure or style. Imagine a writing assessment tool that grades an essay and offers a concise bullet-point feedback.
- Missing Context: The pretrained LLM might not know about specific documents crucial to your application. Consider a chatbot fielding technical queries about a particular set of products. If the instruction manuals for those products weren’t in the LLM’s training data, its accuracy can falter.
- Specialized Vocabulary: Certain domains, industries, and even particular enterprises often have unique terminologies, concepts, and structures not prominently represented in the general pretraining data. Thus, a pretrained LLM might find it challenging to summarize, or answer questions about, financial data, medical research papers, or even transcripts of company meetings.
So, how do you make an LLM align with your unique requirements? You’ll likely need to tweak or “tune” it. Currently, there are four prominent tuning methods:
- Full Fine-tuning: Adjusts all parameters of the LLM using task-specific data.
- Parameter-efficient Fine-tuning (PEFT): Modifies select parameters for more efficient adaptation.
- Prompt Engineering: Refines model input to guide its output.
- RAG (Retrieval Augmented Generation): Merges prompt engineering with database querying for context-rich answers.
They vary in expertise needed, cost, and suitability for different scenarios. This article explores each, shedding light on their nuances, costs, and optimal use cases. Dive in to discover which method is the best fit for your project.
Full fine-tuning
Fine-tuning is the process we use to further train an already pre-trained LLM on a smaller, task-specific, labeled dataset. In this way, we adjust some of the model parameters to optimize its performance for a particular task or set of tasks. In full fine-tuning, all the model parameters are updated, making it similar to pretraining—just that it’s done on a labeled and much smaller dataset.
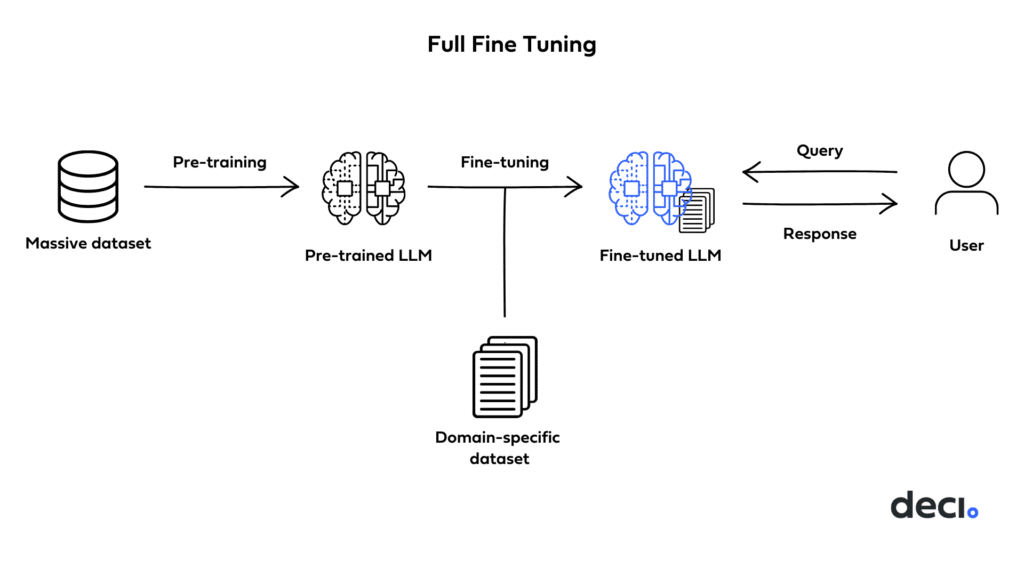
Full fine-tuning in 6 steps
To illustrate, let’s say we want to build a tool that generates abstracts for biotechnology research papers. For full fine-tuning, you’ll need to go through the following steps:
1. Create the dataset
- Collect a set of research papers from the target domain of biotechnology. Ensure each paper comes with its original abstract.
- Split this collection into training, validation, and test sets.
2. Preprocess the data
- Convert each research paper into a format amenable to the model.
- Pair each processed paper content with its corresponding abstract to form input-output pairs for supervised training.
3. Configure the model:
- Load the pre-trained LLM (e.g., a pre-trained version of GPT-4).
- Decide on hyperparameters for fine-tuning, such as learning rate, batch size, and number of epochs, based on preliminary tests or domain knowledge.
4. Train the model:
- Feed the processed content to the LLM as input and train it to generate the corresponding abstract as the output.
- Monitor the model’s performance on the validation set to prevent overfitting and to decide when to stop training or make adjustments.
5. Evaluate performance:
- Once fine-tuning is complete, assess the model’s performance on the test set, which it hasn’t seen before.
- Metrics might include the BLEU score, ROUGE score, or human evaluations to measure the quality and relevance of the generated abstracts as compared to the original ones.
6. Iterate until performance is satisfactory:
- Based on evaluation results, iterate on the above steps, possibly collecting more data, adjusting hyperparameters, or trying different model configurations to improve performance.
What makes full fine-tuning worthwhile?
Requires less data than training from scratch
Full fine-tuning can be effective even with a relatively small task-specific dataset. The pretrained LLM already understands general language constructs. The fine-tuning process focuses primarily on adjusting the model’s knowledge to the specificities of the new data. A pretrained LLM, initially trained on roughly 1 trillion tokens and demonstrating solid general performance, can be efficiently fine-tuned with just a few hundred examples, equivalent to several hundred thousand tokens.
Enhanced accuracy
By fine-tuning on a task-specific dataset, the LLM can grasp the nuances of that particular domain. This is especially vital in areas with specialized jargon, concepts, or structures, such as legal documents, medical texts, or financial reports. As a result, when faced with unseen examples from the specific domain or task, the model is likely to make predictions or generate outputs with higher accuracy and relevance.
Increased robustness
Fine-tuning allows us to expose the model to more examples, especially edge cases or less common scenarios in the domain-specific dataset. This makes the model better equipped to handle a wider variety of inputs without producing erroneous outputs.
The downside of full fine-tuning
High computational costs
Full fine-tuning involves updating all the parameters of a large model. With large-scale LLMs boasting tens or hundreds of billions of parameters, training requires enormous amounts of computing power. Even when the fine-tuning dataset is relatively small, the number of tokens can be huge and expensive to compute.
Substantial memory requirements
Working with large models can necessitate specialized hardware, such as high-end GPUs or TPUs, with significant memory capacities. This is often impractical for many businesses.
Time & Expertise Intensive
When the model is very large, you often need to distribute the computation over multiple GPUs and nodes. This requires appropriate expertise. Depending on the size of the model and the dataset, fine-tuning can take hours, days, or even weeks.
Parameter-efficient fine-tuning
Parameter-efficient fine-tuning (PEFT) uses techniques to further tune a pretrained model by updating only a small number of its total parameters. A large language model pretrained on vast amounts of data has already learned a broad spectrum of language constructs and knowledge. In short, it already possesses much of the information needed for many tasks. Given the smaller scope, it’s often unnecessary and inefficient to adjust the entire model. The fine-tuning process is conducted on a small set of parameters.
PEFT methods vary in their approach to determining which components of the model are trainable. Some techniques prioritize training select portions of the original model’s parameters. Others integrate and train smaller additional components, like adapter layers, without modifying the original structure.
LoRA
LoRA, short for Low-Rank Adaptation of Large Language Models, was introduced in early 2023. It has since become the most commonly used PEFT method, helping companies and researchers reduce their fine-tuning costs. Using reparameterization, this technique downsizes the set of trainable parameters by performing low-rank approximation.
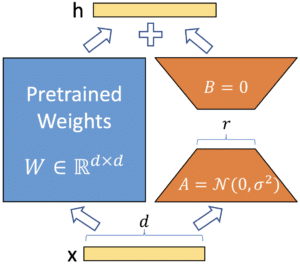
For example, if we have a 100,000 x 100,000 weight matrix, then for full fine-tuning we need to update 10,000,000,000 parameters. Using LoRA, we can capture all or most of the crucial information by using a low-rank matrix that contains the selected parameters updated during fine-tuning.
To get this low-rank matrix, we can reparametrize the original weight matrix into two matrices, A and B, each of low rank r. Our new low-rank matrix is then taken to be the product of A and B. If r = 2, we end up updating (100,000 x 2) + (100,000 x 2) = 400,000 parameters instead of 10,000,000. By updating a much smaller number of parameters, we reduce the computational and memory requirements needed for fine-tuning. The following graphic from the original paper on LoRA illustrates the technique.
The following are some of the advantages of LoRA:
- Task switching efficiency – Creating different versions of the model for specific tasks becomes easier. You can simply store a single copy of the pretrained weights and build many small LoRA modules. When you switch from task to task you replace only the matrices, A and B, and keep the LLM. This significantly reduces storage requirements.
- Fewer GPUs required – LoRA reduces GPU memory requirements by up to 3x since we don’t calculate/retrain gradients for most parameters.
- High accuracy – On a variety of evaluation benchmarks, LoRA performance proves to be almost equivalent to full fine-tuning—at a fraction of the cost. For example, Deci’s DeciLM 6B was fine-tuned using LoRA for instruction following. The fine-tuned model, DeciLM 6B-Instruct matches the performance of top-tier models in its class.
Because it’s so new, LoRA’s efficacy in situations where you need to fine-tune a model on multiple tasks is still untested. In such situations, the pre-trained LLM needs to be fine-tuned on each task sequentially, and it remains to be seen whether LoRA can maintain the accuracy of full fine-tuning.
For a step-by-step guide on using LoRA to fine-tune Llama 2 7B, read our technical blog post.
Where PEFT beats full fine-tuning
More efficient and faster training – Fewer parameter tweaks mean fewer calculations, which translates directly into speedier training sessions that require less computing power and fewer memory resources. This makes fine-tuning in resource-tight scenarios more practical.
Preserving knowledge from pretraining – Extensive pre-training on broad datasets packs models with invaluable general knowledge and capabilities. With PEFT, we ensure that this treasure trove isn’t lost when adapting the model to novel tasks because we retain most or all of the original model weights.
Whether or not PEFT is an effective alternative to full fine-tuning depends on the use case and the particular PEFT technique selected. In PEFT you train a much smaller number of parameters than in full fine-tuning and, if the task is “hard enough,” the difference in the number of parameters trained will show.
Prompt engineering
The methods discussed so far involve training model parameters on a new dataset and task, using either all of the pretrained weights, as in full fine tuning, or a separate set of weights as in LoRA. In contrast, prompt engineering doesn’t involve training network weights at all. It is the process of designing and refining the input given to a model to guide and influence the kind of output you want.
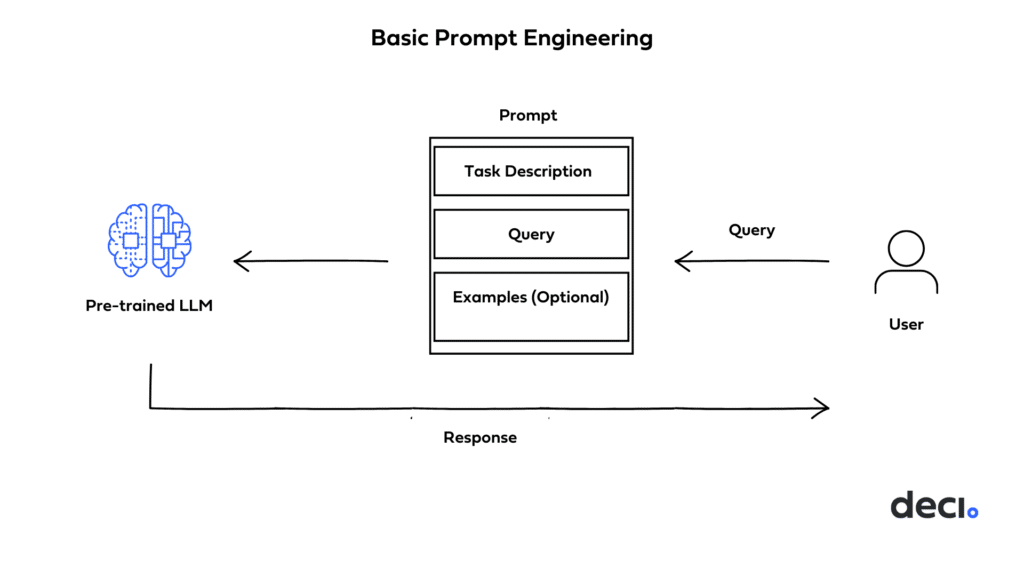
Basic Prompting Techniques
Very large LLMs such as GPT4 are tuned to follow instructions, can generalize from very few examples based on the diverse patterns they’ve seen during training, and exhibit basic reasoning abilities. Prompt engineering leverages these capabilities to elicit desired responses from the model.
Zero-shot prompting
In zero-shot prompting, we prepend a certain instruction to the user’s query without providing the model with any direct examples.
Imagine you’re developing a tech support chatbot using a large language model. To make sure the model focuses on providing tech solutions without having prior examples, you can prepend a specific instruction to all user inputs:
Prompt:
Provide a tech support solution based on the following user concern. User concern: My computer won't turn on. Solution:
By prepending an instruction to the user query (“My computer won’t turn on,” we give the model context for the kind of answer desired. This is a way of adapting its output for tech support even without explicit examples of tech solutions.
Few-shot prompting
In few-shot prompting, we prepend a few examples to the user’s query. These examples are essentially pairs of sample input and expected model output.
Imagine creating a health app that categorizes dishes into ‘Low Fat’ or ‘High Fat’ using a language model. To orient the model, a couple of examples are prepended to the user query:
Classify the following dish based on its fat content: Grilled chicken, lemon, herbs. Response: Low Fat Classify the following dish based on its fat content: Mac and cheese with heavy cream and butter. Response: High Fat Classify the following dish based on its fat content: Avocado toast with olive oil Response:
Informed by the examples in the prompt, a large enough and well trained LLM will reliably respond: “High Fat.”
Few-shot prompting is a good way of getting the model to adopt a certain response format. Going back to our tech support app example, if we wanted the model’s response to conform to a certain structure or length restrictions, we could do so through few-shot prompting.
Chain-of-thought prompting
Chain-of-thought prompting allows for detailed problem-solving by guiding the model through intermediate steps. Pairing it with few-shot prompting can enhance performance on tasks that need thoughtful analysis before generating an answer.
Subtracting the smallest number from the largest in this group results in an even number: 5, 8, 9. A: Subtracting 5 from 9 gives 4. The answer is True. Subtracting the smallest number from the largest in this group results in an even number: 10, 15, 20. A: Subtracting 10 from 20 gives 10. The answer is True. Subtracting the smallest number from the largest in this group results in an even number: 7, 12, 15. A:
In fact, chain of thought prompting can also be paired with zero shot prompting to enhance performance on tasks that require step-by-step analysis. Going back to our tech support app example, if we wanted to improve the model’s performance, we could ask it to break down the solution step by step.
Break down the tech support solution step by step based on the following user concern. User concern: My computer won't turn on. Solution:
For a variety of applications, basic prompt engineering of a very large LLM can deliver ‘good enough’ accuracy. It provides an economical adaptation method because it is fast and doesn’t involve large amounts of computing power. The downside is that it’s simply not accurate or robust enough for use cases additional background knowledge is required.
Retrieval Augmented Generation (RAG)
Introduced by Meta researchers, Retrieval Augmented Generation (RAG) is a powerful technique that combines prompt engineering with context retrieval from external data sources to improve the performance and relevance of LLMs. By grounding the model on additional information, it allows for more accurate and context-aware responses.
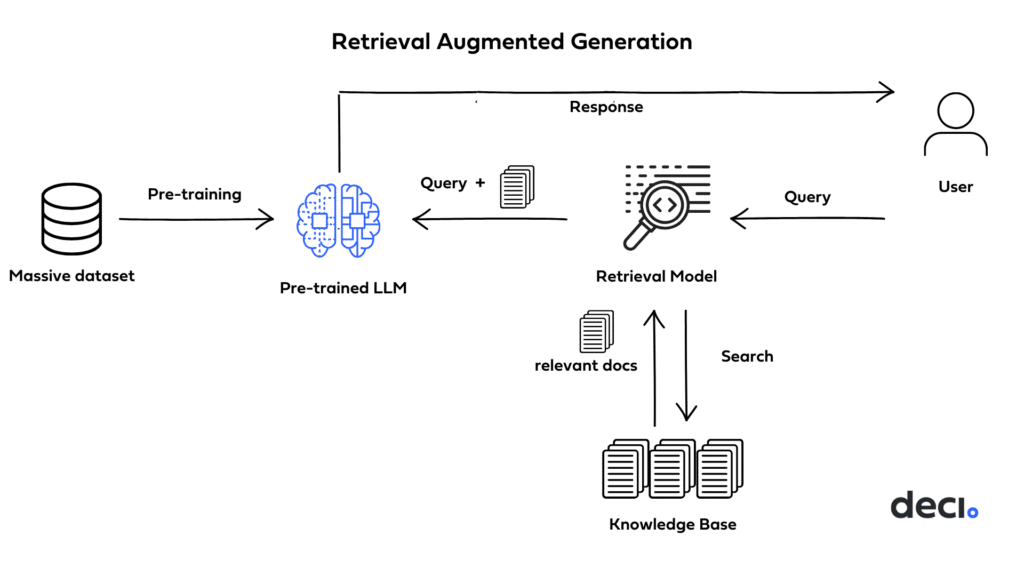
How does RAG work?
RAG essentially couples information retrieval mechanisms with text generation models. The information retrieval component helps pull in relevant contextual information from a database, and the text generation model uses this added context to produce a more accurate and “knowledgeable” response. Here’s how it works:
- Vector database: Implementing RAG involves embedding the internal dataset, creating vectors from it, and storing them in a vector database.
- User query: RAG takes a user query from the prompt, which is a natural language question or statement that needs to be answered or completed.
- Retrieval component: Once it receives a user’s query, the retrieval component scans the vector database to identify chunks of information that bear semantic resemblance to the query. These relevant pieces are then used to provide additional context to the LLM, allowing it to generate a more accurate and contextually aware response.
- Concatenation: The retrieved documents are concatenated with the original query into a prompt that provides additional context for generating responses.
- Text generation: The prompt, which includes the concatenated query and retrieved documents, is fed to an LLM to produce the final output.
For a practical guide to using RAG, we recommend our technical blog on how to build a RAG system using LangChain.
RAG use cases
RAG is especially useful when an application requires the LLM to base its responses on a large set of documents that are specific to the application’s context. These applications can include a wide variety of familiar tasks. Examples include a technical support chatbot that pulls from the company’s instruction manuals and technical documents to answer customer questions and an internal question and answer app that has access to an enterprise’s internal documentation and can supply answers based on these documents.
RAG is also useful when the application needs to use up-to-date information and documents that weren’t a part of the LLMs training set. Some examples might be news databases or applications that search for medical research associated with new treatments.
Simple prompt engineering can’t handle these cases because of the limited context window of the LLM. Currently, for most use cases you can’t feed the entire set of documents into the prompt of the LLM.
Advantages of RAG
RAG has a number of distinct advantages:
Minimizes hallucinations – When the model makes ‘best-guess’ assumptions, essentially filling in what it ‘doesn’t know’, the output can be incorrect or pure nonsense. Compared to simple prompt engineering, RAG produces results that are more accurate with a lower-chance of hallucinations.
Easily adapts to new data – RAG can adapt in situations where facts could evolve over time, making it useful for generating responses that require up-to-date information.
Interpretable – Using RAG, the source of the LLM’s answer can be pinpointed. Having traceability regarding the source of an answer can be beneficial for internal monitoring, quality assurance, or addressing customer disputes.
Cost effective – Instead of fine-tuning the entire model on the task-specific dataset, you can get comparable results with RAG, which involves far less labeled data and computing resources.
RAG’s potential limitations
RAG is designed to enhance an LLM’s information retrieval capabilities by drawing context from external documents. However, in certain use cases additional context is not enough. If a pretrained LLM struggles with summarizing financial data, or drawing insights from a patient’s medical documentation, it is hard to see how additional context in the form of a single document could help. In such a case, fine-tuning is more likely to result in the desired output.
Choosing the right approach for your application
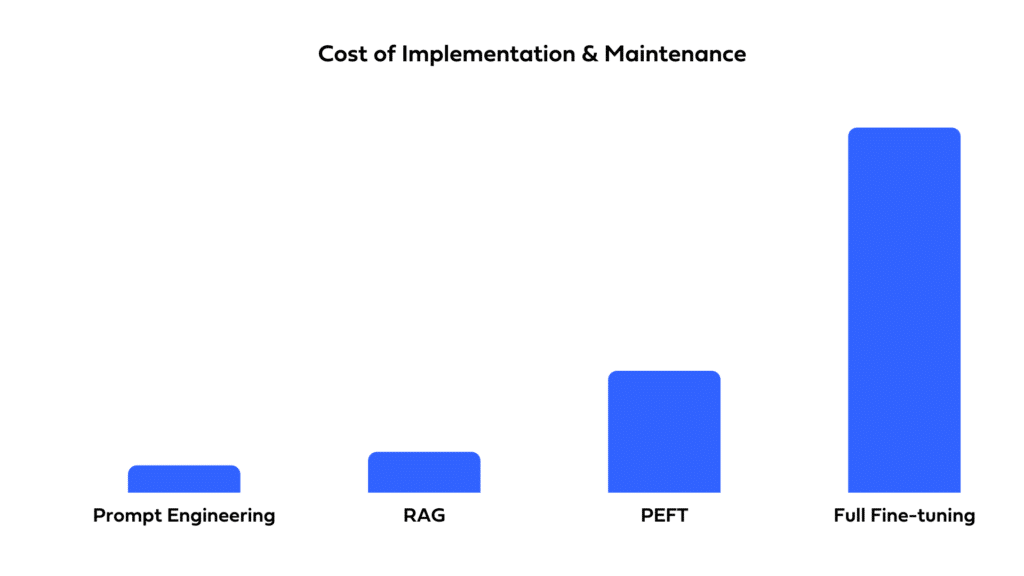
After reviewing the four approaches to LLM adaptation, let’s compare them on three important metrics: complexity, cost, and accuracy.
Cost
When measuring the cost of an approach, it makes sense to take into consideration the cost of its initial implementation, along with the cost of maintaining the solution. Given that, let’s compare the costs of our four approaches.
Prompt engineering – Prompt engineering has the lowest cost of the four approaches. It boils down to writing and testing prompts to find ones that deliver good results when fed to the pretrained LLM. It may also involve updating prompts if the pretrained model is itself updated or replaced. This can happen periodically when using a commercial model like OpenAI’s GPT4.
RAG – The cost of implementing RAG may be higher than that of prompt engineering. This is because of the need for multiple components: embedding model, vector store, vector store retriever, and pretrained LLM.
PEFT: The cost of PEFT tends to be higher than that of RAG. This is because fine-tuning, even efficient fine-tuning, requires a considerable amount of computing power, time, and ML expertise. Moreover, to maintain this approach, you’ll need to fine-tune periodically to incorporate new relevant data into the model.
Full fine-tuning – This method is significantly more costly than PEFT, given that it requires even more compute power and time.
Complexity of implementation
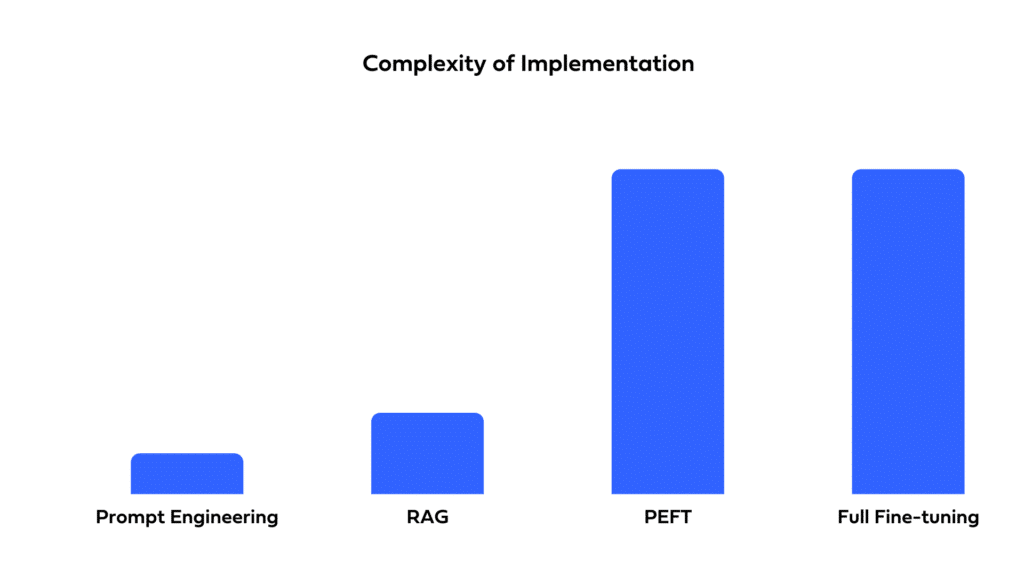
From the relatively straightforward approach of prompt engineering to the more intricate configurations of RAG and advanced tuning methods, the complexity can vary significantly. Here’s a quick rundown on what each method entails:
Prompt engineering – This method has relatively low implementation complexity. It requires little to no programming. To draft a good prompt and conduct experiments, a prompt engineer needs good language skills, domain expertise, and familiarity with few-shot learning approaches.
RAG – This approach has higher implementation complexity than prompt engineering. To implement this solution, you need coding and architecture skills. Depending on the RAG components chosen, the complexity could run very high.
PEFT and Full fine-tuning – These approaches are the most complex to implement. They demand a deep understanding of deep learning and NLP and expertise in data science to change the model’s weights via tuning scripts. You’ll also need to consider factors such as the training data, learning rate, loss function, etc.
Accuracy
Evaluating the accuracy of different approaches for LLM adaptation can be intricate, especially because the accuracy often hinges on a blend of distinct metrics. The significance of these metrics can fluctuate based on the specific use case. Certain applications might prioritize domain-specific jargon. Others might prioritize the ability to trace the model’s response back to a particular source. To find the most accurate approach for your needs, it’s imperative to identify the pertinent accuracy metrics for your application and compare the methodologies against those specific criteria.
Let’s take a look at some accuracy metrics.
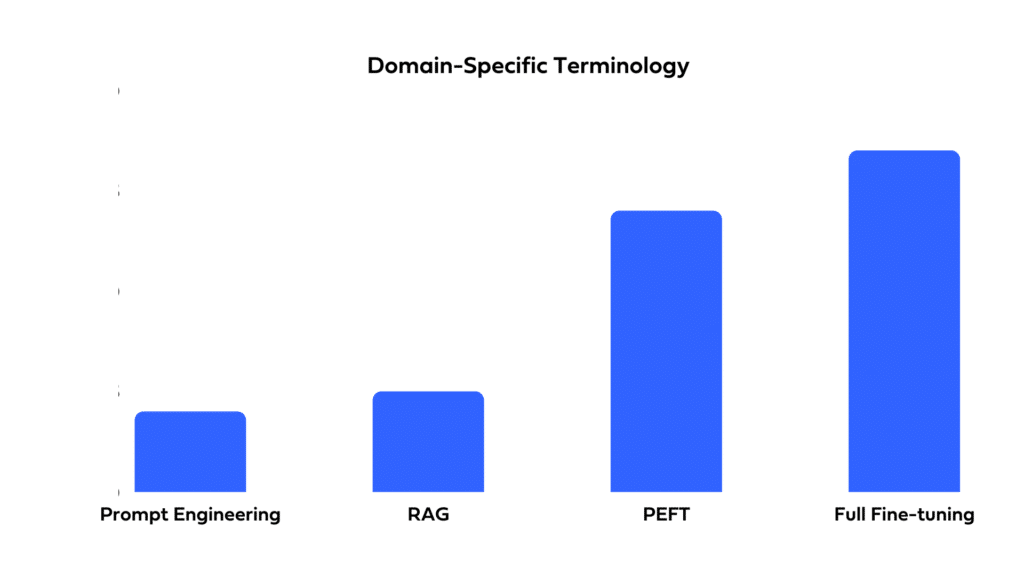
Domain-specific terminology
Fine-tuning can be used to effectively impart LLMs with domain-specific terminology. While RAG is proficient in data retrieval, it may not capture domain-specific patterns, vocabulary and nuances as well as a fine-tuned model. For tasks seeking strong domain affinity, fine-tuning is the way to go.
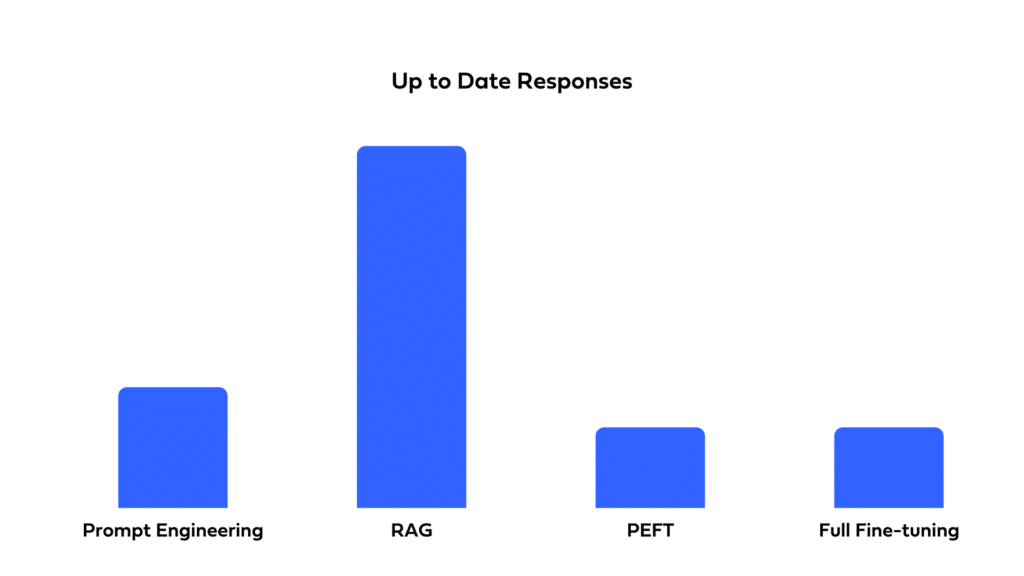
Up-to-date responses
A fine-tuned LLM becomes a fixed snapshot of its training dataset and will need regular retraining for data that is evolving. This makes exclusive fine-tuning (both full and PEFT) a less viable approach for applications that require responses to be synced with a dynamic pool of information. In contrast, RAG’s external queries can ensure updated responses, making it ideal for environments with dynamic data.
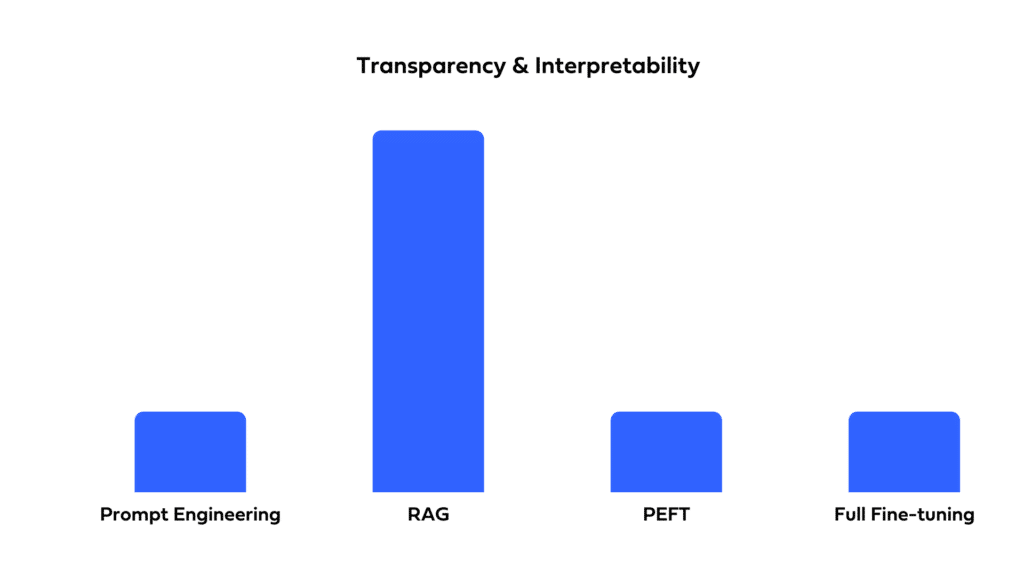
Transparency and Interpretability
For some applications, understanding the model’s decision-making is crucial. While fine-tuning functions more like a ‘black box’, obscuring its reasoning, RAG provides clearer insight. Its two-step process identifies the documents it retrieves, enhancing user trust and comprehension.
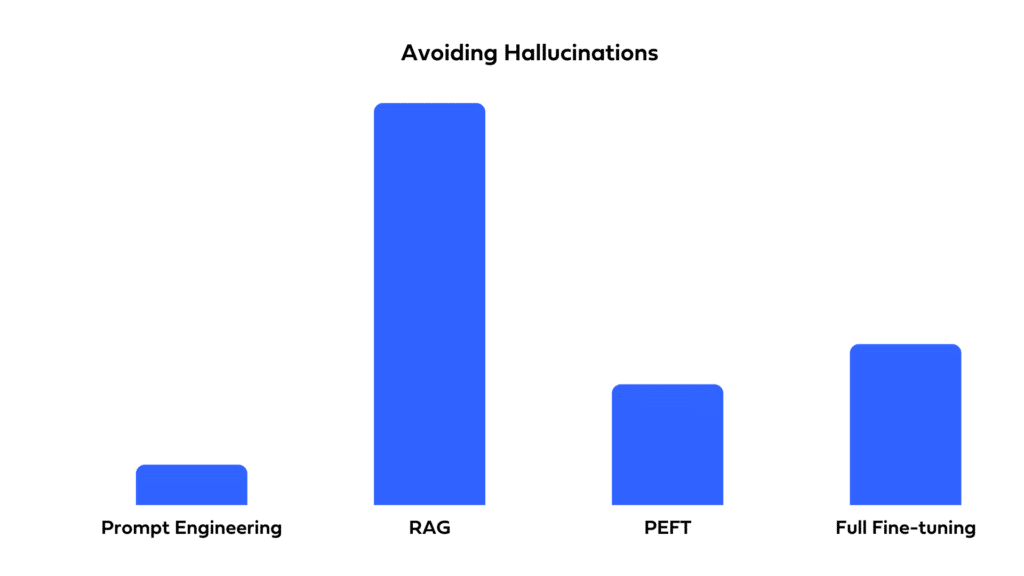
Hallucinations
Pretrained LLMs sometimes make up answers that are missing from their training data or the provided input. Fine-tuning can reduce these hallucinations by focusing an LLM on domain specific data. However, unfamiliar queries may still cause the LLM to concoct a made up answer. RAG reduces hallucinations by anchoring the LLM’s response in the retrieved documents. The initial retrieval step essentially fact checks while the subsequent generation is restricted to the context of the retrieved data. For tasks where avoiding hallucinations is paramount, RAG is recommended.
We see that RAG is excellent for cases where interpretability, up-to-date responses, and avoiding hallucinations are paramount. Full fine-tuning and PEFT are clear winners for use cases that put most of the weight on domain-specific style and vocabulary. But what if your use case requires both? In that case, you might want to consider a hybrid approach, using both fine-tuning and RAG.
The road ahead to LLM adaptation
To determine the best approach for adapting an LLM to your needs, you’ll need to go beyond budgetary constraints and available expertise, and delve into the specific requirements of the application. What aspects of LLM accuracy hold the highest significance for you? Is preventing hallucinations paramount, or do you place greater value on the LLM’s creative capabilities? How vital is it for your LLM to stay updated with fresh data, and is this something you can achieve with prompt modifications—like updating interest rates—or does the frequency or complexity of the information demand a strategy like retrieval augmented generation? Could a single adaptation strategy be sufficient, or might a combination serve you better?
Knowing what questions need answering is the first step to navigating your optimal course of action.
Next Phase: Addressing LLM Deployment Challenges Effectively
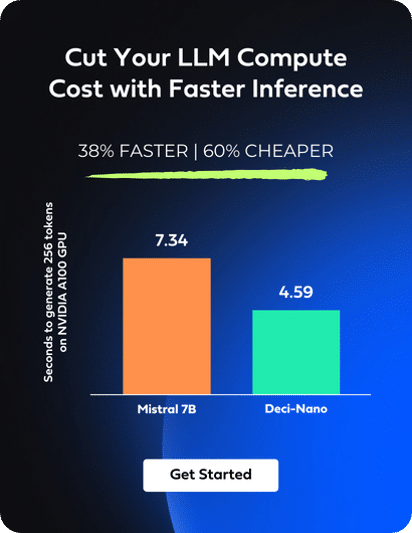
In this blog, we’ve delved into the intricate process of customizing LLMs for specific applications. Once you’ve fine-tuned your LLM, the next critical step is deployment, a phase that introduces practical challenges, primarily in terms of latency, throughput, and cost.
LLMs demand intricate computational processes, which can lead to significant latency issues, negatively impacting user experiences, especially in applications that require real-time responses. A major hurdle is the low throughput, which causes delayed responses and hinders the handling of concurrent user requests. This situation typically necessitates the use of costlier, high-performance hardware to improve throughput, thereby elevating operational expenses. Consequently, the need for such advanced hardware compounds the already substantial computational costs associated with implementing these models.
Infery-LLM by Deci presents an effective solution to these problems. This Inference SDK significantly improves LLM performance, offering up to a five-times increase in speed without compromising on accuracy, leading to reduced latency and quicker, more efficient outputs. Importantly, it makes better use of computational resources, allowing for the use of larger models on more cost-effective GPUs, thereby lowering the total operational costs.
When combined with Deci’s open-source models, such as DeciCoder or DeciLM-7B, the efficiency of Infery-LLM is notably increased. These highly accurate and efficient models integrate smoothly with the SDK, boosting its effectiveness in reducing latency and cutting down costs.
Enabling inference with just three lines of code, Infery-LLM makes it easy to deploy into production and into any environment. Its optimizations unlock the true potential of LLMs, as exemplified when it runs DeciLM-7B, achieving 4.4x the speed of Mistral 7B with vLLM with a 64% reduction in inference costs.
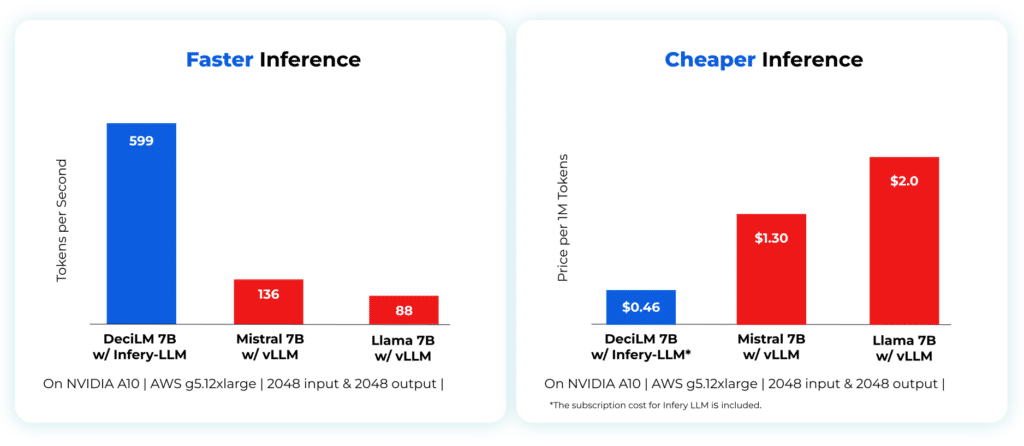
Infery’s approach to optimizing LLMs enables significant performance improvements on less powerful hardware, as compared to other approaches on vLLM or PyTorch even on high-end GPUs, significantly reducing the overall cost of ownership and operation. This shift not only makes LLMs more accessible to a broader range of users but also opens up new possibilities for applications with resource constraints.

In conclusion, Infery-LLM is essential for overcoming the challenges of latency, throughput, and cost in deploying LLMs, becoming an invaluable asset for developers and organizations utilizing these advanced models.
To experience the full capabilities of Infery-LLM, we invite you to get started today.