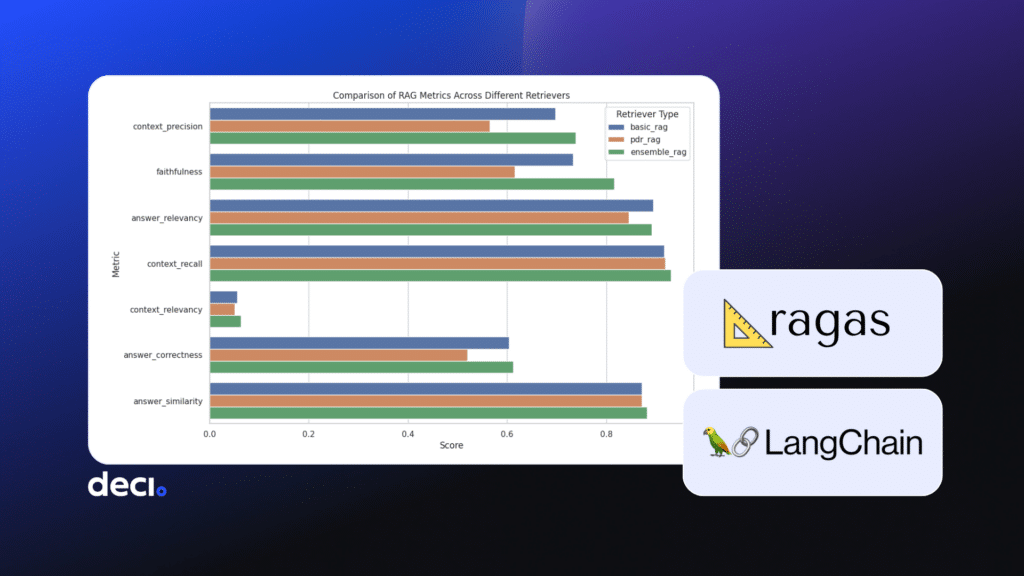
In this post, you’ll learn about creating synthetic data, evaluating RAG pipelines using the Ragas tool, and understanding how various retrieval methods shape your RAG evaluation metrics.
My journey with AI Makerspace’s LLMOps cohort (learn more here) has been instrumental in shaping my approach to these topics. This exploration is a direct application and extension of knowledge gained from the LLMOps program. In fact, the core of this post is a remixed version of a homework assignment from the cohort. I had a conversation with Chris Alexiuk (connect with him), the homework assignments author, and co-founder of AI Makerspace. He’s given a thumbs-up to remix his work for this blog and I credit him as coauthor, since I’ve made use of the valuable insights I’ve learned from him.
Here’s what you’ll learn in this blog:
- 🧪 Synthetic Data Creation: Understanding the process and importance of generating synthetic data for RAG evaluation.
- 🛠️ Utilizing the Ragas Tool: Learning how to use Ragas for a comprehensive assessment of RAG model performance across various metrics.
- 🔍 Impact of Retrieval Methods: Exploring how different retrieval approaches influence the effectiveness and accuracy of RAG models.
- 💡 Practical Application: Applying these concepts through examples and exercises to solidify understanding and skills in RAG evaluation.
Let’s begin our exploration, starting with the essentials of synthetic data creation, moving through the detailed process of RAG evaluation using ragas, and delving into the subtle influences of different retrieval methods. For a helpful primer on building a RAG system using LangChain, refer to this blog post.
%%capture !pip install -U langchain !pip install -U openai !pip install -U ragas !pip install -U arxiv !pip install -U pymupdf !pip install -U chromadb !pip install -U tiktoken !pip install -U accelerate !pip install -U bitsandbytes !pip install -U datasets !pip install -U sentence_transformers !pip install -U FlagEmbedding !pip install -U ninja !pip install -U flash_attn --no-build-isolation !pip install -U tqdm !pip install -U rank_bm25 !pip install -U transformers
import os
import openai
from getpass import getpass
openai.api_key = getpass("Please provide your OpenAI Key: ")
os.environ["OPENAI_API_KEY"] = openai.api_key
Data Collection
Let’s start by loading papers from arXiv.
In a rather ironic manner, I’m choosing to pick papers about evaluating LLMs, including some papers about evaluating RAG pipelines. You can collect these documents individually using the ArxivLoader document loader from LangChain, and then merge them into one document object.
- Evaluation Metrics in the Era of GPT-4: Reliably Evaluating Large Language Models on Sequence to Sequence Tasks
- A Survey on Evaluation of Large Language Models
- An Evaluation on Large Language Model Outputs: Discourse and Memorization
- A Closer Look into Automatic Evaluation Using Large Language Models
- Large Language Models are Not Yet Human-Level Evaluators for Abstractive Summarization
- ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
- RaLLe: A Framework for Developing and Evaluating Retrieval-Augmented Large Language Models
- Benchmarking Large Language Models in Retrieval-Augmented Generation
- Evaluating the Effectiveness of Retrieval-Augmented Large Language Models in Scientific Document Reasoning
Let’s grab these documents using the ArxivLoader and then merge them together using the MergedDataLoader.
from langchain.document_loaders import ArxivLoader
from langchain.document_loaders.merge import MergedDataLoader
papers = ["2310.13800", "2307.03109", "2304.08637", "2310.05657", "2305.13091", "2311.09476", "2308.10633", "2309.01431", "2311.04348"]
docs_to_merge = []
for paper in papers:
loader = ArxivLoader(query=paper)
docs_to_merge.append(loader)
all_loaders = MergedDataLoader(loaders=docs_to_merge)
all_docs = all_loaders.load()
for doc in all_docs: print(doc.metadata)
{'Published': '2023-10-20', 'Title': 'Evaluation Metrics in the Era of GPT-4: Reliably Evaluating Large Language Models on Sequence to Sequence Tasks', 'Authors': 'Andrea Sottana, Bin Liang, Kai Zou, Zheng Yuan', 'Summary': "Large Language Models (LLMs) evaluation is a patchy and inconsistent\nlandscape, and it is becoming clear that the quality of automatic evaluation\nmetrics is not keeping up with the pace of development of generative models. We\naim to improve the understanding of current models' performance by providing a\npreliminary and hybrid evaluation on a range of open and closed-source\ngenerative LLMs on three NLP benchmarks: text summarisation, text\nsimplification and grammatical error correction (GEC), using both automatic and\nhuman evaluation. We also explore the potential of the recently released GPT-4\nto act as an evaluator. We find that ChatGPT consistently outperforms many\nother popular models according to human reviewers on the majority of metrics,\nwhile scoring much more poorly when using classic automatic evaluation metrics.\nWe also find that human reviewers rate the gold reference as much worse than\nthe best models' outputs, indicating the poor quality of many popular\nbenchmarks. Finally, we find that GPT-4 is capable of ranking models' outputs\nin a way which aligns reasonably closely to human judgement despite\ntask-specific variations, with a lower alignment in the GEC task."}
{'Published': '2023-10-17', 'Title': 'A Survey on Evaluation of Large Language Models', 'Authors': 'Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, Xing Xie', 'Summary': "Large language models (LLMs) are gaining increasing popularity in both\nacademia and industry, owing to their unprecedented performance in various\napplications. As LLMs continue to play a vital role in both research and daily\nuse, their evaluation becomes increasingly critical, not only at the task\nlevel, but also at the society level for better understanding of their\npotential risks. Over the past years, significant efforts have been made to\nexamine LLMs from various perspectives. This paper presents a comprehensive\nreview of these evaluation methods for LLMs, focusing on three key dimensions:\nwhat to evaluate, where to evaluate, and how to evaluate. Firstly, we provide\nan overview from the perspective of evaluation tasks, encompassing general\nnatural language processing tasks, reasoning, medical usage, ethics,\neducations, natural and social sciences, agent applications, and other areas.\nSecondly, we answer the `where' and `how' questions by diving into the\nevaluation methods and benchmarks, which serve as crucial components in\nassessing performance of LLMs. Then, we summarize the success and failure cases\nof LLMs in different tasks. Finally, we shed light on several future challenges\nthat lie ahead in LLMs evaluation. Our aim is to offer invaluable insights to\nresearchers in the realm of LLMs evaluation, thereby aiding the development of\nmore proficient LLMs. Our key point is that evaluation should be treated as an\nessential discipline to better assist the development of LLMs. We consistently\nmaintain the related open-source materials at:\nhttps://github.com/MLGroupJLU/LLM-eval-survey."}
{'Published': '2023-04-17', 'Title': 'An Evaluation on Large Language Model Outputs: Discourse and Memorization', 'Authors': 'Adrian de Wynter, Xun Wang, Alex Sokolov, Qilong Gu, Si-Qing Chen', 'Summary': 'We present an empirical evaluation of various outputs generated by nine of\nthe most widely-available large language models (LLMs). Our analysis is done\nwith off-the-shelf, readily-available tools. We find a correlation between\npercentage of memorized text, percentage of unique text, and overall output\nquality, when measured with respect to output pathologies such as\ncounterfactual and logically-flawed statements, and general failures like not\nstaying on topic. Overall, 80.0% of the outputs evaluated contained memorized\ndata, but outputs containing the most memorized content were also more likely\nto be considered of high quality. We discuss and evaluate mitigation\nstrategies, showing that, in the models evaluated, the rate of memorized text\nbeing output is reduced. We conclude with a discussion on potential\nimplications around what it means to learn, to memorize, and to evaluate\nquality text.'}
{'Published': '2023-10-09', 'Title': 'A Closer Look into Automatic Evaluation Using Large Language Models', 'Authors': 'Cheng-Han Chiang, Hung-yi Lee', 'Summary': 'Using large language models (LLMs) to evaluate text quality has recently\ngained popularity. Some prior works explore the idea of using LLMs for\nevaluation, while they differ in some details of the evaluation process. In\nthis paper, we analyze LLM evaluation (Chiang and Lee, 2023) and G-Eval (Liu et\nal., 2023), and we discuss how those details in the evaluation process change\nhow well the ratings given by LLMs correlate with human ratings. We find that\nthe auto Chain-of-Thought (CoT) used in G-Eval does not always make G-Eval more\naligned with human ratings. We also show that forcing the LLM to output only a\nnumeric rating, as in G-Eval, is suboptimal. Last, we reveal that asking the\nLLM to explain its own ratings consistently improves the correlation between\nthe ChatGPT and human ratings and pushes state-of-the-art (SoTA) correlations\non two meta-evaluation datasets.'}
{'Published': '2023-10-20', 'Title': 'Large Language Models are Not Yet Human-Level Evaluators for Abstractive Summarization', 'Authors': 'Chenhui Shen, Liying Cheng, Xuan-Phi Nguyen, Yang You, Lidong Bing', 'Summary': 'With the recent undeniable advancement in reasoning abilities in large\nlanguage models (LLMs) like ChatGPT and GPT-4, there is a growing trend for\nusing LLMs on various tasks. One area where LLMs can be employed is as an\nalternative evaluation metric for complex generative tasks, which generally\ndemands expensive human judges to complement the traditional automatic metrics\nfor various evaluation dimensions such as fluency and consistency. In this\nwork, we conduct extensive analysis to investigate the stability and\nreliability of LLMs as automatic evaluators for abstractive summarization. We\nfound that while ChatGPT and GPT-4 outperform the commonly used automatic\nmetrics, they are not ready as human replacements due to significant\nlimitations. That is, LLM evaluators rate each candidate system inconsistently\nand are dimension-dependent. They also struggle to compare candidates with\nclose performance and become more unreliable with higher-quality summaries by\nobtaining a lower correlation with humans. In other words, with better\nabstractive summarization systems being introduced at a fast pace, LLMs may\nresult in misleading and unreliable evaluations.'}
{'Published': '2023-11-16', 'Title': 'ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems', 'Authors': 'Jon Saad-Falcon, Omar Khattab, Christopher Potts, Matei Zaharia', 'Summary': 'Evaluating retrieval-augmented generation (RAG) systems traditionally relies\non hand annotations for input queries, passages to retrieve, and responses to\ngenerate. We introduce ARES, an Automated RAG Evaluation System, for evaluating\nRAG systems along the dimensions of context relevance, answer faithfulness, and\nanswer relevance. Using synthetic training data, ARES finetunes lightweight LM\njudges to assess the quality of individual RAG components. To mitigate\npotential prediction errors, ARES utilizes a small set of human-annotated\ndatapoints for prediction-powered inference (PPI). Across six different\nknowledge-intensive tasks in KILT and SuperGLUE, ARES accurately evaluates RAG\nsystems while using a few hundred human annotations during evaluation.\nFurthermore, ARES judges remain effective across domain shifts, proving\naccurate even after changing the type of queries and/or documents used in the\nevaluated RAG systems. We make our datasets and code for replication and\ndeployment available at https://github.com/stanford-futuredata/ARES.'}
{'Published': '2023-10-16', 'Title': 'RaLLe: A Framework for Developing and Evaluating Retrieval-Augmented Large Language Models', 'Authors': 'Yasuto Hoshi, Daisuke Miyashita, Youyang Ng, Kento Tatsuno, Yasuhiro Morioka, Osamu Torii, Jun Deguchi', 'Summary': 'Retrieval-augmented large language models (R-LLMs) combine pre-trained large\nlanguage models (LLMs) with information retrieval systems to improve the\naccuracy of factual question-answering. However, current libraries for building\nR-LLMs provide high-level abstractions without sufficient transparency for\nevaluating and optimizing prompts within specific inference processes such as\nretrieval and generation. To address this gap, we present RaLLe, an open-source\nframework designed to facilitate the development, evaluation, and optimization\nof R-LLMs for knowledge-intensive tasks. With RaLLe, developers can easily\ndevelop and evaluate R-LLMs, improving hand-crafted prompts, assessing\nindividual inference processes, and objectively measuring overall system\nperformance quantitatively. By leveraging these features, developers can\nenhance the performance and accuracy of their R-LLMs in knowledge-intensive\ngeneration tasks. We open-source our code at https://github.com/yhoshi3/RaLLe.'}
{'Published': '2023-09-04', 'Title': 'Benchmarking Large Language Models in Retrieval-Augmented Generation', 'Authors': 'Jiawei Chen, Hongyu Lin, Xianpei Han, Le Sun', 'Summary': 'Retrieval-Augmented Generation (RAG) is a promising approach for mitigating\nthe hallucination of large language models (LLMs). However, existing research\nlacks rigorous evaluation of the impact of retrieval-augmented generation on\ndifferent large language models, which make it challenging to identify the\npotential bottlenecks in the capabilities of RAG for different LLMs. In this\npaper, we systematically investigate the impact of Retrieval-Augmented\nGeneration on large language models. We analyze the performance of different\nlarge language models in 4 fundamental abilities required for RAG, including\nnoise robustness, negative rejection, information integration, and\ncounterfactual robustness. To this end, we establish Retrieval-Augmented\nGeneration Benchmark (RGB), a new corpus for RAG evaluation in both English and\nChinese. RGB divides the instances within the benchmark into 4 separate\ntestbeds based on the aforementioned fundamental abilities required to resolve\nthe case. Then we evaluate 6 representative LLMs on RGB to diagnose the\nchallenges of current LLMs when applying RAG. Evaluation reveals that while\nLLMs exhibit a certain degree of noise robustness, they still struggle\nsignificantly in terms of negative rejection, information integration, and\ndealing with false information. The aforementioned assessment outcomes indicate\nthat there is still a considerable journey ahead to effectively apply RAG to\nLLMs.'}
{'Published': '2023-11-07', 'Title': 'Evaluating the Effectiveness of Retrieval-Augmented Large Language Models in Scientific Document Reasoning', 'Authors': 'Sai Munikoti, Anurag Acharya, Sridevi Wagle, Sameera Horawalavithana', 'Summary': 'Despite the dramatic progress in Large Language Model (LLM) development, LLMs\noften provide seemingly plausible but not factual information, often referred\nto as hallucinations. Retrieval-augmented LLMs provide a non-parametric\napproach to solve these issues by retrieving relevant information from external\ndata sources and augment the training process. These models help to trace\nevidence from an externally provided knowledge base allowing the model\npredictions to be better interpreted and verified. In this work, we critically\nevaluate these models in their ability to perform in scientific document\nreasoning tasks. To this end, we tuned multiple such model variants with\nscience-focused instructions and evaluated them on a scientific document\nreasoning benchmark for the usefulness of the retrieved document passages. Our\nfindings suggest that models justify predictions in science tasks with\nfabricated evidence and leveraging scientific corpus as pretraining data does\nnot alleviate the risk of evidence fabrication.'}
Creating an Index
To create an index you need to do the following:
- Pick a text-splitting method, for example,
RecursiveCharacterTextSplitter,CharacterTextSplitter, etc. - Decide on hyperparameters such as
chunk_size,chunk_overlap, andlength_function - Pick an embeddings model, for example you can use a model from OpenAI or pick an open source embeddings model from the MTEB Leaderboard.
- Pick a vectorstore provider, for example
FAISS,Chroma, etc.
The default recommended text splitter is the RecursiveCharacterTextSplitter, so let’s use that.
This text splitter takes a list of characters. It tries to create chunks based on splitting on the first character, but if any chunks are too large, it then moves on to the next character, and so forth. By default, the characters it tries to split on are ["\n\n", "\n", " ", ""]
In addition to controlling which characters you can split on, you can also control a few other things:
• chunk_size: the maximum size of your chunks (as measured by the length function).
• chunk_overlap: the maximum overlap between chunks. It can be nice to have some overlap to maintain some continuity between chunks (e.g. do a sliding window).
• length_function: how the length of chunks is calculated. Defaults to just counting number of characters, but it’s pretty common to pass a token counter here.
Once the documents are split, we can embed them and send each embedding into our Chroma VectorStore using HuggingFaceBgeEmbeddings.
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
hf_bge_embeddings = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs={'device': 'cuda'},
encode_kwargs=encode_kwargs
)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512,
chunk_overlap = 16,
length_function=len)
docs = text_splitter.split_documents(all_docs)
vectorstore = Chroma.from_documents(docs, hf_bge_embeddings)
After splitting our documents up, you can see we have 1338 chunks of text that we have embedded and sent to our vector database.
len(docs)
1338
As a sanity check, you can verify what the largest chunk size is. It should be less than or equal to 512.
print(max([len(chunk.page_content) for chunk in docs]))
511
Let’s convert our Chroma vectorstore into a retriever with the .as_retriever() method.
base_retriever = vectorstore.as_retriever(search_kwargs={"k" : 5})
Now to give it a test!
We pass a query to our retriever; the retriever will grab chunks that are relevant to our query.
relevant_docs = base_retriever.get_relevant_documents("What are the challenges in evaluating Retrieval Augmented Generation pipelines?")
Since we defined k, the number of chunks to retrieve, as 5 we should expect to see only 5 documents. You can do a sanity check like so:
len(relevant_docs)
5
And you can inspect the retrieved documents, if you’d like.
for doc in relevant_docs:
print(doc.page_content)
print('\n')
Instantiate the LLM, Text Generation Pipeline, and Set Up a QA Chain with a Baseline Retriever
For this tutorial, you’ll use a version of DeciLM-7B that was fine-tuned for RAG tasks by our friends at Ai Bloks. This model, part of their DRAGON series, is known as dragon-deci-7b-v0.
Over the past year and a half, our friends at AI Bloks, creators of LLMWare, have dedicated efforts to developing specialized instruct datasets in specific areas:
- Focused Domains: Concentrating on sectors like financial services, insurance, legal, compliance, and regulatory.
- Closed-Context Analysis: Aiming for answers derived from specific source documents instead of general knowledge.
- Fact-Based Question Answering: Enhancing skills in key-value extraction, concise Q&A, basic analytics, and both short-form (like xsum) and longer-form (bullet lists) summarization.
- Essential RAG Skills: Building targeted training sets for Boolean Yes/No, “not found” recognition, common-sense math and logic, table reading, and multiple-choice questions.
- Concise, Clear Answers: Focusing on brief responses for ease of programmatic handling, correlation with evidence sources, reduced risk of hallucinations, and quicker inference processing.
Their approach involves fine-tuning leading open-source foundation models.
Like us at Deci, they believe that targeted training in specific domains and skills enables smaller models to perform beyond their size, making them highly effective and cost-efficient in RAG workflows and related automation in private cloud environments.
The Ai Bloks team applied their methodology to DeciLM-7B, similar to other 7B foundation models in the Dragon series (such as Mistral, Yi, Llama-2, Stable-LM, RedPajama-INCITE, Falcon). As you can see in the table below, DeciLM-7B has shown the strongest results!
The training for dragon-deci-7b-v0 was conducted on a single Nvidia A100 80GB. They used small batches and gradient accumulation to simulate larger batches, optimizing hyper-parameters over several days. Their training process was straightforward, following best practices with a simple prompt wrapper inspired by EleutherAI, Pythia, and RedPajama, using a ” ” format (which you can see below).
Post-training testing of DeciLM-7B revealed impressive performance, particularly in areas like Not Found classification, Yes-No Boolean classification, and Math/logic, with over 90% accuracy – a first in the DRAGON series.
Inference speeds were notably faster compared to other 7B models, offering an “apples to apples” advantage in speed.
| LLMWare Dragon Model | Base Model | License | Parameters (B) | Score (0-100) | Not Found % | Yes/No % | Math % | Complex Q&A (1-5) | Summarization (1-5) |
|---|---|---|---|---|---|---|---|---|---|
| dragon-yi-6b-v0 | Yi-6b | Yi | 6 | 99.5 | 90% | 87.50% | 77.50% | 4 | 4 |
| dragon-deci-7b-v0 | DeciLM-7b | Apache 2.0 | 7 | 97.5 | 95% | 92.50% | 91.25% | 4 | 4 |
| dragon-llama-7b-v0 | Llama-7b | Llama-2 | 7 | 97.25 | 93% | 95% | 63.75% | 3 | 3 |
| dragon-mistral-7b-v0 | Mistral-7b | Apache 2.0 | 7 | 96.5 | 93% | 97.50% | 81.25% | 4 | 4 |
| dragon-red-pajama-7b-v0 | Red-Pajama-7b | Apache 2.0 | 7 | 96 | 55% | 81.25% | 52.50% | 3 | 3 |
| dragon-deci-6b-v0 | Deci-6b | Llama-2 | 6 | 94.25 | 77.50% | 96.25% | 68.75% | 3 | 3 |
| dragon-stablelm-7b-v0 | StableLM-7b-v2 | CC-BY-SA-4 | 7 | 94 | 85% | 88.75% | 62.50% | 3 | 3 |
| dragon-falcon-7b-v0 | Falcon-7b | Apache 2.0 | 7 | 94 | 75% | 81.25% | 66.75% | 3 | 3 |
| Averages | 96.1 | 82.81% | 90.00% | 70.53% | 3.4 | 3.4 |
Creating a Retrieval Augmented Generation Prompt
Now we can set up a prompt template that will be used to provide the LLM with the necessary contexts, user query, and instructions!
from langchain.prompts import ChatPromptTemplate
template = """<human>: Answer the question based only on the following context. If you cannot answer the question with the context, please respond with 'I don't know':
### CONTEXT
{context}
### QUESTION
Question: {question}
\n
<bot>:
"""
prompt = ChatPromptTemplate.from_template(template)
from operator import itemgetter
import torch
from langchain.llms.huggingface_pipeline import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, GenerationConfig, pipeline
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained("llmware/dragon-deci-7b-v0",
quantization_config = quantization_config,
trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("llmware/dragon-deci-7b-v0",
trust_remote_code=True)
generation_config = GenerationConfig(
max_length=4096,
temperature=1e-3,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id
)
pipeline = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
max_length=4096,
temperature=1e-3,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id
)
deci_dragon = HuggingFacePipeline(pipeline=pipeline)
This code defines a pipeline for a question-answering system with retrieval augmentation, named retrieval_augmented_qa_chain.
It starts by taking a user’s question and uses it both directly as the question and as input to a base retrieval system (base_retriever) to fetch relevant context. The retrieved context and the original question are then passed through a RunnablePassthrough for subsequent use, maintaining the context intact for reference. Finally, the response is generated by a primary question-answering model (deci_dragon), which takes the formatted prompt, consisting of the context and the question, and produces an answer.
The design of this pipeline allows for the integration of external information to enhance the quality of responses to user queries.
retrieval_augmented_qa_chain = (
{"context": itemgetter("question") | base_retriever, "question": itemgetter("question")}
| RunnablePassthrough.assign(context=itemgetter("context"))
| {"response": prompt | deci_dragon, "context": itemgetter("context")}
)
Let’s test it out!
question = "Describe evaluation criteria for retrieval augmented generation pipelines"
result = retrieval_augmented_qa_chain.invoke({"question" : question})
print(result['response'])
1. Noise Robustness - how well does the system handle noise in the input? 2. Negative Rejection - how well does the system reject negative responses? 3. Information Integration - how well does the system integrate information? 4. Counterfactual Robustness - how well does the system handle false information?
Create a Synthetic Dataset For RAG Evaluation Using GPT-3.5-turbo and GPT-4
Note: The next section might take you a long time to run.
To evaluate Retrieval-Augmented Generation (RAG) pipelines effectively using LangChain, you need to create a synthetic dataset with four essential components:
- 🤔 Questions: These are the prompts your RAG model will tackle. Make sure your dataset includes a diverse array of questions. This diversity tests the model’s ability to handle a wide range of topics and question complexities.
- 🎯 Ground Truths: These are the correct answers to your questions. You’ll use them as a benchmark to measure how accurately your RAG model responds.
- 🔮 Predicted Answers: These are the responses your RAG model generates. Your key task is to compare these answers against the ground truths to evaluate the model’s accuracy.
- 🌐 Contexts: These provide the necessary background or supplementary information that your RAG model uses to craft its answers. Understanding how your model leverages this context is vital for assessing its effectiveness in incorporating external information into its responses.
📊 Structuring Your Dataset
Organize your dataset in a tabular format. It should have separate columns for each element: questions, ground truths, predicted answers, and contexts. Each row in your table is a unique test case, comprising a question, its correct answer, the RAG model’s response, and the contexts involved.
🛠️ How to Use LangChain for Data Creation
You’ll use LangChain to generate realistic questions and contexts. Then, run these through your RAG model to get the predicted answers. Aim for realism and variety in your dataset to challenge your RAG model and thoroughly evaluate its capabilities.
📝 Using the Dataset for RAG Evaluation
You’ll analyze how closely your RAG model’s predictions match the ground truths and how effectively it uses the provided contexts. This structured approach offers a detailed view of the model’s strengths and improvement areas, shedding light on its performance across varied questions and contexts.
Remember, your goal in creating this synthetic dataset is not just to test your RAG model but to understand it deeply — to uncover its potential and identify where it can grow.
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
question_schema = ResponseSchema(
name="question",
description="a question about the context."
)
question_response_schemas = [
question_schema,
]
📐 ResponseSchema
ResponseSchema is a class that acts as the architectural blueprint for data elements in a response. Imagine it as the template for each piece in a complex puzzle of structured output. Every ResponseSchema instance is defined by:
- 🏷️ Name: Serves as the identifier for the data element, akin to a key in a JSON object.
- 📝 Description: Offers a clear, human-readable explanation of the data element’s role or content.
- 🔠 Type: Indicates the data type (e.g.,
string,list,integer), specifying what the element should store.
ResponseSchema’s key role is to outline each part of a structured response, ensuring the data is both consistent and clear.
🗂️ StructuredOutputParser
StructuredOutputParser is a class crafted for decoding and processing structured outputs, like a detective unraveling the mysteries of data (think JSON) returned from a source (often a language model). This class stands out for:
- 📚 Managing Response Schemas: Utilizes a set of
ResponseSchemaobjects to define the expected blueprint of the output. - 🛠️ Facilitating Structured Output: Generates guides or templates, ensuring the output is predictably structured and easier to handle.
- 🧩 Parsing Capability: Capable of transforming a structured string (such as JSON-formatted text) into a clearly defined format, in line with
ResponseSchemaguidelines.
🌟 High-Level Summary
- 📐
ResponseSchemais the go-to template for setting up the expected format of each response element. - 🗂️
StructuredOutputParserleverages these templates to verify the output’s structure, then parses it into an organized and practical format.
question_output_parser = StructuredOutputParser.from_response_schemas(question_response_schemas) format_instructions = question_output_parser.get_format_instructions()
question_generation_llm = ChatOpenAI(model="gpt-3.5-turbo-1106")
bare_prompt_template = "{content}"
bare_template = ChatPromptTemplate.from_template(template=bare_prompt_template)
Generating questions
from langchain.prompts import ChatPromptTemplate
qa_template = """\
You are a University Professor creating a test for advanced students. For each context, create a question that is specific to the context. Avoid creating generic or general questions.
question: a question about the context.
Format the output as JSON with the following keys:
question
context: {context}
"""
prompt_template = ChatPromptTemplate.from_template(template=qa_template)
messages = prompt_template.format_messages(
context=docs[0],
format_instructions=format_instructions
)
question_generation_chain = bare_template | question_generation_llm
response = question_generation_chain.invoke({"content" : messages})
output_dict = question_output_parser.parse(response.content)
for k, v in output_dict.items(): print(k) print(v)
question What are the specific NLP benchmarks used for the preliminary and hybrid evaluation of generative LLMs in the research?
Generating context
from tqdm import tqdm
import random
random.seed(42)
qac_triples = []
# randomly select 100 chunks from the ~1300 chunks
for text in tqdm(random.sample(docs, 100)):
messages = prompt_template.format_messages(
context=text,
format_instructions=format_instructions
)
response = question_generation_chain.invoke({"content" : messages})
try:
output_dict = question_output_parser.parse(response.content)
except Exception as e:
continue
output_dict["context"] = text
qac_triples.append(output_dict)
100%|██████████| 100/100 [03:58<00:00, 2.39s/it]
qac_triples[5]
{'question': 'What are the three key dimensions focused on in the evaluation methods for Large Language Models (LLMs)?',
'context': Document(page_content='[207] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma,\nDenny Zhou, Donald Metzler, et al. 2022. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682\n(2022).\n[208] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma,\nDenny Zhou, Donald Metzler, Ed Huai hsin Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and', metadata={'Published': '2023-10-17', 'Title': 'A Survey on Evaluation of Large Language Models', 'Authors': 'Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, Xing Xie', 'Summary': "Large language models (LLMs) are gaining increasing popularity in both\nacademia and industry, owing to their unprecedented performance in various\napplications. As LLMs continue to play a vital role in both research and daily\nuse, their evaluation becomes increasingly critical, not only at the task\nlevel, but also at the society level for better understanding of their\npotential risks. Over the past years, significant efforts have been made to\nexamine LLMs from various perspectives. This paper presents a comprehensive\nreview of these evaluation methods for LLMs, focusing on three key dimensions:\nwhat to evaluate, where to evaluate, and how to evaluate. Firstly, we provide\nan overview from the perspective of evaluation tasks, encompassing general\nnatural language processing tasks, reasoning, medical usage, ethics,\neducations, natural and social sciences, agent applications, and other areas.\nSecondly, we answer the `where' and `how' questions by diving into the\nevaluation methods and benchmarks, which serve as crucial components in\nassessing performance of LLMs. Then, we summarize the success and failure cases\nof LLMs in different tasks. Finally, we shed light on several future challenges\nthat lie ahead in LLMs evaluation. Our aim is to offer invaluable insights to\nresearchers in the realm of LLMs evaluation, thereby aiding the development of\nmore proficient LLMs. Our key point is that evaluation should be treated as an\nessential discipline to better assist the development of LLMs. We consistently\nmaintain the related open-source materials at:\nhttps://github.com/MLGroupJLU/LLM-eval-survey."})}
Generate “ground truth” answers using GPT-4
answer_generation_llm = ChatOpenAI(model="gpt-4-1106-preview", temperature=0)
answer_schema = ResponseSchema(
name="answer",
description="an answer to the question"
)
answer_response_schemas = [
answer_schema,
]
answer_output_parser = StructuredOutputParser.from_response_schemas(answer_response_schemas)
format_instructions = answer_output_parser.get_format_instructions()
qa_template = """\
You are a University Professor creating a test for advanced students. For each question and context, create an answer.
answer: a answer about the context.
Format the output as JSON with the following keys:
answer
question: {question}
context: {context}
"""
prompt_template = ChatPromptTemplate.from_template(template=qa_template)
messages = prompt_template.format_messages(
context=qac_triples[0]["context"],
question=qac_triples[0]["question"],
format_instructions=format_instructions
)
answer_generation_chain = bare_template | answer_generation_llm
response = answer_generation_chain.invoke({"content" : messages})
output_dict = answer_output_parser.parse(response.content)
for k, v in output_dict.items(): print(k) print(v)
answer The purpose of the 2S2ORC dataset in the evaluation of scientific document reasoning is to test the ability of retrieval-augmented Large Language Models (LLMs) to understand and reason across a wide range of scientific domains. By covering 19 different scientific disciplines, the dataset provides a comprehensive benchmark to assess whether these models can accurately recognize the domain of a given text passage (as in the FoS task) and make predictions without prompting bias. Furthermore, the dataset allows for the evaluation of the models' ability to avoid hallucinations by retrieving and using factual information from a diverse scientific corpus, thereby enhancing the interpretability and verifiability of the model predictions in scientific document reasoning tasks. question What is the purpose of the 2S2ORC dataset in the evaluation of scientific document reasoning?
for triple in tqdm(qac_triples):
messages = prompt_template.format_messages(
context=triple["context"],
question=triple["question"],
format_instructions=format_instructions
)
response = answer_generation_chain.invoke({"content" : messages})
try:
output_dict = answer_output_parser.parse(response.content)
except Exception as e:
continue
triple["answer"] = output_dict["answer"]
Combine questions, contexts, and answers for evaluation dataset
import pandas as pd
from datasets import Dataset
ground_truth_qac_set = pd.DataFrame(qac_triples)
ground_truth_qac_set["context"] = ground_truth_qac_set["context"].map(lambda x: str(x.page_content))
ground_truth_qac_set = ground_truth_qac_set.rename(columns={"answer" : "ground_truth"})
eval_dataset = Dataset.from_pandas(ground_truth_qac_set)
eval_dataset
Dataset({
features: ['question', 'context', 'ground_truth'],
num_rows: 100
})
eval_dataset[0]
{'question': 'What is the purpose of the 2S2ORC dataset in the evaluation of scientific document reasoning?',
'context': 'test the ability of the models to understand diverse scientific domains and disciplines3. For example,\nFoS task tests the ability of the model to recognize which domain the given text passage belongs to.\nSecond, we want to evaluate on specific instruction template to avoid any prompting bias.\n2S2ORC dataset covers 19 scientific domains; Art, Philosophy, Political-Science, Sociology, Psychology,\nGeography, History, Business, Economics, Geology, Physics, Chemistry, Biology, Mathematics, Computer',
'ground_truth': "The purpose of the 2S2ORC dataset in the evaluation of scientific document reasoning is to test the models' ability to understand and reason across a wide range of scientific domains. It provides a diverse set of scientific texts from 19 different domains, which allows for the assessment of a model's domain recognition capabilities, as exemplified by the Field of Study (FoS) task. Additionally, the dataset helps in evaluating the effectiveness of retrieval-augmented Large Language Models (LLMs) in avoiding prompting bias and reducing the risk of evidence fabrication by leveraging an external knowledge base for information retrieval. This is crucial for ensuring that the model's predictions are factually accurate and can be traced back to verified sources, thereby improving the interpretability and reliability of the model in scientific reasoning tasks."}
RAG Evaluation Using ragas
Alright, let’s dive straight into the popular RAG metrics. Understanding these metrics is key to evaluating your RAG model effectively.
Here we go:
🎯 Answer Relevancy
- What It Measures: This metric assesses how pertinent your RAG model’s answer is to the given prompt. You’re looking for answers that hit the nail on the head, not ones that beat around the bush.
- Scoring: It’s a game of precision, with scores ranging from 0 to 1. Higher scores mean your model’s answers are right on target.
- Example:
- ❓ Question: What causes seasonal changes?
- ⬇️ Low relevance answer: The Earth’s climate varies throughout the year
- ⬆️ High relevance answer: Seasonal changes are caused by the tilt of the Earth’s axis and its orbit around the Sun.
📚 Faithfulness
- What It Measures: Here, you’re checking if the answers stick to the facts provided in the context. It’s all about staying true to the source.
- Scoring: Also on a scale of 0 to 1. Higher values mean your answer is a faithful representation of the context.
- Example:
- ❓ Question: What is the significance of the Apollo 11 mission?
- 📑 Context: Apollo 11 was the first manned mission to land on the Moon in 1969.
- ⬆️ High faithfulness answer: Apollo 11 is significant as it was the first mission to bring humans to the Moon.
- ⬇️ Low faithfulness answer: Apollo 11 was significant for its study of Mars.
🔍 Context Precision
- What It Measures: This one’s about whether your model ranks all the relevant bits of information at the top. You want the most important pieces front and center.
- Scoring: Once again, it’s a 0 to 1 scale. Higher scores indicate your model is doing a great job at prioritizing the right context.
- Example:
- ❓ Question: What are the health benefits of regular exercise?
- ⬆️ High precision: The model ranks contexts discussing cardiovascular health, mental well-being, and muscle strength at the top.
- ⬇️ Low precision: The model prioritizes contexts unrelated to health, such as the history of sports.
✅ Answer Correctness:
- What It Measures: This is about straight-up accuracy – how well does the answer align with the ground truth?
- Scoring: Judged on a 0 to 1 scale, where higher scores signal a bullseye match with the ground truth.
- Example:
- 🟢 Ground Truth: Photosynthesis in plants primarily occurs in the chloroplasts.
- ⬆️ High answer correctness: Photosynthesis takes place in the chloroplasts of plant cells.
- ⬇️ Low answer correctness: Photosynthesis occurs in the mitochondria of plants.
In a nutshell, you’ve got four powerful tools to assess your RAG model. Each metric provides a different lens to view your model’s performance, from how relevant and faithful its answers are, to how precise it is with contexts and how correct its answers align with known truths.
Think of these metrics as your RAG model’s report card – they tell you where it excels and where it needs a bit more homework!
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
context_relevancy,
answer_correctness,
answer_similarity
)
from ragas.metrics.critique import harmfulness
from ragas import evaluate
def create_ragas_dataset(rag_pipeline, eval_dataset):
rag_dataset = []
for row in tqdm(eval_dataset):
answer = rag_pipeline.invoke({"question" : row["question"]})
rag_dataset.append(
{"question" : row["question"],
"answer" : answer["response"],
"contexts" : [context.page_content for context in answer["context"]],
"ground_truths" : [row["ground_truth"]]
}
)
rag_df = pd.DataFrame(rag_dataset)
rag_eval_dataset = Dataset.from_pandas(rag_df)
return rag_eval_dataset
def evaluate_ragas_dataset(ragas_dataset):
result = evaluate(
ragas_dataset,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
context_relevancy,
answer_correctness,
answer_similarity
],
)
return result
Using dragon-deci-7b-v0 to generate answers
Note, generating answers for 100 questions took ~20 minutes on an A100.
from tqdm import tqdm import pandas as pd basic_qa_ragas_dataset = create_ragas_dataset(retrieval_augmented_qa_chain, eval_dataset)
basic_qa_ragas_dataset[0]
{'question': 'What is the purpose of the 2S2ORC dataset in the evaluation of scientific document reasoning?',
'answer': 'The 2S2ORC dataset is a collection of 354M text passages, each with a maximum of 512 tokens, or 100 words that are concatenated with the \r\npassage.',
'contexts': ['Science\nX = French scientists are working on ___ reactor. Y = Sodium\nZero-Shot Prompting\nFigure 2: Experimental setup to measure the effectiveness of retrieval augmented LLMs in scientific\ndocument reasoning tasks. We trained the ATLAS-Science model to evaluate for scientific document\nreasoning tasks. We use the FoS task data in the SciRepEval benchmark to perform instruction tuning\nand evaluate the model in both in-distribution (FoS) and out-of-distribution (MAG) tasks with zero',
'demonstrations during the inference.\ndisciplines than what the models see during the pretraining. We focus on evaluating the Retrieval\nAugmented LLMs on their ability to understand scientific language and retrieve from multiple scien-\ntific knowledge sources. We preprocess the S2ORC [10] dataset to create a collection of 354M text\npassages. Each passage has a maximum of 512 tokens, or 100 words that are concatenated with the',
'ATLAS model variants in two scientific document reasoning tasks. Our experiments on the pretrained\nATLAS model reveal that the model demonstrates acceptable performance in science tasks but the\nevidences are fabricated. We also observe that pretraining the model with scientific corpus does not\nalleviate evidence fabrication. We plan to develop techniques to alleviate these issues in a future\nwork.\n5https://github.com/jerryjliu/llama_index\n5\nAcknowledgements',
'corresponding title of the document the passage belongs to. We record 19 different scientific domains\nin the S2ORC collection2.\nModels\nOur experiments are based on ATLAS (220M) [6] model architecture unless explicitly\nmentioned. ATLAS uses the Fusion-in-decoder architecture to fuse the retrieved text chunks with the\ninput queries during the pretraining. In addition to the ATLAS model pretrained with common crawl\n(CC) and Wikipedia, we also train ATLAS-Science (220M) model from scratch with the S2ORC',
'suggest that the ATLAS model fabricates the evidence to justify the model predictions.\nScientific knowledge provided as pretraining data does not alleviate the evidence fabrication\nTo explore the impact of the pretraining data on downstream scientific tasks, we repeat the evaluation\nwith the ATLAS-Science model (as described in Section 2.2). Note that the ATLAS-Science model is\npretrained from scratch with S2ORC scientific text data provided as both pretraining and external'],
'ground_truths': ["The purpose of the 2S2ORC dataset in the evaluation of scientific document reasoning is to test the models' ability to understand and reason across a wide range of scientific domains. It provides a diverse set of scientific texts from 19 different domains, which allows for the assessment of a model's domain recognition capabilities, as exemplified by the Field of Study (FoS) task. Additionally, the dataset helps in evaluating the effectiveness of retrieval-augmented Large Language Models (LLMs) in avoiding prompting bias and reducing the risk of evidence fabrication by leveraging an external knowledge base for information retrieval. This is crucial for ensuring that the model's predictions are factually accurate and can be traced back to verified sources, thereby improving the interpretability and reliability of the model in scientific reasoning tasks."]}
RAG Evaluation
basic_qa_result = evaluate_ragas_dataset(basic_qa_ragas_dataset)
And we can inspect the results of the evaluation below.
Wow! I must say, I’m quite impressed by the performance of the DRAGON fine-tune of DeciLM-7B!
Let’s break down each metric:
- Context Precision (0.6974): This metric, at approximately 0.70, indicates that the retriever is fairly good at selecting relevant information from the given context. While it’s not perfect, it’s able to prioritize relevant content more often than not.
- Faithfulness (0.7329): A score of around 0.73 suggests that the answers generated are generally faithful to the provided context. This means that the majority of the information in the responses can be traced back to the context, showing a good level of factual consistency.
- Answer Relevancy (0.8950): With a high score close to 0.90, this indicates that the answers are very relevant to the questions. It shows that the retriever is effective at understanding and addressing the specific query.
- Context Recall (0.9171): This impressive score suggests that the retriever is excellent at retrieving almost all relevant pieces of information from the database or context for a given query.
- Context Relevancy (0.0561): This low score is a bit concerning. It implies that the context being retrieved, while comprehensive (as suggested by the high context recall), is not always relevant to the query. This could lead to the retriever pulling in a lot of unnecessary or irrelevant information.
- Answer Correctness (0.6042): This metric is just above average, indicating a moderate level of accuracy in the answers. It suggests that while many answers are correct, there is still a significant portion that may not be entirely accurate.
- Answer Similarity (0.8717): A high score here shows that the answers generated by the retriever are quite similar to the expected answers, indicating a good understanding of the query and the context.
Overall Analysis:
- Strengths: The retriever excels in answer relevancy, context recall, and answer similarity, suggesting it understands queries well and can pull a comprehensive set of relevant data.
- Areas for Improvement: Context relevancy is a major area of concern. Improving the filtering of context to ensure only relevant information is retrieved could enhance other metrics like answer correctness. The answer correctness itself also has room for improvement, suggesting a need to refine how the retriever interprets and uses the context.
This analysis shows a retriever that is competent in understanding and responding to queries, but with potential improvements in the precision of context retrieval and the accuracy of its answers.
# @title
import matplotlib.pyplot as plt
def plot_metrics_with_values(metrics_dict, title='RAG Metrics'):
"""
Plots a bar chart for metrics contained in a dictionary and annotates the values on the bars.
Args:
metrics_dict (dict): A dictionary with metric names as keys and values as metric scores.
title (str): The title of the plot.
"""
names = list(metrics_dict.keys())
values = list(metrics_dict.values())
plt.figure(figsize=(10, 6))
bars = plt.barh(names, values, color='skyblue')
# Adding the values on top of the bars
for bar in bars:
width = bar.get_width()
plt.text(width + 0.01, # x-position
bar.get_y() + bar.get_height() / 2, # y-position
f'{width:.4f}', # value
va='center')
plt.xlabel('Score')
plt.title(title)
plt.xlim(0, 1) # Setting the x-axis limit to be from 0 to 1
plt.show()
plot_metrics_with_values(basic_qa_result, "Base Retriever ragas Metrics")
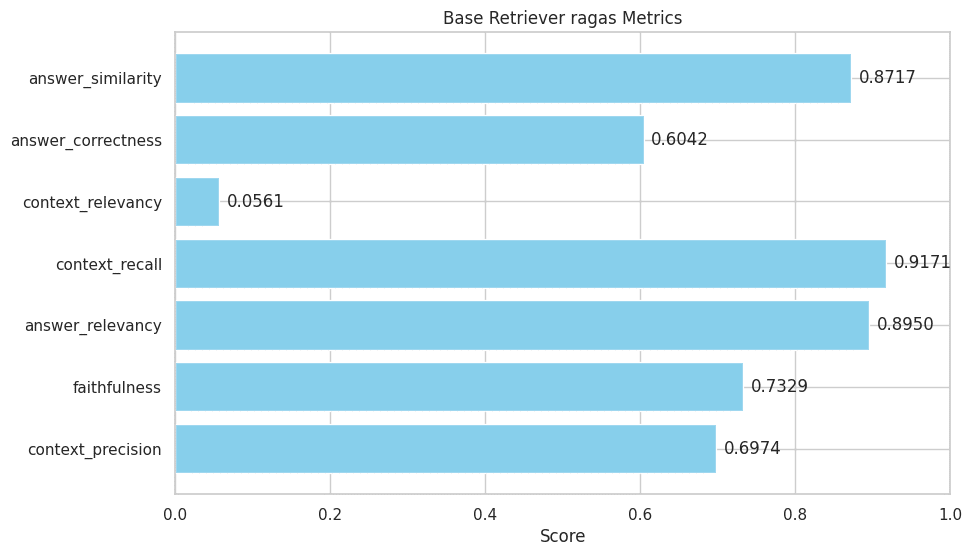
👨🏽🔬 Experimenting With Other Retrievers
Now we can test how changing our Retriever impacts our RAG evaluation!
We’ll build this simple qa_chain factory to create standardized qa_chains where the only different component will be the retriever.
def create_qa_chain(retriever, primary_qa_llm):
created_qa_chain = (
{"context": itemgetter("question") | retriever,
"question": itemgetter("question")
}
| RunnablePassthrough.assign(
context=itemgetter("context")
)
| {
"response": prompt | primary_qa_llm,
"context": itemgetter("context"),
}
)
return created_qa_chain
Parent Document Retriever
One of the easier ways we can imagine improving a retriever is to embed our documents into small chunks, and then retrieve a significant amount of additional context that “surrounds” the found context.
You can read more about this method here!
The basic outline of this retrieval method is as follows:
- Obtain User Question
- Retrieve child documents using Dense Vector Retrieval
- Merge the child documents based on their parents. If they have the same parents – they become merged.
- Replace the child documents with their respective parent documents from an in-memory-store.
- Use the parent documents to augment generation.
from langchain.retrievers import ParentDocumentRetriever from langchain.storage import InMemoryStore parent_splitter = RecursiveCharacterTextSplitter(chunk_size=1536) child_splitter = RecursiveCharacterTextSplitter(chunk_size=256) vectorstore = Chroma(collection_name="split_parents", embedding_function=hf_bge_embeddings) store = InMemoryStore()
parent_document_retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
parent_document_retriever.add_documents(docs)
Create, test, and evaluate the Parent Document Retriever chain
parent_document_retriever_qa_chain = create_qa_chain(parent_document_retriever, deci_dragon)
parent_document_retriever_qa_chain.invoke({"question" : "What are some metrics to evaluate RAG pipelines?"})["response"]
/usr/local/lib/python3.10/dist-packages/transformers/pipelines/base.py:1101: UserWarning: You seem to be using the pipelines sequentially on GPU. In order to maximize efficiency please use a dataset warnings.warn( 1. Context relevance;\r\n2. Answer faithfulness;\r\n3. Answer relevance.
pdr_qa_ragas_dataset = create_ragas_dataset(parent_document_retriever_qa_chain, eval_dataset)
pdr_qa_result = evaluate_ragas_dataset(pdr_qa_ragas_dataset)
The results from the Parent Document Retriever reveal some interesting insights about its performance, especially when compared to the base retriever.
Let’s analyze these metrics in light of the retriever’s design and functionality:
- Context Precision (0.5650): This score has decreased compared to the base retriever. It suggests that the Parent Document Retriever, while retrieving larger chunks for context, may not be as precise in fetching only the most relevant information.
- Faithfulness (0.6159): The decrease in this score indicates that the answers generated are less consistently faithful to the retrieved context. This could be due to the larger document chunks introducing more varied information, some of which might not be directly relevant to the query.
- Answer Relevancy (0.8457): While still relatively high, this score is lower than the base retriever. It implies that the answers are generally relevant, but the larger context chunks might be introducing slight deviations or less focused responses.
- Context Recall (0.9186): Similar to the base retriever, this score is high, indicating the retriever is effective at retrieving a comprehensive set of information for a given query.
- Context Relevancy (0.0505): Consistent with the base retriever, this low score is a concern. It implies that the larger document chunks retrieved are often not highly relevant to the query, potentially due to the broader scope of information in each chunk.
- Answer Correctness (0.5199): This score has seen a notable decrease. It suggests that the accuracy of the answers may be compromised when using larger document chunks, possibly due to the inclusion of more extraneous information.
- Answer Similarity (0.8711): This metric remains high, indicating that despite the larger context chunks, the answers generated are still similar to the expected responses.
Overall Analysis:
- Comparative Insights: Compared to the base retriever, the Parent Document Retriever shows decreased precision, faithfulness, relevancy, and correctness. However, it maintains high recall and answer similarity.
- Interpreting the Impact: The Parent Document Retriever’s approach of fetching larger document chunks appears to introduce more comprehensive information but potentially at the cost of focused relevancy and accuracy. This could be due to the broader variety of information in each chunk, which might dilute the specific context relevant to a query.
- Potential Adjustments: Tweaking the chunk size or refining the criteria for selecting parent documents could help balance context relevance with the need for comprehensive information.
This analysis suggests that while the Parent Document Retriever is effective in gathering extensive information, its approach might benefit from adjustments to improve the precision and relevance of the context and, consequently, the accuracy of the answers.
plot_metrics_with_values(pdr_qa_result, "Parent Document Retriever ragas Metrics")
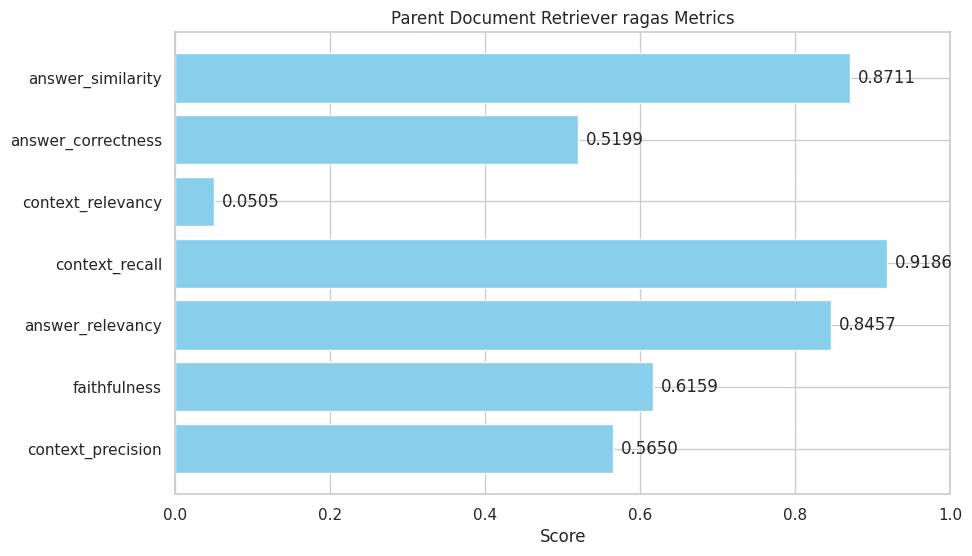
Create, test, and evaluate the Ensemble Retrieval chain
Next, let’s look at ensemble retrieval. You can read more about this here!
The basic idea is as follows:
- Obtain User Question
- Hit the Retriever Pair
- Retrieve Documents with BM25 Sparse Vector Retrieval
- Retrieve Documents with Dense Vector Retrieval Method
- Collect and “fuse” the retrieved docs based on their weighting using the Reciprocal Rank Fusion algorithm into a single ranked list.
- Use those documents to augment our generation.
Ensure your weights list – the relative weighting of each retriever – sums to 1!
from langchain.retrievers import BM25Retriever, EnsembleRetriever
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=16)
docs = text_splitter.split_documents(all_docs)
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 3
vectorstore = Chroma.from_documents(docs, hf_bge_embeddings)
chroma_retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, chroma_retriever], weights=[0.42, 0.58])
ensemble_retriever_qa_chain = create_qa_chain(ensemble_retriever, deci_dragon)
ensemble_retriever_qa_chain.invoke({"question" : "What are some metrics to evaluate RAG pipelines?"})["response"]
/usr/local/lib/python3.10/dist-packages/transformers/pipelines/base.py:1101: UserWarning: You seem to be using the pipelines sequentially on GPU. In order to maximize efficiency please use a dataset warnings.warn( 1. Noise Robustness - how well does the LLM handle noise in the input?\r\n2. Negative Rejection - how well does the LLM reject irrelevant information?\r\n3. Information Integration - how well does the LLM integrate information?\r\n4. Counterfactual Robustness - how well does the LLM handle false information?
ensemble_qa_ragas_dataset = create_ragas_dataset(ensemble_retriever_qa_chain, eval_dataset)
ensemble_qa_result = evaluate_ragas_dataset(ensemble_qa_ragas_dataset)
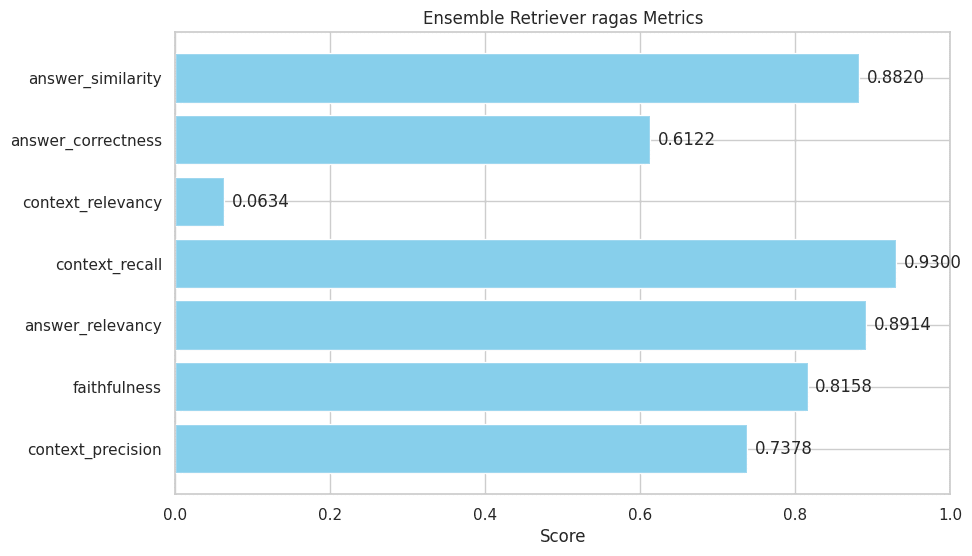
The results from the Ensemble Retriever, which combines multiple retrieval methods, provide a comprehensive view of its effectiveness.
Let’s analyze these metrics in the context of its hybrid search approach:
- Context Precision (0.7378): This score is significantly higher than the Parent Document Retriever and slightly higher than the base retriever. It indicates that the combination of sparse and dense retrievers effectively narrows down the most relevant information, balancing keyword-based and semantic relevance.
- Faithfulness (0.8158): A noticeable improvement compared to both the base and Parent Document Retrievers. This suggests that the answers generated are more consistently faithful to the retrieved context, likely benefiting from the ensemble approach’s comprehensive capture of relevant information.
- Answer Relevancy (0.8914): This score is almost as high as the base retriever, indicating that the answers are highly relevant to the questions. The hybrid approach appears to enhance the ability to address specific queries accurately.
- Context Recall (0.9300): This is the highest score among the three retrievers, implying that the Ensemble Retriever is exceptionally effective at retrieving a comprehensive set of information for each query.
- Context Relevancy (0.0634): Though still low, this score is slightly improved compared to the other retrievers. It indicates that while the context retrieved is more relevant than before, there’s still room for improvement in ensuring only pertinent information is fetched.
- Answer Correctness (0.6122): This score is higher than the Parent Document Retriever but lower than the base. It reflects a moderate level of accuracy in the answers, suggesting that while the hybrid approach captures a broad range of information, it may not always precisely align with the ground truth.
- Answer Similarity (0.8820): The highest among the three, showing that the answers generated are very similar to the expected responses, benefitting from the combined strengths of different retrieval methods.
Overall Analysis:
- Strengths: The Ensemble Retriever excels in context recall and answer similarity, benefiting from the combined strengths of sparse and dense retrievers. Its context precision and faithfulness are also notably improved.
- Areas for Improvement: While context relevancy has seen some improvement, it’s still a weak point. Additionally, answer correctness, though better than the Parent Document Retriever, doesn’t match the base retriever’s performance.
- Implications: The Ensemble Retriever’s hybrid approach shows a balanced performance across metrics. By leveraging both keyword and semantic similarities, it manages to retrieve a comprehensive and relatively more precise set of information.
This analysis indicates that the Ensemble Retriever’s hybrid approach is effective in creating a well-rounded retrieval performance, making it a robust choice for diverse RAG applications.
plot_metrics_with_values(ensemble_qa_result, "Ensemble Retriever ragas Metrics")
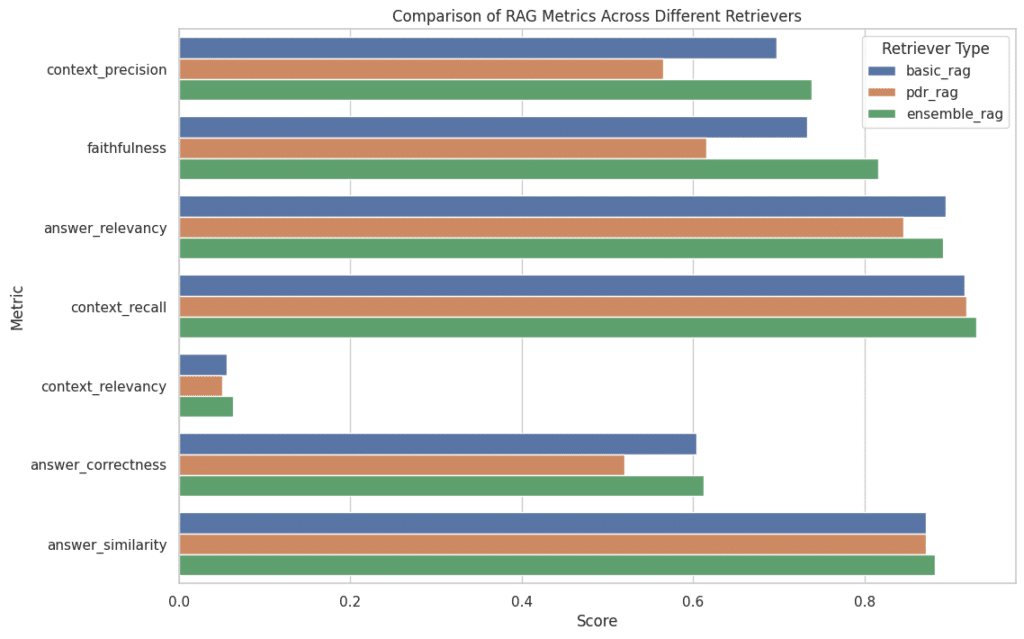
We’ll also look at combining the results and looking at them in a single table so we can make inferences about them.
name context_precision faithfulness answer_relevancy context_recall context_relevancy answer_correctness answer_similarity 2 ensemble_rag 0.737778 0.815833 0.891430 0.929988 0.063360 0.612173 0.882034 0 basic_rag 0.697431 0.732917 0.895029 0.917143 0.056080 0.604233 0.871678 1 pdr_rag 0.565000 0.615889 0.845680 0.918571 0.050528 0.519929 0.871134
plot_rag_metrics(results_df)
Recapping the Key Finding of Our RAG Evaluation
In this blog, we’ve tackled the nuts and bolts of RAG evaluation.
You’ve seen firsthand how different retrievers – basic, Parent Document, and Ensemble – perform under scrutiny. From the detailed analysis of metrics for the basic, Parent Document, and Ensemble retrievers, we’ve seen how each approach brings its unique strengths and challenges to the table. The Ensemble Retriever, with its hybrid approach, stands out for its balanced performance across multiple metrics, highlighting the value of combining different retrieval strategies.
Let’s recap the key findings:
- The basic retriever excels in answer relevancy and faithfulness, but it stumbles a bit in context precision.
- The Parent Document Retriever, designed for larger context chunks, showed a dip in most metrics, notably in answer correctness and faithfulness.
- The Ensemble Retriever emerged as a robust contender, striking a balance across all metrics, particularly shining in context recall and answer similarity.
Your takeaway?
No one-size-fits-all in RAG evaluation. Each retriever has its trade-offs. The Ensemble Retriever’s hybrid approach seems to offer a more balanced performance, but your choice depends on what aspect of performance is most critical to your needs.
As we conclude this exploration, I extend my gratitude to AI Makerspace and the LLMOps cohort (discover more) for their invaluable teachings. A special thanks to Chris Alexiuk (connect with him) for his collaboration and guidance in enriching this journey.
Their contributions have been instrumental in deepening our understanding of RAG evaluation.
Discover Deci’s LLMs and GenAI Development Platform
In addition to DeciLM-7B, Deci offers a suite of fine-tunable high performance LLMs, available through our GenAI Development Platform. Designed to balance quality, speed, and cost-effectiveness, our models are complemented by flexible deployment options. Customers can access them through our platform’s API or opt for deployment on their own infrastructure, whether through a Virtual Private Cloud (VPC) or directly within their data centers.
If you’re interested in exploring our LLMs firsthand, we encourage you to sign up for a free trial of our API.
For those curious about our VPC and on-premises deployment options, we encourage you to book a 1:1 session with our experts.