Introduction
Large Language Models (LLMs) are powerful tools for generating human-like text, but they have limitations. Retrieval Augmented Generation (RAG) addresses these challenges, enhancing LLMs by integrating retrieval mechanisms. This approach ensures that the content LLMs produce is both contextually relevant and factually accurate. RAG acts as a bridge, connecting LLMs to vast knowledge sources. As AI becomes increasingly used for diverse tasks, the accuracy and relevance of the generated information are crucial.
RAG meets this demand, making AI interactions more informative and context-aware.
What You Need for RAG Implementation
Before building out a RAG system, it’s essential to familiarize yourself with the tools that make this process possible.
Each tool plays a specific role, ensuring that the RAG system operates efficiently and effectively.
LLM: At the heart of the system is the LLM, the core AI model responsible for generating human-like text responses.
Vector Store: This is where the magic happens. The Vector Store is a dedicated storage system that houses embeddings and their corresponding textual data, ensuring quick and efficient retrieval.
Vector Store Retriever: Think of this as the search engine of the system. The Vector Store Retriever fetches relevant documents by comparing vector similarities, ensuring that the most pertinent information is always at hand.
Embedder: Before storing or retrieving data, we need to convert textual information into a format the system can understand. The Embedder takes on this role, transforming text into vector representations.
Prompt: Every interaction starts with a user’s query or statement. The Prompt captures this initial input, setting the stage for the retrieval and generation processes.
Document Loader: With vast amounts of data to process, the Document Loader is essential. It imports and reads documents, preparing them for chunking and embedding.
Document Chunker: To make the data more manageable and efficient for retrieval, the Document Chunker breaks documents into smaller, more digestible pieces.
User Input: Last but not least, the User Input tool captures the query or statement provided by the end-user, initiating the entire RAG process.
The RAG System and Its Subsystems
The primary goal of RAG is to provide LLMs with contextually relevant and factually accurate information, ensuring that the generated content meets the highest standards of quality and relevance.
To achieve this, the RAG system is divided into subsystems, each playing a crucial role in the overall process. The tools integral to the RAG system are not standalone entities; they interweave to form the subsystems that drive the RAG process.
Each tool fits within one of the following subsystems:
1) Index
2) Retrieval
3) Augment
These work together as an orchestrated flow that transforms a user’s query into a contextually rich and accurate response.
Index System
Purpose: This subsystem is responsible for preparing and organizing the data for efficient retrieval.
Here are the steps of the Index system
1) Load Documents (Document Loader): Imports and reads the vast amounts of data that the system will use.
2) Chunk Documents (Document Chunker): Breaks down the loaded documents into smaller, more manageable pieces to facilitate efficient retrieval.
3) Embed Documents (Embedder): Converts these textual chunks into vector representations, making them searchable within the system.
4) Store Embeddings (Vector Store): Safely stores the generated embeddings alongside their textual counterparts for future retrieval.
Load Documents
from langchain.document_loaders import WebBaseLoader
yolo_nas_loader = WebBaseLoader("https://deci.ai/blog/yolo-nas-object-detection-foundation-model/").load()
decicoder_loader = WebBaseLoader("https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/#:~:text=DeciCoder's%20unmatched%20throughput%20and%20low,re%20obsessed%20with%20AI%20efficiency.").load()
yolo_newsletter_loader = WebBaseLoader("https://deeplearningdaily.substack.com/p/unleashing-the-power-of-yolo-nas").load()
Chunk documents
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 50,
length_function = len
)
yolo_nas_chunks = text_splitter.transform_documents(yolo_nas_loader)
decicoder_chunks = text_splitter.transform_documents(decicoder_loader)
yolo_newsletter_chunks = text_splitter.transform_documents(yolo_newsletter_loader)
Create an index
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings import CacheBackedEmbeddings
from langchain.vectorstores import FAISS
from langchain.storage import LocalFileStore
store = LocalFileStore("./cachce/")
# create an embedder
core_embeddings_model = OpenAIEmbeddings()
embedder = CacheBackedEmbeddings.from_bytes_store(
core_embeddings_model,
store,
namespace = core_embeddings_model.model
)
# store embeddings in vector store
vectorstore = FAISS.from_documents(yolo_nas_chunks, embedder)
vectorstore.add_documents(decicoder_chunks)
vectorstore.add_documents(yolo_newsletter_chunks)
# instantiate a retriever
retriever = vectorstore.as_retriever()
Retrieval System
Purpose: As the name suggests, this subsystem fetches the most relevant information based on the user’s query.
Here are the steps in the Retrieval system
1) Obtain User Query (User Input): Captures the user’s question or statement.
2) Embed User Query (Embedder): Transforms the user’s query into a vector format, similar to the indexed documents.
3) Vector Search (Vector Store Retriever): Searches the Vector Store for documents with embeddings that closely match the embedded user query.
4) Return Relevant Documents: The system then returns the top matches, ensuring that the most pertinent information is always provided.
from langchain.llms.openai import OpenAIChat from langchain.chains import RetrievalQA from langchain.callbacks import StdOutCallbackHandler
llm = OpenAIChat() handler = StdOutCallbackHandler()
/usr/local/lib/python3.10/dist-packages/langchain/llms/openai.py:787: UserWarning: You are trying to use a chat model. This way of initializing it is no longer supported. Instead, please use: `from langchain.chat_models import ChatOpenAI` warnings.warn(
# this is the entire retrieval system
qa_with_sources_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
callbacks=[handler],
return_source_documents=True
)
Augment System
Purpose: This subsystem enhances the LLM’s input prompt with the retrieved context, ensuring that the model has all the necessary information to generate a comprehensive response.
1) Create Initial Prompt (Prompt): Starts with the original user query or statement.
2) Augment Prompt with Retrieved Context: Merges the initial prompt with the context retrieved from the Vector Store, creating an enriched input for the LLM.
3) Send Augmented Prompt to LLM: The enhanced prompt is then fed to the LLM.
4) Receive LLM’s Response: After processing the augmented prompt, the LLM generates and returns its response.
# This is the entire augment system!
response = qa_with_sources_chain({"query":"What does Neural Architecture Search have to do with how Deci creates its models?"})
> Entering new RetrievalQA chain... > Finished chain.
Look at the entire response:
{'query': 'What does Neural Architecture Search have to do with how Deci creates its models?',
'result': 'Deci utilizes Neural Architecture Search (NAS) technology, specifically their proprietary AutoNAC technology, to automatically generate and optimize the architecture of their models. Neural Architecture Search helps Deci in efficiently constructing deep learning models for various tasks and hardware.',
'source_documents': [Document(page_content='Neural Architecture Search is define the architecture search space. For YOLO-NAS, our researchers took inspiration from the basic blocks of YOLOv6 and YOLOv8. With the architecture and training regime in place, our researchers harnessed the power of AutoNAC. It intelligently searched a vast space of ~10^14 possible architectures, ultimately zeroing in on three final networks that promised outstanding results. The result is a family of architectures with a novel quantization-friendly basic', metadata={'source': 'https://deeplearningdaily.substack.com/p/unleashing-the-power-of-yolo-nas', 'title': 'Unleashing the Power of YOLO-NAS: A New Era in Object Detection and Computer Vision', 'description': 'The Future of Computer Vision is Here', 'language': 'en'}),
Document(page_content='Deci’s suite of Large Language Models and text-to-Image models, with DeciCoder leading the charge, is spearheading the movement to address this gap.DeciCoder’s efficiency is evident when compared to other top-tier models. Owing to its innovative architecture, DeciCoder surpasses models like SantaCoder in both accuracy and speed. The innovative elements of DeciCoder’s architecture were generated using Deci’s proprietary Neural Architecture Search technology, AutoNAC™.\xa0\nAnother Win for AutoNAC', metadata={'source': "https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/#:~:text=DeciCoder's%20unmatched%20throughput%20and%20low,re%20obsessed%20with%20AI%20efficiency.", 'title': 'Introducing DeciCoder: The New Gold Standard in Efficient and Accurate Code Generation', 'description': 'Today, we introduce DeciCoder, our 1B-parameter open-source Large Language Model for code generation, equipped with a 2048-context window.', 'language': 'en-US'}),
Document(page_content='The quest for the “optimal” neural network architecture has historically been a labor-intensive manual exploration. While this manual approach often yields results, it is highly time consuming and often falls short in pinpointing the most efficient neural networks. The AI community recognized the promise of Neural Architecture Search (NAS) as a potential game-changer, automating the development of superior neural networks. However, the computational demands of traditional NAS methods limited', metadata={'source': "https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/#:~:text=DeciCoder's%20unmatched%20throughput%20and%20low,re%20obsessed%20with%20AI%20efficiency.", 'title': 'Introducing DeciCoder: The New Gold Standard in Efficient and Accurate Code Generation', 'description': 'Today, we introduce DeciCoder, our 1B-parameter open-source Large Language Model for code generation, equipped with a 2048-context window.', 'language': 'en-US'}),
Document(page_content='This new model is fast and accurate, offering the best accuracy-latency tradeoff among existing object detection models on the market. This accomplishment was made possible by Deci’s AutoNAC neural architecture search technology, which efficiently constructs deep learning models for any task and hardware.', metadata={'source': 'https://deci.ai/blog/yolo-nas-object-detection-foundation-model/', 'title': 'YOLO-NAS by Deci Achieves State-of-the-Art Performance on Object Detection Using Neural Architecture Search', 'description': 'The new YOLO-NAS architecture sets a new frontier for object detection tasks, offering the best accuracy and latency tradeoff performance.', 'language': 'en-US'})]}
If you want just the response:
print(response['result'])
Deci utilizes Neural Architecture Search (NAS) technology, specifically their proprietary AutoNAC technology, to automatically generate and optimize the architecture of their models. Neural Architecture Search helps Deci in efficiently constructing deep learning models for various tasks and hardware.
And you can get the source like so:
print(response['source_documents'])
[Document(page_content='Neural Architecture Search is define the architecture search space. For YOLO-NAS, our researchers took inspiration from the basic blocks of YOLOv6 and YOLOv8. With the architecture and training regime in place, our researchers harnessed the power of AutoNAC. It intelligently searched a vast space of ~10^14 possible architectures, ultimately zeroing in on three final networks that promised outstanding results. The result is a family of architectures with a novel quantization-friendly basic', metadata={'source': 'https://deeplearningdaily.substack.com/p/unleashing-the-power-of-yolo-nas', 'title': 'Unleashing the Power of YOLO-NAS: A New Era in Object Detection and Computer Vision', 'description': 'The Future of Computer Vision is Here', 'language': 'en'}), Document(page_content='Deci’s suite of Large Language Models and text-to-Image models, with DeciCoder leading the charge, is spearheading the movement to address this gap.DeciCoder’s efficiency is evident when compared to other top-tier models. Owing to its innovative architecture, DeciCoder surpasses models like SantaCoder in both accuracy and speed. The innovative elements of DeciCoder’s architecture were generated using Deci’s proprietary Neural Architecture Search technology, AutoNAC™.\xa0\nAnother Win for AutoNAC', metadata={'source': "https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/#:~:text=DeciCoder's%20unmatched%20throughput%20and%20low,re%20obsessed%20with%20AI%20efficiency.", 'title': 'Introducing DeciCoder: The New Gold Standard in Efficient and Accurate Code Generation', 'description': 'Today, we introduce DeciCoder, our 1B-parameter open-source Large Language Model for code generation, equipped with a 2048-context window.', 'language': 'en-US'}), Document(page_content='The quest for the “optimal” neural network architecture has historically been a labor-intensive manual exploration. While this manual approach often yields results, it is highly time consuming and often falls short in pinpointing the most efficient neural networks. The AI community recognized the promise of Neural Architecture Search (NAS) as a potential game-changer, automating the development of superior neural networks. However, the computational demands of traditional NAS methods limited', metadata={'source': "https://deci.ai/blog/decicoder-efficient-and-accurate-code-generation-llm/#:~:text=DeciCoder's%20unmatched%20throughput%20and%20low,re%20obsessed%20with%20AI%20efficiency.", 'title': 'Introducing DeciCoder: The New Gold Standard in Efficient and Accurate Code Generation', 'description': 'Today, we introduce DeciCoder, our 1B-parameter open-source Large Language Model for code generation, equipped with a 2048-context window.', 'language': 'en-US'}), Document(page_content='This new model is fast and accurate, offering the best accuracy-latency tradeoff among existing object detection models on the market. This accomplishment was made possible by Deci’s AutoNAC neural architecture search technology, which efficiently constructs deep learning models for any task and hardware.', metadata={'source': 'https://deci.ai/blog/yolo-nas-object-detection-foundation-model/', 'title': 'YOLO-NAS by Deci Achieves State-of-the-Art Performance on Object Detection Using Neural Architecture Search', 'description': 'The new YOLO-NAS architecture sets a new frontier for object detection tasks, offering the best accuracy and latency tradeoff performance.', 'language': 'en-US'})]
response = qa_with_sources_chain({"query":"What is DeciCoder"})
> Entering new RetrievalQA chain... > Finished chain.
print(response['result'])
DeciCoder is a 1B-parameter open-source Large Language Model (LLM) for code generation. It has a 2048-context window, permissively licensed, delivers a 3.5x increase in throughput, improved accuracy on the HumanEval benchmark, and smaller memory usage compared to widely-used code generation LLMs such as SantaCoder.
response = qa_with_sources_chain({"query":"Write a blog about Deci and how it used NAS to generate YOLO-NAS and DeciCoder"})
> Entering new RetrievalQA chain... > Finished chain.
print(response['result'])
Deci, a company focused on pushing the boundaries of accuracy and efficiency, has introduced a new architecture called YOLO-NAS. YOLO-NAS is a benchmark for object detection that has the potential to drive innovation and unlock new possibilities across various industries and research domains. Deci has showcased its robust capabilities with the DeciCoder model, which consistently outperforms models like SantaCoder. By leveraging AutoNAC, Deci was able to generate an architecture that is both efficient and powerful. Deci's use of NAS (Neural Architecture Search) played a pivotal role in the development of YOLO-NAS. NAS is a technique that automates the design process of neural networks, allowing for the discovery of optimized architectures. By deploying NAS, Deci was able to achieve state-of-the-art performance on object detection with YOLO-NAS. The integration of NAS in the development of YOLO-NAS and DeciCoder showcases Deci's commitment to pushing the boundaries of AI innovation. With the YOLO-NAS architecture and DeciCoder, Deci aims to provide advanced solutions for various use cases, such as running on edge devices, optimizing generative AI models, reducing cloud costs, shortening development time, and maximizing data center utilization. Deci's focus on accuracy, efficiency, and innovation through the use of NAS sets them apart in the industry. Their dedication to driving progress in object detection and AI research makes them a valuable player in the field.
For a hands-on experience and a deeper understanding of the concepts discussed, I invite you to explore our interactive Google Colab notebook. This resource offers a practical and engaging way to apply and visualize the techniques in real-time.
Next Step: Streamlining Deployment
After successfully creating a RAG system, you’re now ready for the deployment phase. At this juncture, you’ll encounter the practical challenges of latency, throughput, and cost in LLMs.
The complex computations required by LLMs can result in high latency, adversely affecting the user experience, particularly in real-time applications. Additionally, a crucial challenge is managing low throughput, which leads to slower response times and difficulties in processing multiple user requests simultaneously. This often requires more expensive, high-performance hardware to enhance throughput, increasing operational costs. Therefore, the need to invest in such hardware adds to the inherent computational expenses of deploying these models.
Infery-LLM by Deci presents an effective solution to these problems. This Inference SDK boosts LLM performance, offering up to five times higher throughput while maintaining accuracy. Significantly, it optimizes computational resource use, allowing for the deployment of larger models on cost-effective GPUs, which lowers operational costs.
When combined with Deci’s open-source models, such as DeciCoder or DeciLM-7B, the efficiency of Infery-LLM is notably increased. These highly accurate and efficient models integrate smoothly with the SDK, boosting its effectiveness in reducing latency and cutting down costs.
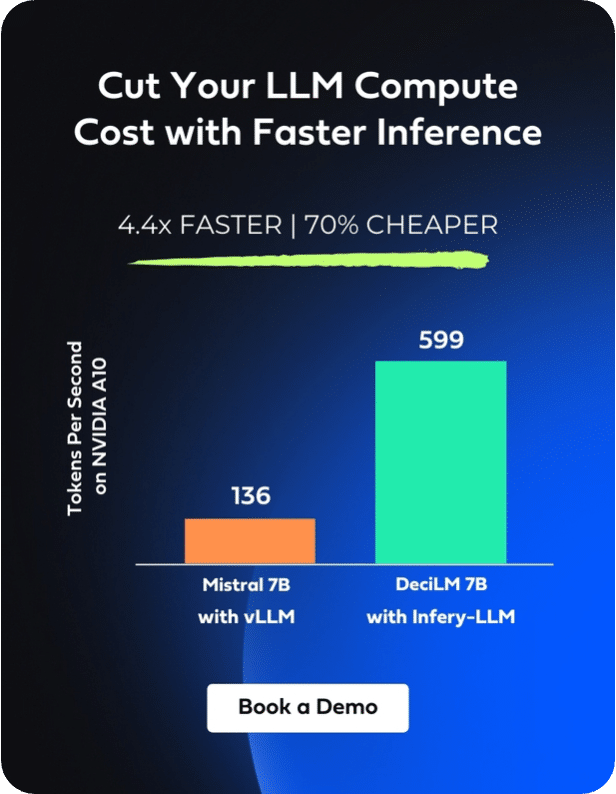
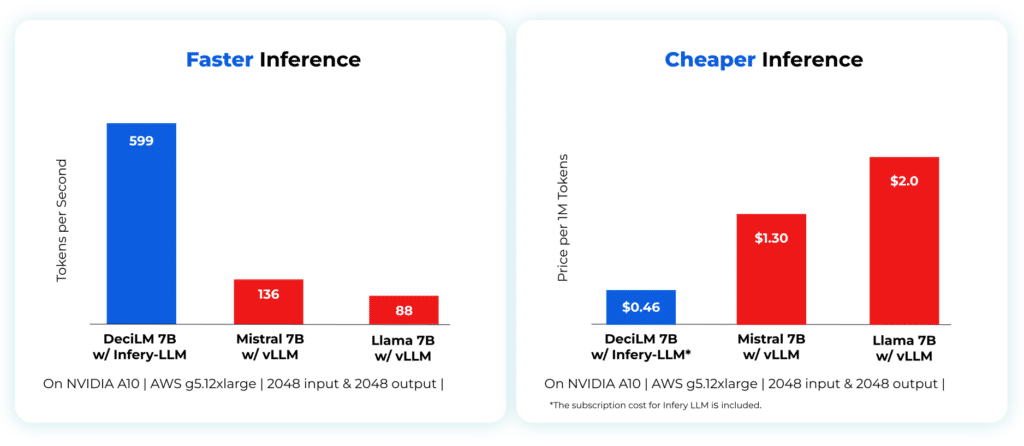
Enabling inference with just three lines of code, Infery-LLM makes it easy to deploy into production and into any environment. Its optimizations unlock the true potential of LLMs, as exemplified when it runs DeciLM-7B, achieving 4.4x the speed of Mistral 7B with vLLM with a 64% reduction in inference costs.

Infery’s approach to optimizing LLMs enables significant performance improvements on less powerful hardware, as compared to other approaches on vLLM or PyTorch even on high-end GPUs, significantly reducing the overall cost of ownership and operation. This shift not only makes LLMs more accessible to a broader range of users but also opens up new possibilities for applications with resource constraints.
In conclusion, Infery-LLM is essential for overcoming the challenges of latency, throughput, and cost in deploying LLMs, becoming an invaluable asset for developers and organizations utilizing these advanced models.
To experience the full capabilities of Infery-LLM, we invite you to get started today.