

The YOLO models are famous for two main reasons: their impressive speed and accuracy and their ability to detect objects in images quickly and dependably.
In this article, I share my insights gained from reading a comprehensive 30-page paper that delves into the advancements of YOLO models.
This review provides a thorough overview of the YOLO framework’s evolution, covering all 15 models from the original YOLOv1 to the most recent YOLOv8.

Setting the stage: What you need to know about object detection tasks
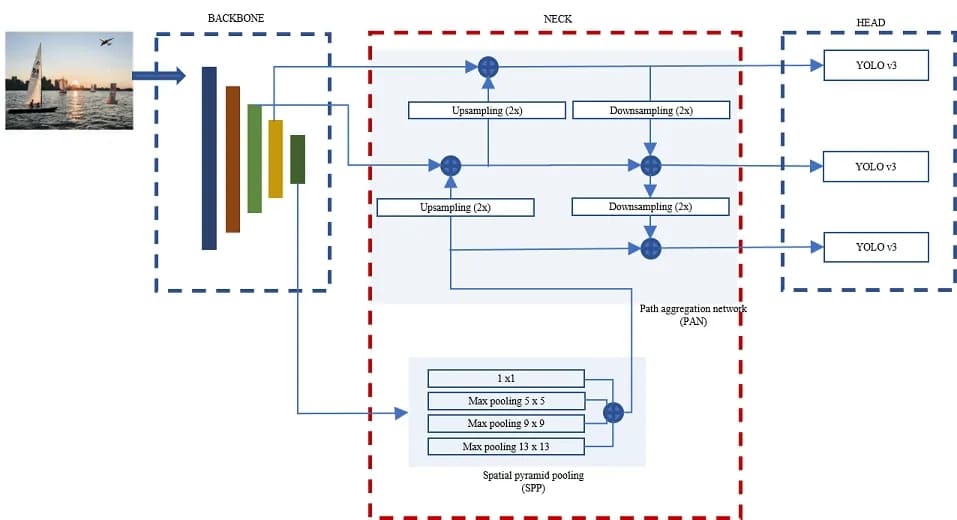
The anatomy of an object detection model: backbone, neck, and head
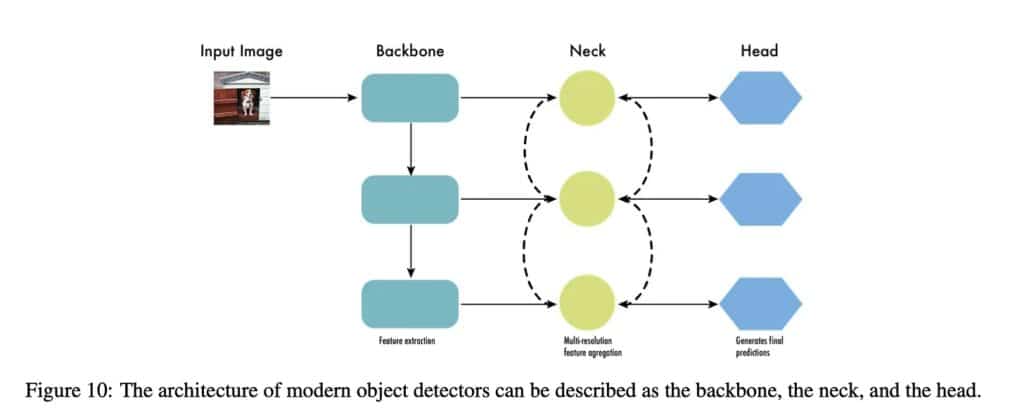
The architecture of object detectors is divided into three parts: the backbone, the neck, and the head.
The backbone is crucial in extracting valuable features from input images, typically using a convolutional neural network (CNN) trained on large-scale image classification tasks like ImageNet. The backbone captures hierarchical features at varying scales. Lower-level features (edges and textures) are extracted in the previous layers, and higher-level features (like object parts and semantic information) are removed in the deeper layers.
The neck is an intermediate component connecting the backbone to the head.
Measuring the performance of object detection models: metrics and non-maximum suppression (NMS)
The mean Average Precision (mAP) is the metric for evaluating object detection models. It measures the average precision across all categories, providing a single value to compare different models.
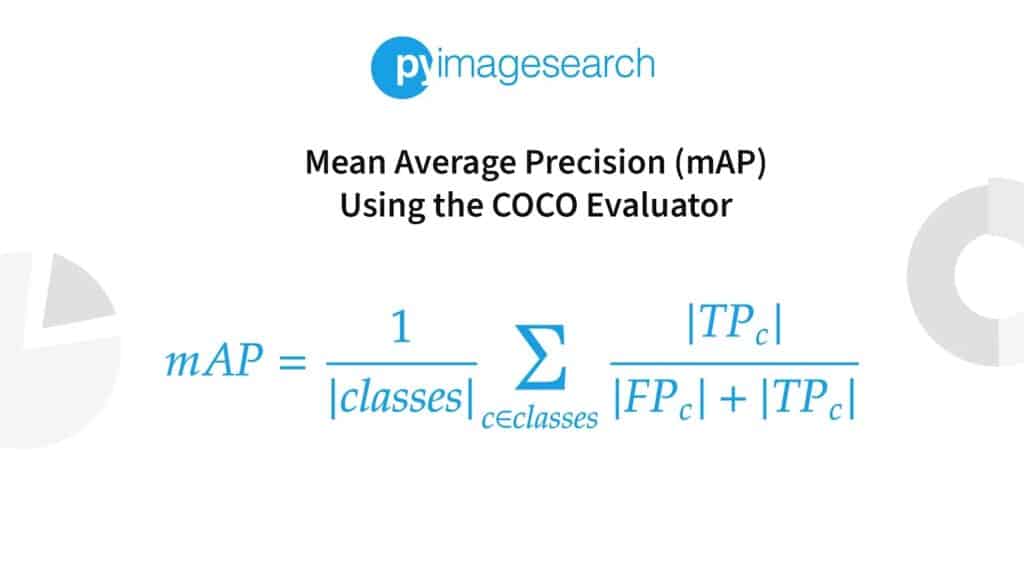
mAP metric is based on precision-recall metrics, handling multiple object categories, and defining a positive prediction using Intersection over Union (IoU).
Precision and recall are essential metrics for evaluating model accuracy. mAP offers a balanced assessment, while IoU measures bounding box quality. Non-Maximum Suppression helps filter out redundant bounding boxes for improved detection quality.
When evaluating the accuracy of a model, two metrics must be considered: precision and recall.
Precision measures the model’s ability to make accurate positive predictions, while recall measures the proportion of actual positive cases that the model correctly identifies. Think of precision as a sharpshooter who hits the target accurately and recall as a detective who catches all the suspects in a crime. There is a tradeoff between precision and recall because detecting more objects can produce more false positives.
The mean Average Precision (mAP) metric calculates the area under the precision-recall curve to provide a more balanced assessment.
The mAP metric incorporates the precision-recall curve that plots precision against recall for different confidence thresholds. It provides a balanced assessment of precision and recall by considering the area under the precision-recall curve. mAP handles multiple object categories by calculating each category’s average precision separately and taking their average across all types (hence the name mAP).
The Intersection over Union (IoU) metric measures the quality of predicted bounding boxes by comparing the intersection and union areas of the predicted and ground truth bounding boxes.
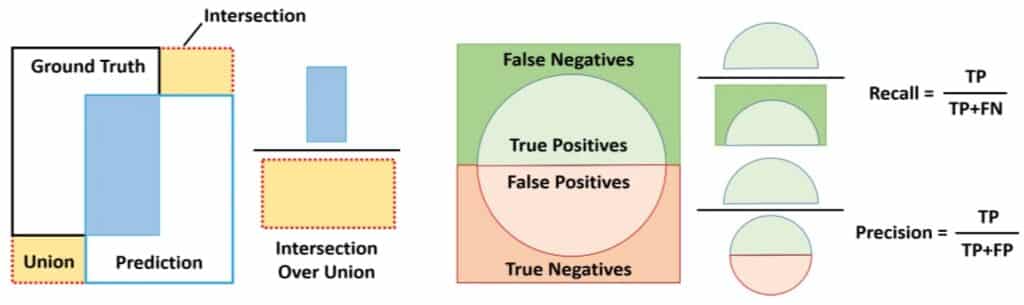
IoU is the ratio of the intersection area to the union area of the predicted bounding box and the ground truth bounding box. It measures the overlap between the ground truth and predicted bounding boxes. The IoU is calculated by dividing the intersection of the two boxes by the union of the boxes.
By using both the mAP and IoU metrics, a more comprehensive evaluation of a model’s accuracy can be achieved. This is essential in ensuring the model is effective in its intended use case.
Object detection algorithms typically generate multiple bounding boxes around the same object with different confidence scores.
Non-Maximum Suppression filters out redundant and irrelevant bounding boxes, keeping only the most accurate ones. This reduces the number of overlapping bounding boxes and improves the overall detection quality.

Here’s how the NMS algorithm works:
- Start with a set of predicted boxes (“B”) and their confidence scores (“S”).
- Set the IoU (“tau”) and a confidence threshold (“T”).
- Task: find a set of filtered boxes (“F”).
- Start the algorithm:
- Keep the predicted boxes in “B” where confidence scores > threshold “T.” Redefine “B” as this filtered set of boxes.
- Sort the boxes in “B” by descending confidence scores.
- Instantiate an empty “F” set for the final boxes.
- While there are still boxes left in “B,” do the following:
- Pick the box with the highest confidence score (“b”) from “B.”
- Add box “b” to the set “F”
- Remove “b” from the set “B”
- For each remaining box in “B” (call them “r”), do the following:
- Calculate the IoU between “b” and “r.”
- If IoU > “tau,” then “r” overlaps too much with “b.” So, remove “r” from the set “B.”
- Continue until no boxes are left in “B.”
- You’re done! The set “F” now has the best boxes you picked.
YOLO: You Only Look Once

The beginning of the YOLO saga takes us back to a scorching Monday afternoon in June 2016 at the CVPR Conference held at the Caesar’s Palace Conference Center in Las Vegas, Nevada.
Joseph Redmon took the stage and presented his paper You Only Look Once: Unified, Real-Time Object Detection. This paper introduced a groundbreaking end-to-end approach to object detection that allowed for real-time processing. This was a significant development for the computer vision community.
Unlike previous methods, YOLO is an efficient object detection architecture requiring only one network pass. It eliminates the need for multiple runs or a two-step process. This model achieved an astonishing mAP of 63.4 on the PASCAL VOC2007 dataset.
How does YOLO work?
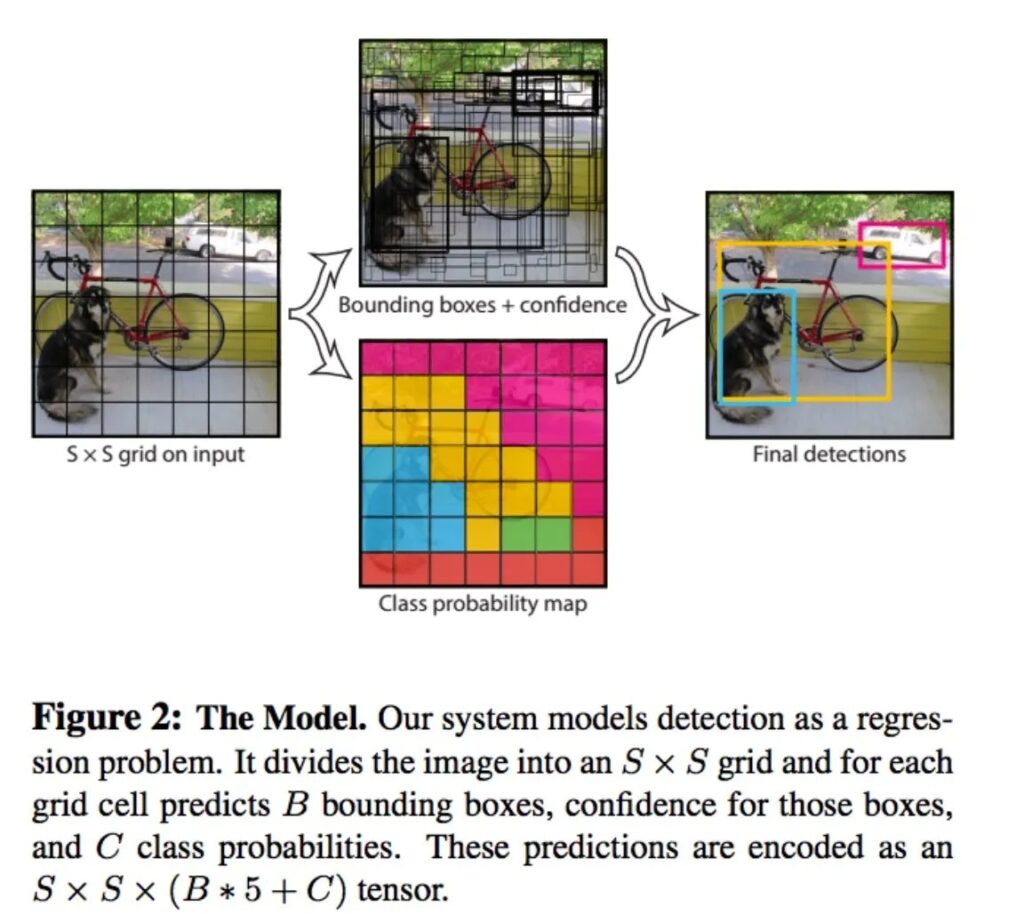
The YOLO object detection method detects all the bounding boxes at once by dividing the input image into a grid and predicting B bounding boxes with confidence scores for C classes per grid element.
Each bounding box prediction includes Pc, which reflects the confidence and accuracy of the model. The box and by coordinates are the centers of the box relative to the grid cell, and bh and bw are the height and width of the box relative to the full image.
The output is a tensor of SxSx(Bx 5 + C), which can be followed by non-maximum suppression to remove duplicate detections.
YOLO Strengths and Limitations
Although YOLO is a fast object detector, it has some limitations. YOLO has a more significant localization error than state-of-the-art methods like Fast R-CNN. This limitation can be attributed to three major causes:
- YOLO can only detect a maximum of two objects of the same class in the grid cell, which limits its ability to predict nearby things.
- YOLO has difficulty predicting objects with aspect ratios that were not present in the training data.
- YOLO learns from coarse object features due to the down-sampling process.
YOLOv2: Better, Faster, and Stronger

On a sultry Tuesday afternoon in July 2017, Redmon stepped onto the stage again.
During the presentation, Redmon shared a paper titled YOLO9000: Better, Faster, Stronger and introduced an object detection system capable of identifying over 9000 categories. This model, called YOLOv2, exhibited an impressive average precision (AP) of 78.6% on the PASCAL VOC2007 dataset, outperforming its predecessor, YOLOv1, which achieved only 63.4%. These findings highlight the advanced capabilities of YOLOv2 in object detection and recognition, paving the way for future progress in computer vision.
The system has been improved in several ways.
These improvements include using batch normalization for convolutional layers to improve convergence and reduce overfitting. A high-resolution classifier was added, resulting in better performance for higher-resolution inputs. The architecture was changed to fully convolutional layers – including a backbone called DarkNet, which contained 19 convolutional layers and 5 max-pooling layers – and anchor boxes are now used to predict bounding boxes.

Finally, dimension clusters were implemented to make predictions more accurate using suitable priors found through k-means clustering.
The authors introduced a method for training joint classification and detection in the same paper.
During training, they combined both datasets such that when a detection training image is used, it backpropagates the detection network. When a classification training image is used, it backpropagates the classification part of the architecture.
The result is a YOLO model capable of detecting more than 9000 categories hence the name YOLO9000.
YOLOv3

On April 8th, 2018, Joseph Redmon and Ali Farhadi published a paper on arXiv called YOLOv3: An Incremental Improvement.
When YOLOv3 was released, the benchmark for object detection had changed from PASCAL VOC to Microsoft COCO. From here on, all the YOLOs are evaluated in the MS COCO dataset. The YOLOv3-spp variant introduced in the paper achieved mAP of 60.6% at 20 FPS, achieving state-of-the-art at the time and 2x faster. As it turns out, this becomes the final YOLO version led by Joseph Redmon.
This paper included significant changes and an enormous architecture to be on par with the state-of-the-art while keeping real-time performance. YOLOv3 uses logistic regression to assign objectness scores to anchor boxes. It trains binary classifiers for giving multiple labels to the same box. The authors use k-means to determine bounding box priors with three prior boxes for three sizes.
YOLOv4
Joseph Redmon left computer vision research because he was concerned about military applications and privacy violations.
And so, the world waited with bated breath for two years until a new version of YOLO. It was in April 2020 that Alexey Bochkovskiy and others picked up where Redmon left off and released a paper on arXiv called YOLOv4: Optimal Speed and Accuracy of Object Detection.
YOLOv4 kept the same YOLO philosophy —real-time, open source, single shot, and DarkNet framework— and the improvements were so satisfactory that the community rapidly embraced this version as the official YOLOv4.
YOLOv4 tried to find the optimal balance by experimenting with many changes categorized as bag-of-freebies and bag-of-specials.
Bag-of-freebies are methods that only change the training strategy and increase training cost but do not increase the inference time, the most common being data augmentation. On the other hand, bag-of-specials are methods that slightly increase the inference cost but significantly improves accuracy.
Examples of these methods are those for enlarging the receptive field, combining features, and post-processing, among others.
New image adjustments include mosaic augmentation, which merges four images for more accurate object detection without requiring a larger mini-batch size. For regularization, they used DropBlock, which replaces Dropout but for convolutional neural networks and class label smoothing.
YOLOv5

In June 2020, just two months after the launch of YOLOv4, Glenn Jocher from Ultralytics released YOLOv5.
There was some controversy about the name, but we won’t delve into that here. YOLOv5 builds upon many of the improvements made in YOLOv4, but the main difference is that it was developed using PyTorch instead of DarkNet.
Ultralytics actively maintains YOLOv5 as an open-source project with over 250 contributors and frequent improvements. It is user-friendly for training, deployment, and implementation. In testing the MS COCO dataset test-dev 2017, YOLOv5x achieved an impressive AP of 50.7% with an image size of 640 pixels. With a batch size of 32, it can attain a speed of 200 FPS on an NVIDIA V100.
By using a larger input size of 1536 pixels, YOLOv5 can achieve an even higher AP of 55.8%.
Scaled-YOLOv4
In CVPR 2021, the authors of YOLOv4 introduced Scaled-YOLOv4, which was created using Pytorch instead of DarkNet.
The main innovation of Scaled-YOLOv4 was the implementation of scaling-up and scaling-down techniques. Scaling up results in a more accurate model with lower speed, while scaling down produces a faster model with reduced accuracy.
The scaled-down architecture was called YOLOv4-tiny; it was designed for low-end GPUs and can run at 46 FPS on a Jetson TX2 or 440 FPS on RTX2080Ti, achieving 22% mAP on MS COCO. The scaled-up model architecture was called YOLOv4-large, which included three different sizes P5, P6, and P7. This architecture was designed for cloud GPU and achieved state-of-the-art performance, surpassing all previous models with 56% mAP on MS COCO.
YOLOR
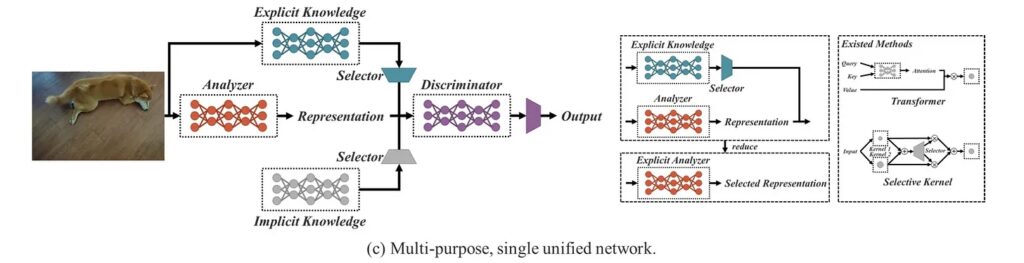
You Only Learn One Representation: Unified Network for Multiple Tasks (YOLOR) was published in ArXiv in May 2021 by the same research team of YOLOv4.
The approach taken by the authors was different. They created a multi-task learning approach to develop a single model for various tasks, such as classification, detection, and pose estimation. They achieved this by learning a general representation and using sub-networks to generate task-specific representations.
YOLOR was developed to encode the implicit knowledge of neural networks to be applied to multiple tasks, much like how humans use past experiences to approach new problems.
YOLOR was evaluated on the MS COCO dataset test-dev 2017 and achieved an mAP of 55.4% and mAP50 of 73.3% at 30 FPS on an NVIDIA V100.
YOLOX
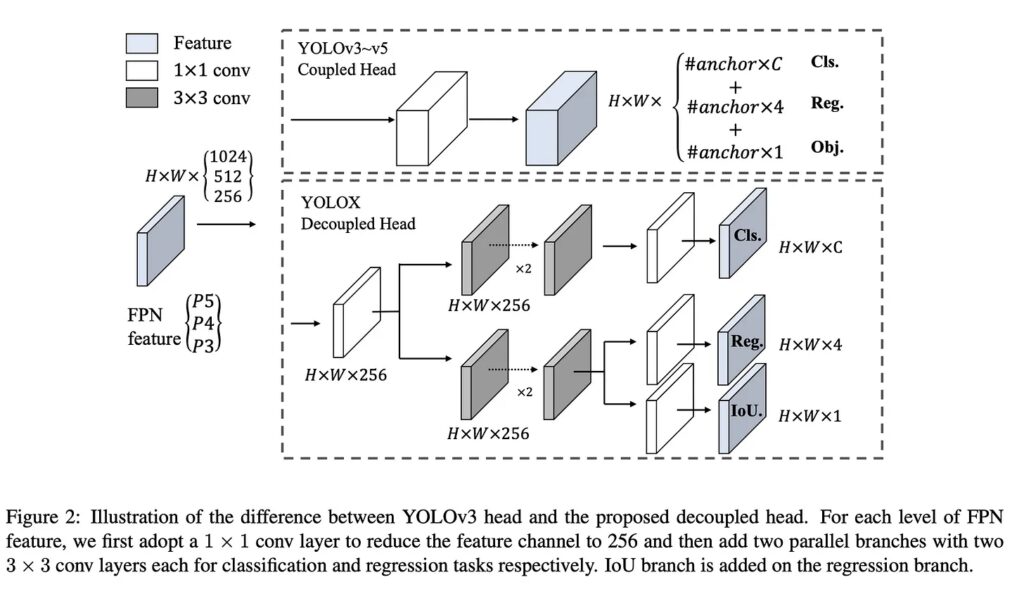
YOLOX: Exceeding YOLO Series in 2021 was published in ArXiv in July 2021 by a research team from Megvii Technology Developed in Pytorch, using YOLOv3 from Ultralytics as a starting point.
YOLOX made several changes to its predecessor, YOLOv3.
One significant change is that it is anchor-free, simplifying training and decoding. To compensate for the lack of anchors, YOLOX uses center sampling, where the center 3×3 area is assigned as positive. It also separates classification and regression tasks into two heads to avoid misalignments.
Additionally, YOLOX employs MixUP and Mosaic augmentations, which were found to be more beneficial than ImageNet pretraining.
YOLOX balances speed and accuracy with 50.1% mAP on MS COCO.
YOLOv6
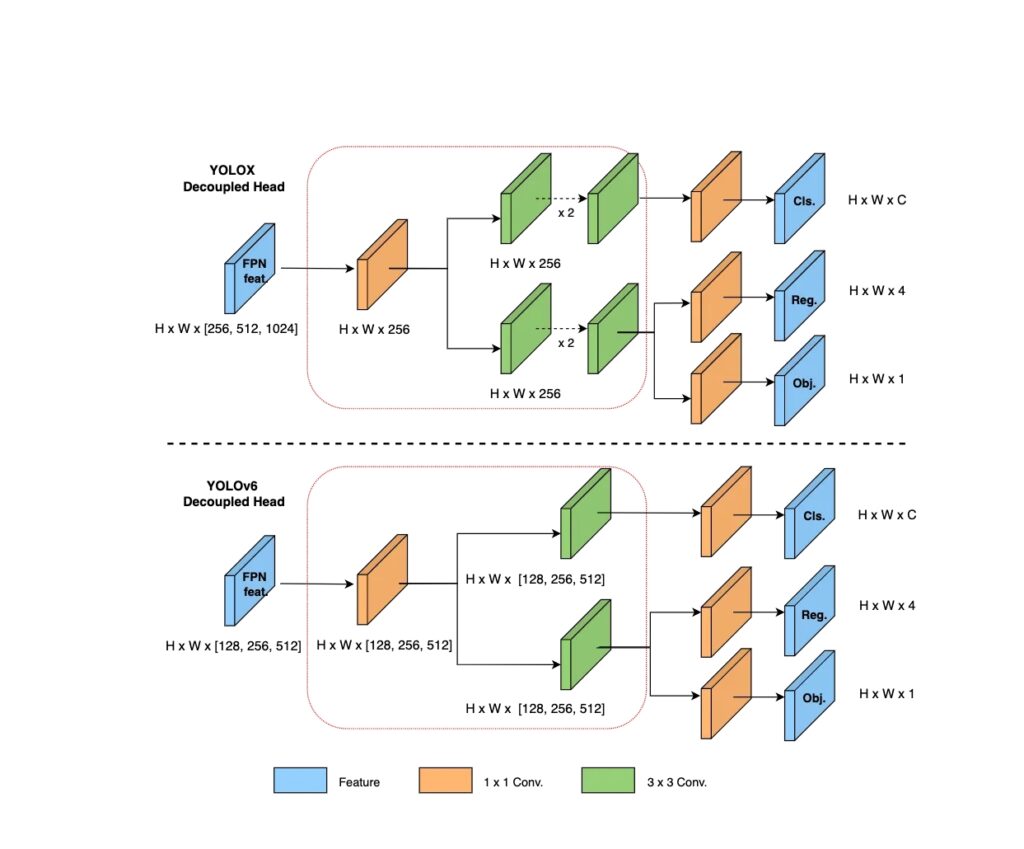
YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications was published in ArXiv in September 2022 by Meituan Vision AI Department.
Similar to YOLOv4 and YOLOv5, it provides various models of different sizes for industrial applications.
Following the trend of the anchor point-based methods, YOLOv6 adopted an anchor-free detector.
YOLOv6-L achieved an AP of 52.5% and AP50 of 70% at around 50 FPS on an NVIDIA Tesla T4.
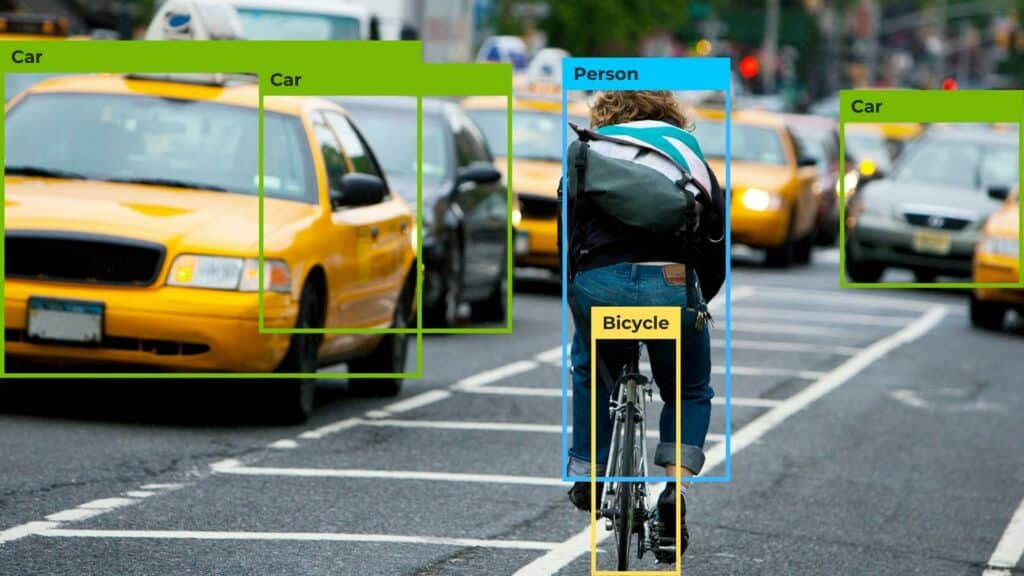
If you’re looking for a detailed comparison between YOLOv5, YOLOv6, and YOLOX, the Deci Algo team has written a helpful blog post that breaks it down in technical terms. Read the blog.
YOLOv7
In July 2022, the same authors of YOLOv4 and YOLOR published YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors in ArXiv.
This object detector surpassed all others in speed and accuracy for objects ranging from 5 FPS to 160 FPS. Like YOLOv4, YOLOv7 was trained solely on the MS COCO dataset without using pre-trained backbones.
The YOLOv7 architecture boasts three main features: E-ELAN for efficient learning, model scaling for varying sizes, and the “bag-of-freebies” approach for accuracy and efficiency. E-ELAN controls gradient paths for deep models while model scaling adjusts attributes for hardware usage.
The “bag-of-freebies” approach includes re-parametrization, which improves the model’s performance.
The latest YOLOv7 model outperformed YOLOv4 by achieving a 75% reduction in parameters and a 36% reduction in computation while improving the average precision by 1.5%. YOLOv7-tiny also reduced parameters and computation by 39% and 49%, respectively, without compromising the mAP.
Compared to YOLOR, YOLOv7 significantly reduced the number of parameters and computation by 43% and 15%, respectively, with a slight 0.4% increase in AP.
YOLOv7-E6 has a fast processing speed of 50 FPS on an NVIDIA V100 and achieved an AP of 55.9% and AP50 of 73.5% on the MS COCO dataset test-dev 2017 with an input size of 1280 pixels.
DAMO-YOLO
In November of 2022, Alibaba Group released a paper titled DAMO-YOLO : A Report on Real-Time Object Detection Design on ArXiv.
The paper outlines several techniques to improve object detection accuracy in real-time video processing. These techniques include a neural architecture search using Alibaba’s MAE-NAS method, a unique channel design called Efficient-RepGFPN inspired by GiraffeDet, and an approach called ZeroHead that utilizes both a large and small neck for improved performance. Additionally, the authors introduced the AlignedOTA label assignment method, which addresses misalignment between classification and regression losses, and uses the IoU of prediction and ground truth box as a soft label.
Finally, knowledge distillation was employed to improve accuracy even further.
YOLOv8
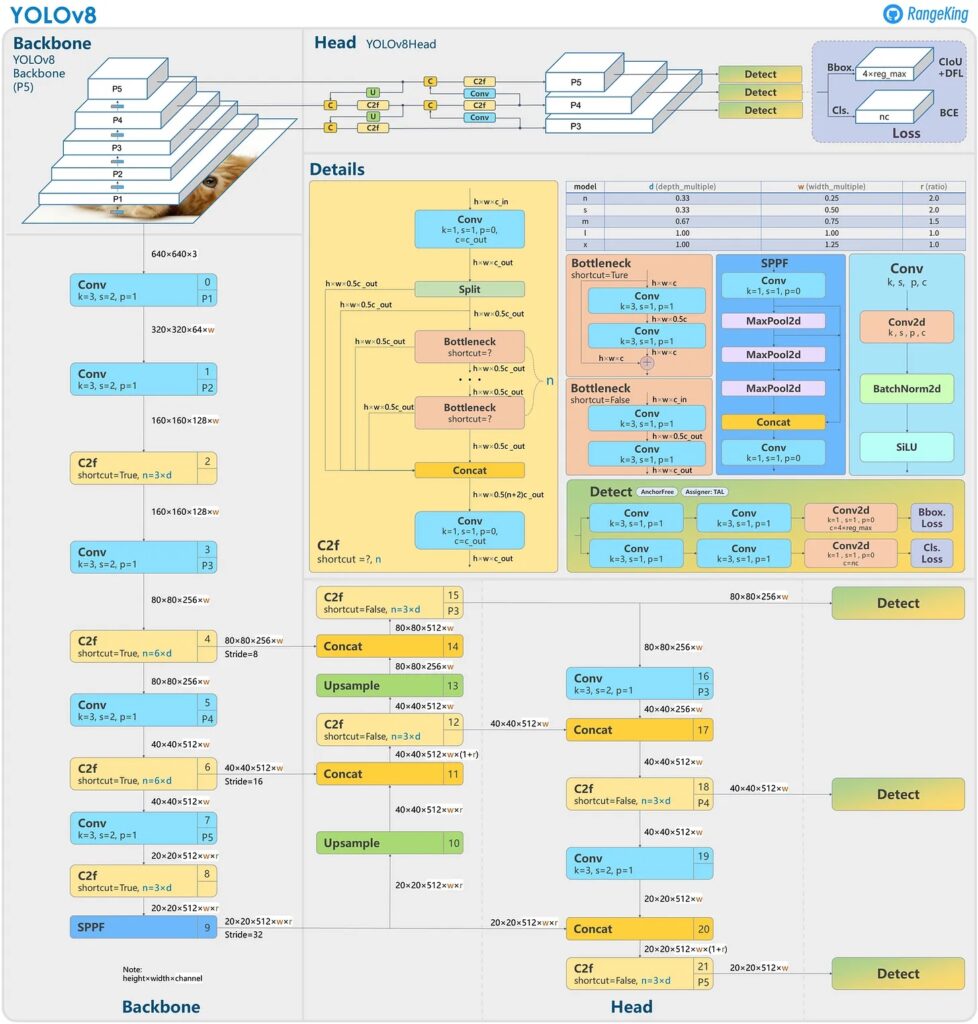
Ultralytics, the company behind YOLOv5, released YOLOv8 in January 2023.
Currently, there is no paper discussing the architecture of YOLOv8, so we must rely on insights to compare it to previous versions of YOLO. YOLOv8 is anchor-free, predicting fewer boxes and has a faster Non-maximum Suppression (NMS) process. During training, YOLOv8 uses mosaic augmentation, but this technique is disabled for the last ten epochs since it can be harmful if used throughout the entire training process.
YOLOv8 offers five different scaled versions: YOLOv8n (nano), YOLOv8s (small), YOLOv8m (medium), YOLOv8l (large), and YOLOv8x (extra-large). When tested on the MS COCO dataset test-dev 2017, YOLOv8x achieved an impressive AP of 53.9% with an image size of 640 pixels, compared to YOLOv5’s 50.7% on the same input size. Additionally, it has a fast speed.
The PaddlePaddle series
PP-YOLO
The PaddlePaddle (PP) series alongside YOLO models, including PP-YOLO, PP-YOLOv2, and PP-YOLOE. These models have contributed significantly to YOLO’s evolution. Baidu Inc. researchers published PP-YOLO: An Effective and Efficient Implementation of Object Detector, based on YOLOv3, in ArXiv in July 2020.
PP-YOLO leverages the PaddlePaddle deep learning platform and adds ten new tricks to boost accuracy without sacrificing speed. It employs different techniques than YOLOv4, and any overlapping methods use distinct implementations. The critical modifications in PP-YOLO compared to YOLOv3 include a new backbone architecture, larger batch size, DropBlock application, IoU loss and prediction branches, grid-sensitive approach, Matrix NMS, CoordConv, and Spatial Pyramid Pooling.
PP-YOLO uses Mixup Training, Random Color Distortion, Random Expand, Random Crop and Flip, RGB channel z-score normalization, and multiple image sizes for augmentations and preprocessing. When evaluated on the MS COCO dataset test-dev 2017, PP-YOLO achieved impressive results with an AP of 45.9%, AP50 of 65.2%, and 73 FPS on an NVIDIA V100.
PP-YOLO is a YOLOv3-based model developed by Baidu Inc. researchers, utilizing the PaddlePaddle deep learning platform. It introduces ten new tricks to enhance accuracy while maintaining speed and has shown notable results when tested on the MS COCO dataset.
PP-YOLOv2
PP-YOLOv2: A Practical Object Detector was published in ArXiv on April 2021 and added four refinements to PP-YOLO that increased performance from 45.9% AP to 49.5% AP at 69 FPS on NVIDIA V100
The PP-YOLOv2 has undergone some changes from its predecessor, PP-YOLO.
First, the backbone has been upgraded from ResNet50 to ResNet101. Second, Path Aggregation Network (PAN) has replaced FPN, similar to YOLOv4. Third, the Mish Activation Function has been implemented in the detection neck, whereas YOLOv4 and YOLOv5 use it throughout. Fourth, the input size increased to 768, and the batch size per GPU was reduced to 12 images, resulting in better performance on smaller objects.
Lastly, the IoU-aware branch has been modified, and the IoU-aware loss calculation now uses a soft label format instead of a soft weight format.
PP-YOLOE
PP-YOLOE: An evolved version of YOLO, published in March 2022, builds on PP-YOLOv2 with an impressive 51.4% AP and 78.1 FPS on NVIDIA V100.
It boasts an anchor-free architecture, a trend at the time thanks to multiple influential works.
The researchers also implemented a new backbone and neck, drawing inspiration from TreeNet. They utilized RepResBlocks that merge residual and dense connections for a more effective design. Task Alignment Learning (TAL) is another critical feature, addressing the task misalignment problem first highlighted by YOLOX.
In addition to TAL, PP-YOLOE sports an Efficient Task-aligned Head (ET-head), a single head based on TOOD that enhances speed and accuracy. To top it all off, Varifocal (VFL) and Distribution focal loss (DFL) prioritize high-quality samples and ensure consistency between training and inference.
PP-YOLOE is an advanced object detection model with an anchor-free architecture, innovative backbone and neck, TAL, ET-head, and VFL and DFL for training consistency and prioritizing high-quality samples.

The SuperGradients model zoo includes YOLOX (nano, tiny, small, medium, and large) and PP-YOLOE(small, medium, large, and x-large).
Critical patterns in YOLO’s evolution include the use and abandonment of anchors, the switch from Darknet to PyTorch and PaddlePaddle frameworks, changes in backbone architectures, and a focus on balancing speed and accuracy for real-time object detection.
Anchors played a significant role in YOLO’s development, with YOLOv2 incorporating them to improve bounding box prediction accuracy. However, the anchor-less approach of YOLOX achieved state-of-the-art results, leading to the abandonment of anchors in subsequent YOLO versions.
As for the framework, YOLO initially relied on the Darknet framework but switched to PyTorch after Ultralytics ported YOLOv3, resulting in a wave of enhancements. PaddlePaddle, an open-source framework by Baidu, is another deep learning language used in YOLO development.
Regarding backbone architectures, YOLO models have experienced significant changes. They began with the Darknet architecture, moved to cross-stage partial connections in YOLOv4, reparameterization in YOLOv6 and YOLOv7, and finally, neural architecture search in DAMO-YOLO.
Lastly, YOLO models prioritize balancing speed and accuracy rather than focusing solely on accuracy. This tradeoff is crucial for real-time object detection across various applications.
The YOLO family balances speed and accuracy, focusing on real-time performance without sacrificing detection quality.
This tradeoff is fine-tuned across YOLO versions by offering different model scales to suit various applications and hardware needs.
The YOLO family consistently prioritizes balancing speed and accuracy to deliver real-time performance without compromising detection quality. This tradeoff recurs throughout YOLO’s evolution, with each version optimizing these objectives differently.
The original YOLO model emphasized high-speed object detection.
Later YOLO versions, such as YOLOv2, incorporated anchor boxes and passthrough layers to enhance object localization and increase accuracy while preserving real-time capabilities. YOLOv3 improved performance using a multi-scale feature extraction architecture for better object detection across different scales.
As the YOLO framework advanced, the tradeoff between speed and accuracy became more refined. Models like YOLOv4 and YOLOv5 introduced new network backbones, enhanced data augmentation techniques, and optimized training strategies.
Official YOLO models fine-tune the balance between speed and accuracy by offering various model scales to accommodate specific applications and hardware requirements. For example, these versions often include lightweight models optimized for edge devices, sacrificing accuracy for reduced computational complexity and faster processing times.
The Future of YOLO
The future of YOLO depends on more demanding benchmarks, a proliferation of models and applications, expansion into new domains, and adaptability to diverse hardware platforms.
Benchmark Evolution
As object detection models become more advanced and accurate, the current COCO 2017 benchmark may be replaced by a more challenging benchmark. This follows the transition from the VOC 2007 benchmark used in the first two YOLO versions, illustrating the need for increasingly demanding benchmarks.
We see that happen with the Roboflow 100 (RF100) benchmark, a crowdsourced, open source object detection benchmark. It comprises 100 datasets, 7 imagery domains, 224,714 images, and 829 class labels with over 11,170 labelling hours.
The Proliferation of YOLO Models and Applications
We can expect a growing number of YOLO models released each year, accompanied by a broader range of applications. As the framework becomes more versatile and powerful, it will likely be utilized in diverse domains, from home appliances to autonomous vehicles.
Expansion into New Domains
YOLO models could extend their capabilities beyond object detection and segmentation, exploring areas such as object tracking in videos and 3D keypoint estimation.
Adaptability to Diverse Hardware
YOLO models will likely cover various hardware platforms, from IoT devices to high-performance computing clusters. This adaptability will enable deploying YOLO models in multiple contexts, depending on the application’s requirements and constraints. Furthermore, by customizing the models to suit different hardware specifications, YOLO can become more accessible and practical for users and industries.
That’s it!
If you’ve made it this far: thank you!
There’s a tonne of technical detail in the paper I referenced before. If you’re looking for more information and math, then be sure to check it out.








