
In computer vision, object detection, and segmentation are crucial tasks that enable machines to understand and interact with visual data. The ability to accurately identify and isolate objects in an image has numerous practical applications, from autonomous vehicles to medical imaging.
Image segmentation produces masks or contours for each detected object in an image, along with the class labels and bounding boxes around the detected objects. It is useful when you need to know the location and the precise shape of objects in an image.
The Segment Anything Model (SAM) is an image segmentation model that enables promptable segmentation. It can generate valid segmentation masks from any prompt, such as spatial or text clues identifying an object. This ability allows SAM to adapt to a wide variety of downstream segmentation problems using prompt engineering, making it a versatile and potent tool for image analysis tasks. SAM is trained on the SA-1B dataset, which contains over 1 billion masks spread over 11 million carefully curated images. SAM displays an impressive zero-shot performance and thus surpasses previously fully supervised results in many cases.
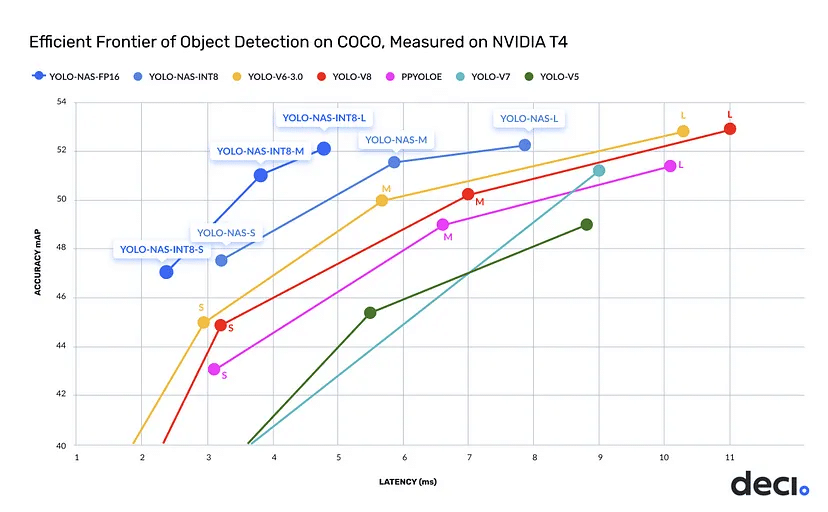
YOLO-NAS is the latest state-of-the-art object detection model released by Deci AI. The model was generated by AutoNAC, Deci’s Neural Architecture Search engine. YOLO-NAS surpasses other object detection models in terms of speed and accuracy. In building YOLO-NAS, Deci sought to high-quality some key limiting factors of current YOLO models, such as inadequate quantization support and insufficient accuracy-latency tradeoff.
YOLO-NAS enhances the ability to detect small objects, improves localization accuracy, and increases the performance-per-compute ratio, which makes the model well-suited for real-time edge device applications.
In this easy-to-follow guide, we will discover how to implement image and video segmentation with YOLO-NAS and Segment Anything Model (SAM).
Tools
For this project, we use Google Colab, which offers a 15GB Graphics Card. Let’s explore the software tool we will use to implement Image and Video Segmentation with YOLO-NAS and Segment Anything Model (SAM) in Python.
(i) SuperGradients
The YOLO-NAS model is available under an open-source license with pre-trained weights available for non-commercial use on SuperGradients, Deci’s PyTorch-based, open-source,
computer vision training library.
(ii) Segment Anything Model
The Segment Anything Model (SAM) produces high-quality object masks from input prompts such as points or boxes, and it can be used to generate masks for all objects in an image.
Step-by-Step Guide
Let us go through the step-by-step guide on image and video segmentation with YOLO-NAS and Segment Anything Model (SAM).
You can find the accompanying code for this guide in this Google Colab Notebook file.
Step 1- Install All the Required Packages
First, install three packages, including SuperGradients, Segment Anything Model, and Supervision packages.
!pip install -q super_gradients==3.1.3 !pip install -q segment_anything !pip install -q supervision
After running the script above, you are ready to use the installed Supergradients, SAM, and supervision packages. Before proceeding, make sure to restart the runtime.
Step 2 – Import All the Required Libraries
After installing all the required packages, we will import all the required libraries, including OpenCV, supervision, Matplotlib, SuperGradients, and Segment Anything. We require the OpenCV-python package to read or display an input or output image or to do image processing. To read an input video frame by frame or display or save the output video OpenCV-python package. To display an input image, use the Matplotlib package. We will import YOLO-NAS from the SuperGrandients training library, which gives us access to the model’s pre-trained weights. We will import a mask generator to generate masks on the detected objects in an image from segment anything.
import cv2 import torch import math import numpy as np from numpy import random import supervision as sv import matplotlib.pyplot as plt from google.colab.patches import cv2_imshow from super_gradients.training import models from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
Step 3 – Download the Pretrained YOLO-NAS Model Weights
Since we have installed all the required packages and imported all the required libraries, we will download the pre-trained YOLO-NAS small model weights. YOLO-NAS comes in three different sizes, YOLO-NAS-S, YOLO-NAS-M, and YOLO-NAS-L (small, medium, large). YOLO-NAS-S is the fastest but it is less accurate compared to the other YOLO-NAS models. YOLO-NAS-L is the most accurate among YOLO-NAS models but it is not as fast as the other YOLO-NAS models. We will use the small version of the model, YOLO-NAS-S, and the pre-trained weights from the COCO dataset.
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
model = models.get('yolo_nas_s', pretrained_weights="coco").to(device)
Step 4 – Object Detection with YOLO-NAS on Image
We have downloaded the YOLO-NAS-S model and the pre-trained weights from the COCO dataset. Next, we will perform object detection on an image.
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
model = models.get('yolo_nas_s', pretrained_weights= "coco").to(device)
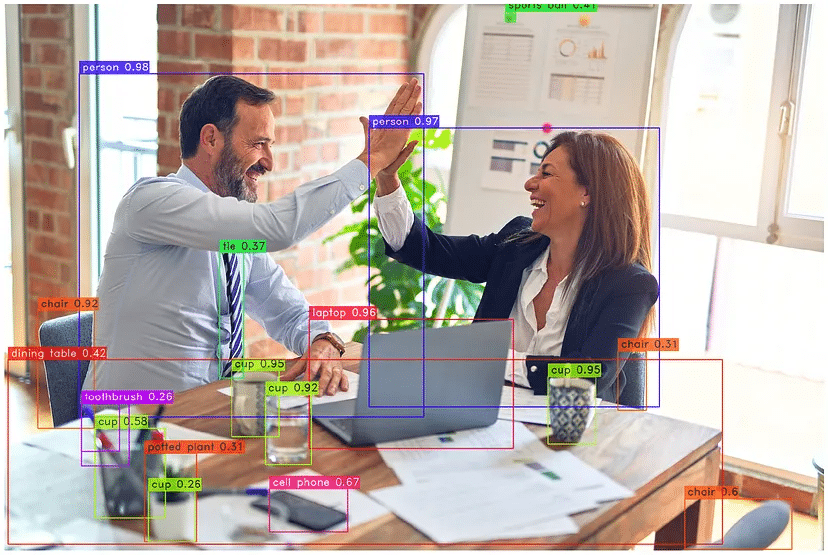
model.predict("https://deci-pretrained-models.s3.amazonaws.com/sample_images/beatles-abbeyroad.jpg").show()
Here is our output image:
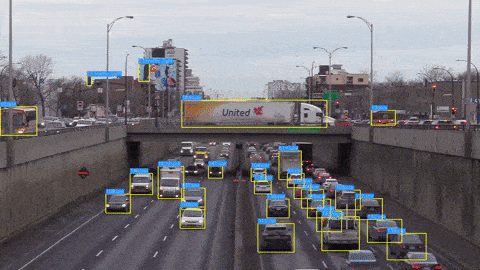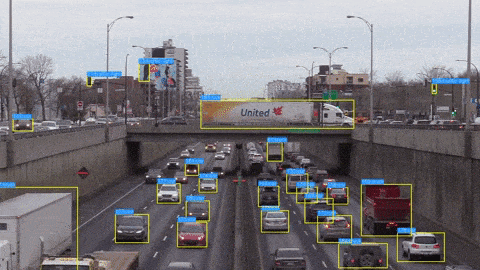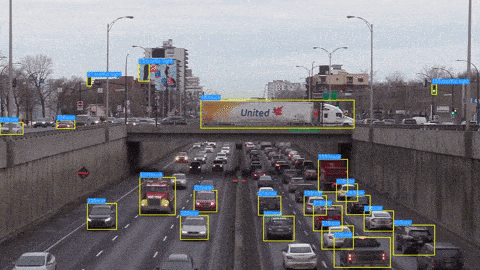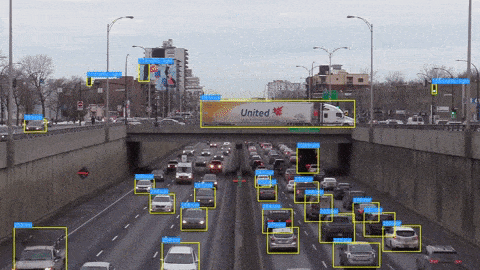
Step 4 – Object Detection with YOLO-NAS on Video
After doing object detection with YOLO-NAS on an image, we will see how we can do object detection with YOLO-NAS on a video. We will loop through each of the frames one by one and do the detection of the objects in each of the frames. Using the OpenCV write function, we will also save the output video as well.
out = cv2.VideoWriter('Output1.avi', cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), 10, (frame_width, frame_height))
count = 0
while True:
ret, frame = cap.read()
count += 1
if ret:
result = list(model.predict(frame, conf=0.35))[0]
bbox_xyxys = result.prediction.bboxes_xyxy.tolist()
confidences = result.prediction.confidence
labels = result.prediction.labels.tolist()
for (bbox_xyxy, confidence, cls) in zip(bbox_xyxys, confidences, labels):
bbox = np.array(bbox_xyxy)
x1, y1, x2, y2 = bbox[0], bbox[1], bbox[2], bbox[3]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
classname = int(cls)
class_name = names[classname]
conf = math.ceil((confidence*100))/100
label = f'{class_name}{conf}'
t_size = cv2.getTextSize(label, 0, fontScale = 1, thickness=2)[0]
c2 = x1 + t_size[0], y1 - t_size[1] -3
cv2.rectangle(frame, (x1, y1), c2, [255, 144, 30], -1, cv2.LINE_AA)
cv2.putText(frame, label, (x1, y1-2), 0, 1, [255, 255, 255], thickness=1, lineType = cv2.LINE_AA)
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 255), 3)
resize_frame = cv2.resize(frame, (0, 0), fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
out.write(frame)
else:
break
out.release()
cap.release()
Here is the output video:
Step 5 – Image Segmentation using YOLO-NAS and Segment Anything Model (SAM)
So far, we’ve seen how to do object detection on images and videos with YOLO-NAS. Now, we will discuss how we can do Image and Video Segmentation with YOLO-NAS and SAM. First, we will download the checkpoint for SAM.
!wget 'https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth'
Step 6 – Create SAM Mask Generator and Segmented Mask Function
To do image and video segmentation with YOLO-NAS and SAM we will create some necessary functions. First, we will load the Segment Anything Model (SAM) checkpoint and return the Segment Anything Model.
def load_sam():
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
return sam
Next, we will initialize the SAM automatic mask generator parameters. Parameters can be modified for more optimized performance.
def mask_generator():
mask_generator_ = SamAutomaticMaskGenerator(
model=load_sam(),
points_per_side=32,
pred_iou_thresh=0.9,
stability_score_thresh=0.96,
crop_n_layers=1,
crop_n_points_downscale_factor=2,
min_mask_region_area=100,
)
return mask_generator_
To draw the masks on the detected objects, will create a function.
def draw_segmented_mask(anns, frame):
img = frame.copy()
mask_annotator = sv.MaskAnnotator(color=sv.Color.blue())
detections = sv.Detections(
xyxy=sv.mask_to_xyxy(masks=anns),
mask=anns)
detections = detections[detections.area == np.max(detections.area)]
segmented_mask = mask_annotator.annotate(scene=frame, detections=detections)
return segmented_mask
Step 7 – Image Segmentation with YOLO-NAS and SAM
We have created the mask generator and segmented mask functions and can now do image segmentation with YOLO-NAS and Segment Anything Model (SAM). The code snippet is provided below. In the first step, we will do object detection on an image with YOLO-NAS. In the next step, we will create a mask around each of the detected objects with SAM.
frame = cv2.imread("/content/image1.jpg")
result = list(model.predict(frame, conf=0.5))[0]
bbox_xyxys = result.prediction.bboxes_xyxy.tolist()
confidences = result.prediction.confidence
labels = result.prediction.labels.tolist()
label = [int(labels) for labels in labels]
print("Bounding Box Coordinates",bbox_xyxys)
print("Scores", confidences)
print("Class IDS", label)
masks = segment_object(bbox_xyxys, frame, label, filter_classes=None)
for mask in masks:
segmented_mask = show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
rearranged_mask = np.transpose(segmented_mask[:,:,:3], (2,0,1))
frame = draw_segmented_mask(rearranged_mask, frame)
plt.close()
cv2_imshow(frame)
cv2.imwrite("example1.jpg", frame)
Our output images looks as follows:

Step 8 – Video Segmentation with YOLO-NAS and SAM
Now, let’s turn to segmentation on videos with YOLO-NAS and SAM. We will first upload a video. Next, we will loop through each of the frames one by one and do the detection of the objects in each of the frames. After detecting the objects in the frame, we will create a mask around each of the detected objects in the frame using the Segment Anything Model (SAM).
The code snippet is provided below.
out = cv2.VideoWriter('Output2.avi', cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), 10, (frame_width, frame_height))
count = 0
while True:
ret, frame = cap.read()
count += 1
if ret:
result = list(model.predict(frame, conf=0.5))[0]
bbox_xyxys = result.prediction.bboxes_xyxy.tolist()
confidences = result.prediction.confidence
labels = result.prediction.labels.tolist()
label = [int(labels) for labels in labels]
print("Bounding Box Coordinates",bbox_xyxys)
print("Scores", confidences)
print("Class IDS", label)
masks = segment_object(bbox_xyxys, frame, label, filter_classes=None)
for mask in masks:
segmented_mask = show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
rearranged_mask = np.transpose(segmented_mask[:,:,:3], (2,0,1))
frame = draw_segmented_mask(rearranged_mask, frame)
out.write(frame)
plt.close()
else:
break
out.release()
cap.release()
Here is the output video:

The output shows that we have successfully performed video segmentation with YOLO-NAS and SAM. By following the steps detailed in this blog post, you will be able to do image and video segmentation with YOLO-NAS and SAM.
Next Steps
Now that we have implemented image and video segmentation with YOLO-NAS and SAM, there are many exciting steps we can take to bring this project forward.
- Build a frontend chat interface with Streamlit, where a user can upload an image or video and do the segmentation using YOLO-NAS and SAM.
- Dockerize and deploy the application on a cloud instance
- Experiment with other YOLO-NAS and SAM models to objectively evaluate the differences in inference speed and output.
YOLO-NAS and Deci’s Computer Vision Suite
In this blog, we’ve explored the use of YOLO-NAS and SAM for video segmentation. As we conclude, it’s noteworthy that YOLO-NAS itself is a prime example of the advanced foundation models developed by Deci AI using our innovative AutoNAC engine. Each model, including YOLO-NAS, is designed for a specific computer vision task, hardware configuration, and data characteristics. This ensures exceptional accuracy, efficient memory utilization, and remarkably low latency. For those needing custom solutions, AutoNAC can be used to develop models specific to unique requirements.
Upon choosing a foundation or custom model, you can train or fine-tune it using your own data via Deci’s SuperGradients PyTorch training library. This resource offers superior training recipes with advanced techniques to enhance model quality and provide clearer visual insights. To further boost your model’s efficiency and inference speed, Deci’s Infery SDK is an invaluable tool.
Discover more about Deci’s foundation models and the Infery SDK, and see how they can transform your AI initiatives, by booking a demo with us.









