Today, we’re excited to introduce the game-changing Infery-LLM – an Inference SDK by Deci.
With Infery-LLM, you can supercharge the performance of your LLMs, boosting speed by up to 5x while maintaining the same accuracy.
At its core, Infery-LLM is engineered to supercharge performance, encompassing a wide array of advanced inference optimization techniques. Beyond performance, it champions simplicity and efficiency, allowing you to execute inference in just three lines of code, tailored to your preferred deployment configuration. Furthermore, Infery-LLM doesn’t confine you to a single setup; it grants full control and flexibility, empowering you to operate in the environment you’re most comfortable with. This blend of power, simplicity, and adaptability makes Infery-LLM a prime choice for those looking to accelerate LLMs and reduce their inference compute costs.
Unprecedented inference efficiency emerges when combining Deci’s open-source models such as DeciCoder or DeciLM 6B and Infery-LLM. Furthermore, Infery-LLM allows you to run larger models on more widely available and cost-effective GPUs by supporting different parallelism paradigms.
Under the hood of Infery LLM
Infery-LLM achieves faster inference through a combination of advanced engineering techniques and optimizations developed by Deci’s expert team:
Optimized CUDA Kernels:
Infery’s custom kernels optimized for grouped query attention and the operations that follow it, thus speeding up the prefill and decoding stages of generation.
Our custom kernels can be tuned for various decoder architectures (different quantization, attention headcount, etc.)
Advanced Selective Quantization:
Quantization allows for the compression of model parameters and reduces the memory footprint and memory IO required for inference. This enables efficient deployment on cost-effective instances. However, some operator sequences are not friendly for INT8 – in some cases, latency will not improve and might even get worse. Selective quantization enables you to apply either FP16 or INT8 quantization only to the layers that are quantization friendly so you can enjoy the speed-up of quantization while maintaining FP32 quality.
Optimized Beam Search:
Beam search is a heuristic algorithm that provides a more efficient search mechanism, especially for tasks like sequence-to-sequence prediction. Infery-LLM’s beam search supports all common generation parameters and is highly tuned for the target inference hardware.
Continuous Batching:
Infery-LLM facilitates continuous batching with minimal overhead. In continuous batching, variable-length sequences are grouped together and swapped out in favor of new sequences right when the generated response completes. This ensures that the GPU is always decoding at a maximal batch size and that every generated token is used.
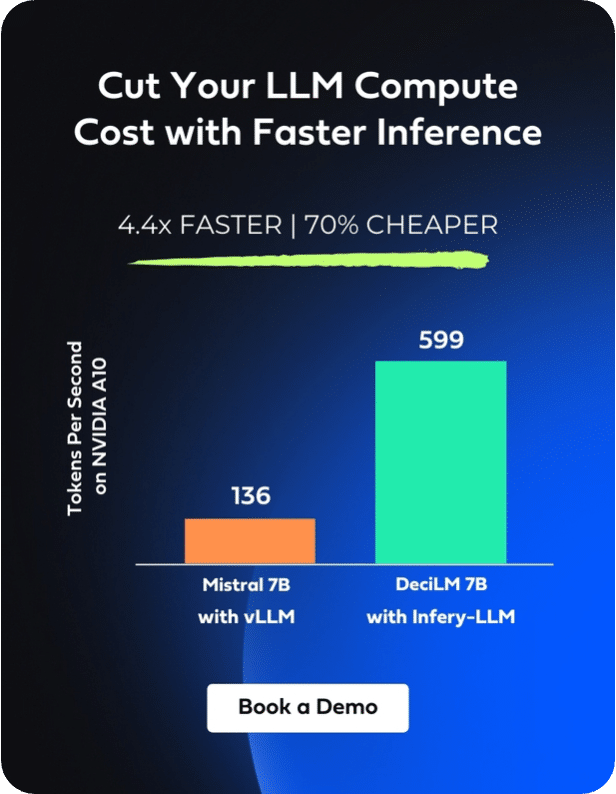
Inference speed with Infery-LLM VS other inferencing libraries
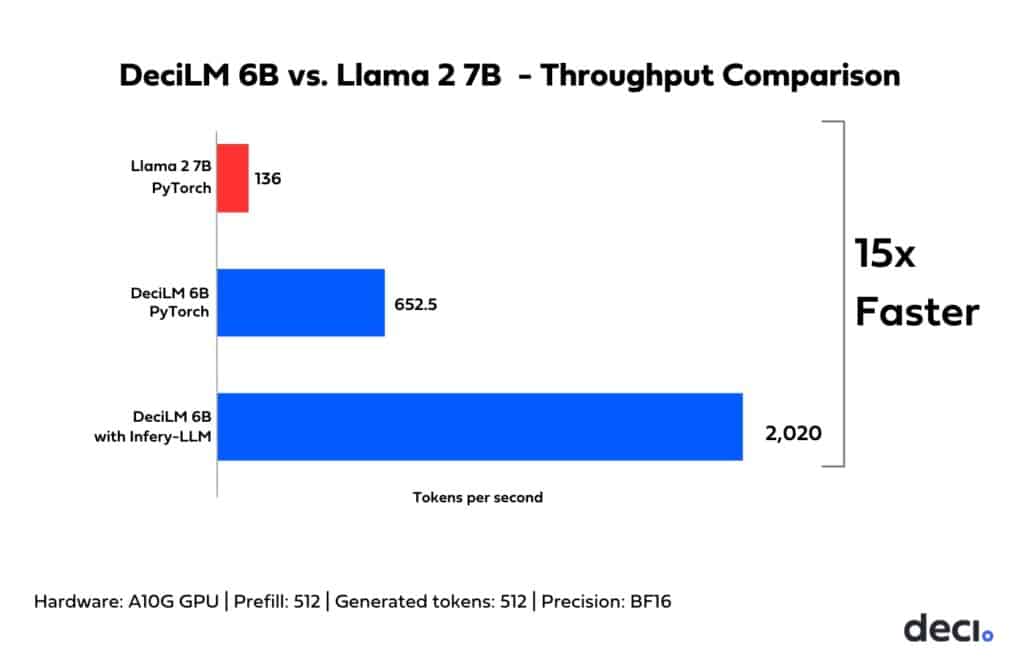
Today, most commonly used Inference serving solutions include HuggingFace Transformers (HF), HuggingFace Text Generation Inference (TGI), vLLM among others. In the below chart you can see the throughput acceleration that can be achieved by combining Deci’s open-source DeciLM 6B with Infery-LLM in comparison to the throughput that is delivered by pairing Llama 2 7B (a comparable model) with the vLLM library.
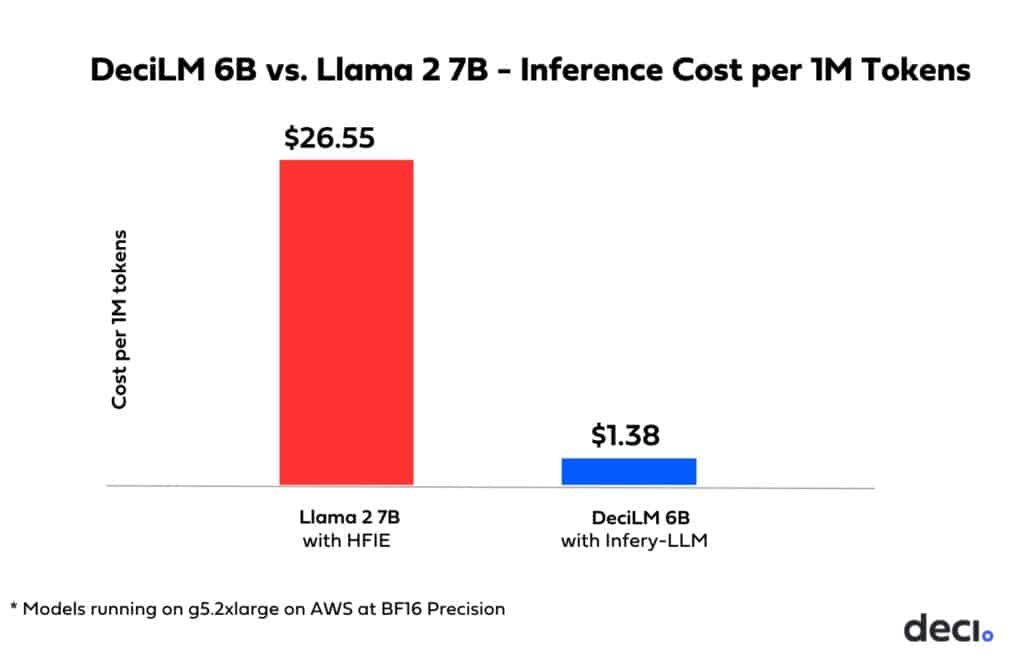
A Game Changer in Inference Cost Reduction
But it’s not just about boosting performance. When coupling Deci’s efficient LLMs with Infery-LLM you can achieve substantial reductions in inference costs – a critical advantage for those aiming at scaled deployments.
In the below chart, you can see the inference compute cost per 1 million tokens with Llama 2 7B with vLLM compared to DeciLM 6B with Infery-LLM. You can save a staggering 90% of your compute cost by using Deci’s efficient LLM and Inference SDK.
Infery-LLM enables you to easily apply advanced acceleration techniques and seamlessly run your models across various environments. Don’t just read about it – experience it. Click below to get a live demo of Infery-LLM and discover how it can redefine the boundaries of what you thought was possible.
Explore Infery-LLM.
Get Started.
From all of us at Deci, here’s to faster, more efficient, and cost-effective Generative AI deployments! 🚀