
The landscape of generative AI is undergoing rapid evolution, propelled by two key developments: the availability of API access to closed-source state-of-the-art Large Language Models (LLMs) like GPT-4 for organizations, and the emergence of potent open-source LLMs such as LLaMA 2. Why are these advancements so noteworthy? They substantially lower the financial barriers to developing LLM-based applications, making such projects accessible to a wider range of organizations. The cost of training an LLM from scratch is notoriously steep; hence, the capability to kick-start the development process with a high-performing, pre-trained model is a game-changer for many teams.
Most companies aspiring to develop applications based on LLMs have two primary options at their disposal: They can either utilize a closed-source model like GPT4 via an API, or build upon an appropriate pre-trained open-source LLM. But which path should they choose? What are the advantages and drawbacks of each, and how do factors such as the specifics of your application and the nature of your business influence this decision? In this blog post, we aim to address these questions, detailing seven crucial elements that you need to understand and evaluate in order to make an informed choice.
Before we delve in, it’s important to acknowledge the dynamic nature of this field: circumstances that hold true today might not remain so tomorrow due to ongoing innovation, or strategic shifts by the key industry players in areas such as licensing or pricing structures. This dynamism has been thoroughly considered in our discussion. We’ve pinpointed the core aspects of both paths that are relatively stable, and those that are subject to change with future developments or industry shifts. Our ultimate goal is to equip you with a robust and adaptable decision-making framework that will serve you well, both now and in the future.
At a Glance
In a rush or need a quick reference? Dive into our cheat sheet below for a snapshot of the key insights. But don’t forget, there’s plenty of detail and nuance awaiting in the rest of the post!
| Commercial LLM API | Open-Source Pre-Trained LLM | |
| Expertise | Expertise in prompt engineering and RAG. | DL/ML expertise required for fine-tuning and deployment. |
| R&D Budget | Low initial costs to get to an MVP. | Initial investment in fine-tuning and deployment setup. |
| Time to Market | Short; though sustainable competitive advantage may be challenging due to lack of differentiation and control. | Short to medium; yet enduring competitive edge can be attained through model customizations and optimization. |
| Control Over Model Quality & Customization | Limited to none. Model is a “black box.” Model updates may hurt app’s quality. | High. Direct access to model architecture, ability to fine-tune, adjust content filters, and perform counterdeployments. |
| Data Privacy | Often requires 3rd party data processing; a deal-breaker for sensitive applications and highly regulated industries. | Full in-house control over data privacy; ideal for enterprises and for handling sensitive data. |
| Inference Speed | No control over model speed. May face API delays, high latency, and disruptions due to rate-limit breaches. | Ability to optimize for lower latency via optimal model and inference setting. |
| Cost Efficiency at Scale | API service provider markup; pay-per-token so cost balloons at scale. | Highly cost-efficient at scale. No cloud vendor “lock-in.” |
Download a PNG version of the table here.
Factor 1: Your Team’s Deep Learning Expertise
When building on top of an open-source LLM, your team needs a deep understanding of Machine Learning and Natural Language Processing (NLP), including proficiency with frameworks such as Keras, PyTorch, and TensorFlow. Additionally, strong skills in Data Science are required, particularly for handling and analyzing large datasets. This is basically the same set of skills your team would need if it were training a model from scratch. In addition, in-depth knowledge of software engineering, system design, and infrastructure management is crucial for designing and implementing scalable, efficient systems.
Conversely, the development of an application using a commercial API involves a shift in skill set focus. A thorough understanding of Machine Learning and NLP tasks is still necessary. But skills in prompt engineering, API integration and software development are more paramount, with an emphasis on frontend and user experience, as the API takes care of the heavy lifting involved in language processing.
If your team lacks extensive expertise in deep learning LLMs, using an API might be an efficient starting point. However, if generative AI forms a significant component of your solutions, or serves as a critical differentiator in your business strategy, it could be worth considering an investment in upscaling or enhancing your team’s skills. This is largely due to the additional flexibility, customizability and control afforded by open-source, non-API models.
Factor 2: Your R&D Budget
Your AI strategy’s budget is a key factor in the choice between utilizing an open-source or a closed-source model. Training a model from scratch is resource-intensive, and most organizations steer clear due to the high costs and extensive data requirements. For context, training Meta’s LLaMA 2 reportedly costs $20 million. Therefore, the pressing question is comparing the R&D expenses of utilizing a pre-trained open-source model versus a commercially available model such as GPT-4.
Consider the costs associated with utilizing a pre-trained open-source model. First, you need to account for the recruitment of a team possessing the necessary expertise. Next, the costs associated with setting up your deployment, either using your own infrastructure or opting for a third-party server. Beyond these expenditures, your R&D budget largely depends on whether or not you fine-tune your model. The exact cost of fine-tuning depends on the size of your model and the dataset used in fine-tuning. Note that recent methods like Low Rank Adaptation (LoRA) have made fine-tuning more efficient, potentially curbing the associated costs.
In contrast, the R&D expenses for utilizing a closed-source model include the recruitment costs and the charges for the API and application deployment. Just as with open-source models, the costs depend on the method of customization you employ. However, even when some closed-source models offer fine-tuning options, the additional cost is often quite minimal due to the per-use-basis pricing model, making the cost of integration and experimentation with your application manageable.
As you compare the costs of the two approaches, keep in mind that leveraging an open-source model provides crucial advantages, which often outweigh the initial cost implications:
Fine-Tuning Capability: Open-source models provide the flexibility to fine-tune even larger models, thereby enhancing performance.
Model Optimization: Open-source models allow you to optimize your model to reduce deployment costs.
Data Security and Proprietary Use: Open-source models help mitigate data privacy constraints and enable you the possibility to use proprietary data in your training and inference without concerns.
In the long run, these benefits can save costs and result in a more effective and efficient generative AI application. Hence, while initial R&D expenses may appear higher with open-source models, the investment can yield considerable returns.
Factor 3: Your Time To Market and Competitive Landscape
In highly competitive markets, swift deployment of innovative features often provides a critical edge. Utilizing a commercial API model can expedite the development and launch of your generative AI application. If your organization is competing in a saturated field and striving to be the first to integrate generative AI into your offerings, the time-savings of an API can accelerate your journey to the finish line.
However, it’s important to consider the long-term perspective. While the speed offered by APIs provides a quick advantage, it’s also true that what’s easily gained can be just as easily lost. Your competitors can access the same APIs and match your own features with equal speed. Building a custom model, whether from scratch or by fine-tuning a pre-trained open-source model, can offer a more enduring competitive advantage. With a custom model you may be able to achieve better performance through fine-tuning and accelerate inference through optimization techniques. These will make your product more competitive by improving user experience and reducing your operational costs.
Factor 4: Your Need for Customization
When you start with a pre-trained Large Language Model (LLM) to build an application, you’ll likely need to customize the model to optimize its performance. This is because pre-trained models may not be trained for your specific task or familiar with the domain-specific information and vocabulary your task requires.
There are three main ways to customize a pre-trained LLM: Full Fine Tuning, Partial Fine Tuning, and Prompt Engineering. Let’s discuss each in turn, highlighting the feasibility with commercial APIs and open-source LLMs.
Full Fine Tuning:
This technique involves training the entire set of model parameters on a specific dataset for a specific task. It results in a model that’s highly tailored to your requirements, offering the best performance. However, full fine tuning can be costly in terms of resources, especially for models larger than 7 billion parameters, as it requires substantial memory and training time.
Parameter Efficient Fine Tuning:
This is a more resource-efficient alternative to full fine tuning. The idea here is that an LLM already contains the most of the necessary knowledge; thus, only a fraction of the model’s parameters needs to be trained. This reduces the cost and the resources needed.
Prompt Engineering:
The third method, prompt engineering, is about guiding the model’s responses by adjusting the instruction or “prompt”. For instance, in an AI application that scores the professionalism of writing samples, developers can guide the model to provide the desired output by crafting careful prompts and examples (few shot learning).
One way to use prompt engineering is to combine it with context retrieval, thereby enabling the model to pull in additional data to refine its responses. This strategy, also known as Retrieval Augmented Generation (RAG) enables developers to enrich the LLM with contextual information that wasn’t included in its initial training set, avoiding the need for full fine-tuning.

In practice, this involves breaking down your data into discrete segments, which are then stored within a vector database. Upon receiving a user’s query, the model scans this database to identify chunks of information that bear semantic resemblance to the query. These relevant pieces are then used to provide additional context to the LLM, aiding in generating a more accurate and contextually aware response.
When you use very large LLMs, with a sufficiently large context window (e.g. GPT 3.5) prompt engineering is often enough for reaching adequate performance. However, it may not provide satisfactory results with smaller models or on tasks that requires knowledge that cannot be gained through context retrieval (consider the scenario of an AI application that needs to provide detailed, domain-specific medical advice based on a large and continually evolving corpus of specialized literature).
One drawback of prompt engineering with closed-source models is that prompts may need to be rewritten when API providers release updated versions of their models, potentially hurting the quality of your product; after the update, the model may be better, but your prompts may not longer work as intended.
While some commercial APIs allow for “fine-tuning” of their models (for instance, OpenAI recently launched fine-tuning for GPT-3.5 Turbo), these models remain black boxes. Users do not get access to the model weights or have the ability to control its fine-tuning parameters. Thus, it’s uncertain what exactly transpires under the hood and whether the resultant quality is comparable to independent fine-tuning (assuming one had the expertise to do it on their own).
What implications does this have for you? If prompt engineering meets the demands of your application, you might want to explore using a large open-source LLM, like LLaMA 2 65.2B. This approach circumvents potential issues that might arise when a commercial model is either updated or retired. However, if you require full or partial fine-tuning to achieve the best performance, it remains uncertain whether OpenAI’s GPT models will be suitable for your purposes.
A separate aspect of customization is Content Filtering. Content filters are essential mechanisms for controlling the outputs of large language models, ensuring safety and relevance of predictions in line with guidelines. They prevent generation of harmful instructions, explicit content, hate speech, or revealing personally identifiable information.
In commercial API setups, these filters cannot be adjusted according to your specific requirements. When building with an open-source model, however, you have the freedom to implement your own content filters, allowing you to more closely align them with your application’s needs. This level of control over the model’s output highlights another advantage of using open-source models, particularly in applications requiring specific content moderation.
Finally, when you use an open-source model, you have full control over the model’s lifecycle. If the model’s performance degrades over time due to changes in the input data distribution or other factors, you can perform counterdeployments to deploy a new model version that is designed to counteract the performance degradation of the previously deployed version. You can conduct A/B testing to compare the old and new model versions. These options aren’t available with closed-source models.
Factor 5: Data Privacy
Data privacy is a paramount concern in today’s digital world and plays a vital role in the decision between utilizing a pre-existing API or creating a custom AI model. This is particularly relevant when your application needs to handle sensitive or proprietary data.
If you build an application on top of an open-source model you have the option of self-hosting your application. The model can be fine-tuned, and deployed within the confines of the organization’s IT infrastructure. This minimizes data leakage risks and enables stringent control over data privacy, in compliance with relevant regulations and standards.
While there are currently some solutions for deploying closed-source LLMs in public clouds, such as Azure’s Open AI offering, most closed-source providers still require that you share your inference data with them through their APIs. While service providers usually employ stringent measures to safeguard this data, risks associated with data leakage or violation of privacy norms persist. Data breaches could lead to loss of intellectual property, reputational damage, and potential legal implications.
Factor 6: Latency Requirements
When it comes to LLMs, latency refers to the time delay between an input being given to the model and the generated output being received. The delay has two main components: computation latency (time taken for the model to process the input and generate the output) and network latency (time taken for data transmission if the model is hosted remotely). Low-latency applications require this delay to be minimal, ensuring a near real-time response for users.
Applications such as interactive chatbots, real-time content creation tools, or question-answer applications prioritize low latency to enhance user experience. In such cases, using an open-source model can be advantageous.
When you use a closed-source model, you have no control over its latency. Model providers tend to batch requests which may result in high latency. You may experience API delays and disruptions from rate limit breaches.
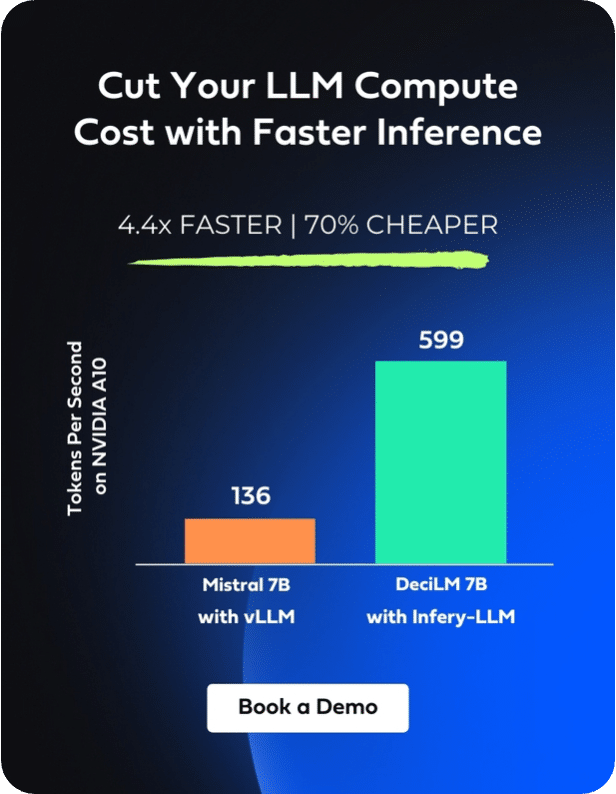
When you use an open-source model, you can control its optimization and deployment. You can optimize the model to accelerate inference by advanced model optimization techniques such as hybrid compilation and selective quantization. You can also minimize latency by selecting the right inference settings (batching). These activities can result in faster, more efficient processing and, consequently, reduced response time.
Furthermore, when using an open-source model, you can choose to build on smaller models with fewer layers and fewer parameters, which typically have faster inference speeds compared to larger ones. There’s compelling evidence suggesting that smaller, domain-specific models can compete with or even surpass larger models in terms of performance. For example, BioMedLM, a biomedical-specific LLM with a mere 2.7 billion parameters, demonstrated comparable if not superior performance to a model with 120 billion parameters. This advantage not only improves latency but also leads to significant savings in fine-tuning and deployment costs.
Factor 7: Cost Efficiency at Scale
When scaling generative AI applications, one critical aspect to consider is the cost of inference. While initially, using an API might appear cost-effective, particularly for applications with low usage, the dynamics can change significantly as the scale of usage increases.
APIs often have a per-token pricing model, which can be pricier than cloud providers like AWS. While the costs associated with these APIs remain lower for limited usage compared to the overhead of deploying an open-source model—given the inherent fixed costs of infrastructure setup—at higher usage levels, the markup on commercial APIs can surpass these initial deployment expenses. The following graph illustrates the per-token price difference between open-source and closed-source deployment.

While HuggingFace Inference Endpoints is not the most affordable open-source model deployment options, it is still significantly less expensive than OpenAI.
Moreover, building your own model or using an open-source one provides you with opportunities to optimize your model and infrastructure for efficiency, potentially reducing resource usage and, therefore, costs.
Model architecture optimization is a key aspect of this process. By choosing a smaller model with fewer parameters, you can significantly reduce the model’s memory footprint and computational complexity. Fewer parameters mean fewer operations during inference, which translates to lower computational costs. By selecting the right model, you can achieve this cost-saving without compromising on quality. As noted earlier, domain-specific models that are smaller can often achieve the same performance as larger, more generalized models, making them a cost-effective choice for applications with specific needs.
Another technique to consider is quantization – the process of reducing the precision of the numbers that the model uses to represent the weights. Lower precision means less memory usage and faster computation, at the potential cost of a slight drop in model accuracy. However, in many cases, this trade-off is well worth it, as the benefits in terms of reduced cost and increased speed far outweigh the minor impact on accuracy.
On the infrastructure side, there are several strategies that can be employed to further reduce costs. For instance, using multiple GPUs in parallel can speed up inference, thereby reducing the overall time (and cost) of model deployment. Similarly, batching – the process of running multiple inputs through the model at the same time – can help maximize the utilization of your computing resources and cut down on the cost per inference.
In conclusion, while APIs may provide an economical starting point for small-scale applications, businesses anticipating high-volume usage or a significant role for generative AI in their services might find a custom model more cost-effective in the long run.
The Upshot
If your aim goes beyond merely crafting a Minimum Viable Product (MVP) and you envision a competitive, high-quality, and scalable solution, then the open-source model stands out as the better choice. With open-source, you benefit from enhanced control over latency, cost, and the overall quality of the model.
Yet, this control doesn’t automatically ensure the finest results. Achieving such results demands a robust foundation model characterized by both precision and efficiency. It also calls for expertise in fine-tuning, optimizing for accelerated inference, and selecting the right inference settings. This process necessitates profound expertise and can sometimes come with high developmental costs.
Deci’s Open-Source LLMs and Developer Tools
Deci’s generative AI offerings, spanning powerful foundation LLMs and developer tools, empower developers and businesses to roll out superior AI applications more rapidly. With Deci, scaling becomes more wallet-friendly, and the user experience is significantly uplifted due to enhanced inference speeds.
So, how does Deci bring this to the table? We present a suite of highly efficient LLMs that you can seamlessly fine-tune with your data on-premises or in your private cloud. We prioritize your data’s confidentiality, eliminating the need for sharing. Once fine-tuned, the model is ready for optimization and deployment with our state-of-the-art inference SDK, Infery, ensuring unmatched performance.
For illustration, let’s delve into DeciCoder—our open-source code generation LLM.
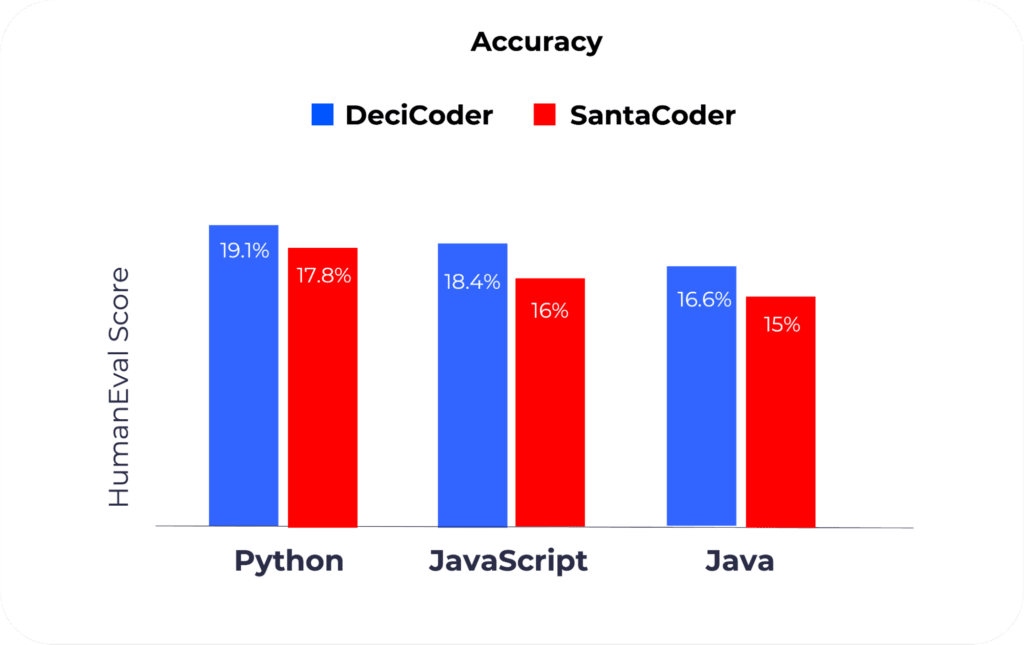
1. Accuracy
In a direct accuracy comparison using the HumanEval benchmark, DeciCoder outperforms popular models such as SantaCoder.
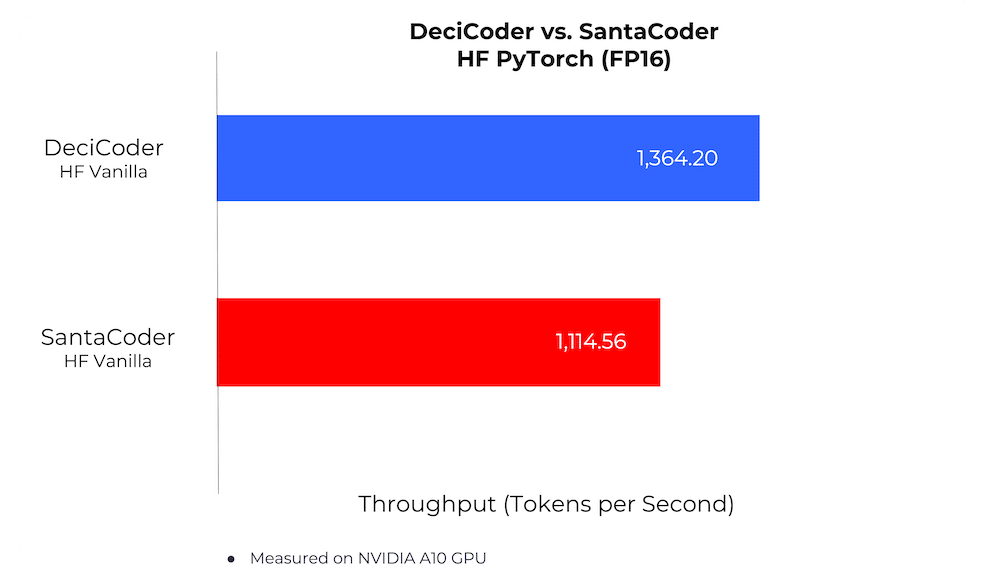
2. Inference Speed
On its own merit, DeciCoder delivers a 22% increase in throughput compared to SantaCoder, all the while maintaining a leaner memory footprint.
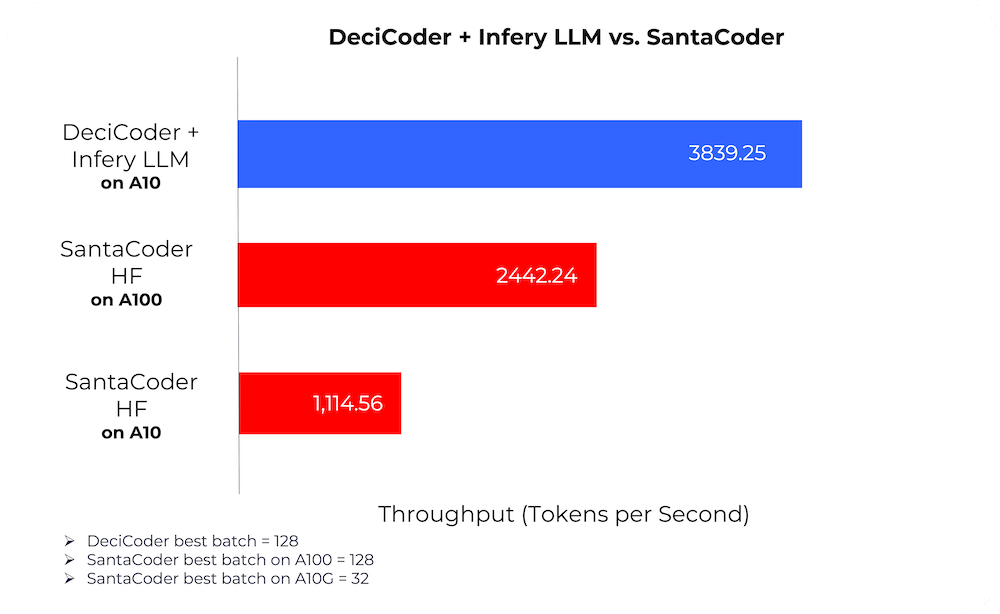
3. Cost Efficiency
When paired with Infery-LLM, DeciCoder’s throughput on NVIDIA A10G surges to be 3.5 times that of SantaCoder’s on the NVIDIA A10G GPU and 1.6 times that of SantaCoder’s on the NVIDIA A100 GPU.
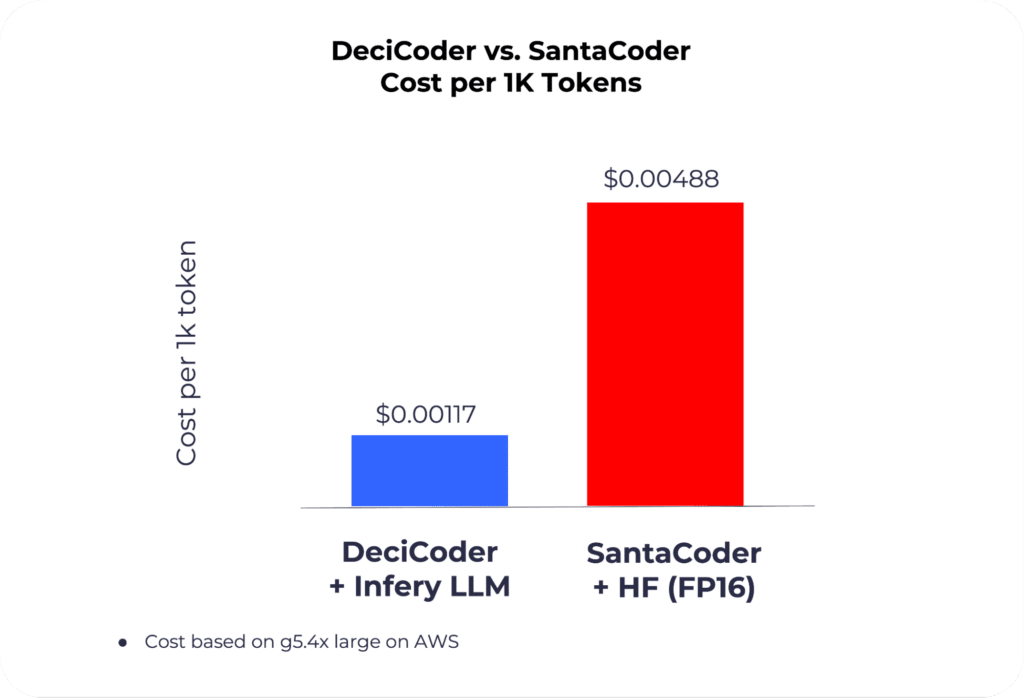
This presents a compelling proposition: with DeciCoder, you can significantly reduce inference costs by opting for more cost-effective GPUs, like the NVIDIA A10G over the NVIDIA A100, without trading off on speed or accuracy.
Curious about DeciCoder? Dive deeper by exploring our blog.
To learn more about Deci’s Gen AI foundation models and inference SDK, get started today!









{kind=link}