
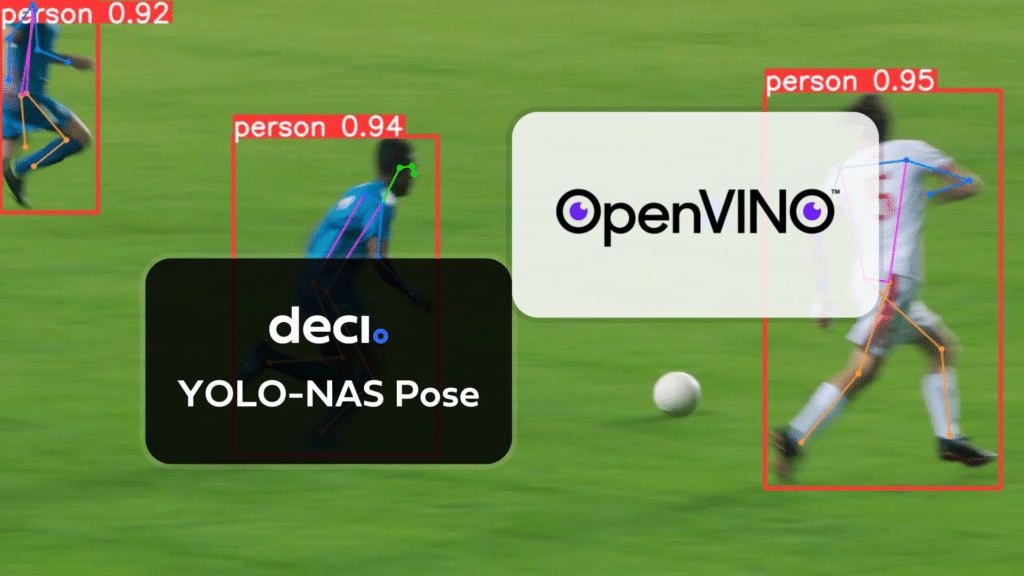
In this guide, we cover exporting YOLO-NAS Pose models to the OpenVINO format, which can provide up to 3x CPU speedup as well as accelerating on other Intel hardware (iGPU, dGPU, VPU, etc.).
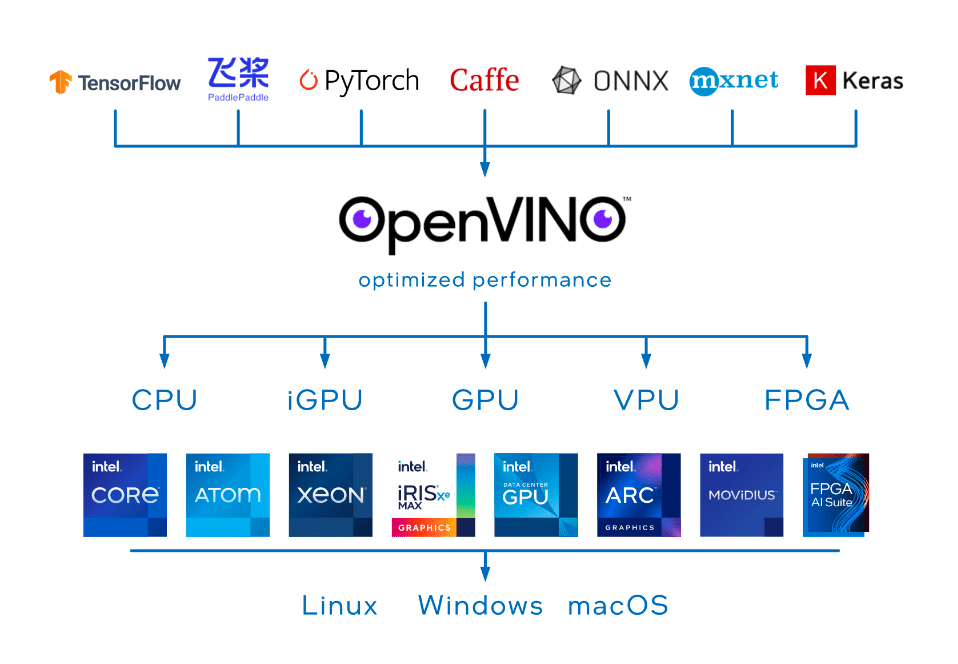
OpenVINO, short for Open Visual Inference & Neural Network Optimization toolkit, is a comprehensive toolkit for optimizing and deploying AI inference models. Even though the name contains Visual, OpenVINO also supports various additional tasks including language, audio, time series, etc.
Why We Need to Export Trained YOLO-NAS Pose Model to Openvino IR Format?
Exporting a trained YOLO-NAS Pose model to the OpenVINO Intermediate Representation (IR) format provides numerous advantages, particularly for deploying the model on Intel hardware. Key reasons for converting a YOLO-NAS Pose model to OpenVINO IR format include:
Leveraging the full potential of YOLO-NAS
Running YOLO-NAS Pose on Intel CPUs, especially 4th generation Intel Xeon CPUs significantly enhances efficiency and accuracy. For instance, YOLO-NAS Pose M variant shows a 38% reduction in latency and a +0.27 AP increase in accuracy over YOLOV8 Pose L when tested on Intel Gen 4 Xeon CPUs with OpenVINO. Utilizing OpenVINO’s tools for deploying on Intel hardware is key to unlocking these performance gains.
Hardware-Specific Model Optimization:
OpenVINO optimizes deep learning models for a range of Intel hardware, such as CPUs, GPUs, FPGAs, and VPUs. Converting the model to OpenVINO IR format unlocks hardware-specific optimizations, enhancing inference speed and efficiency on Intel-based devices.
Performance Boost:
OpenVINO employs techniques like quantization and layer fusion to accelerate inference. The optimized IR format ensures efficient utilization of hardware capabilities, resulting in faster inference times compared to running the model directly in other frameworks.
Model Shrinking:
The OpenVINO Model Optimizer applies compression techniques like pruning and quantization, reducing the model size while maintaining reasonable accuracy. Smaller models demand less memory, making them well-suited for deployment on edge devices with limited resources.
Unified Inference Engine:
OpenVINO provides a unified inference engine compatible with various Intel hardware types. Once converted to IR format, the model becomes hardware-agnostic, allowing deployment on different Intel-based devices seamlessly.
Ease of Deployment:
OpenVINO includes pre-optimized libraries for different hardware types, simplifying and streamlining the deployment process. Integrating the IR model into your application becomes more straightforward.
Leveraging Intel’s AI Development Software Portfolio:
Intel’s commitment to AI, anchored by the oneAPI programming model, goes beyond OpenVINO to offer a wide range of AI development tools. This model promotes interoperability, openness, and extensibility, ensuring smooth integration across Intel’s AI technologies. Converting models to OpenVINO’s IR format not only optimizes them for Intel hardware but also connects developers to Intel’s broader ecosystem, enabling the use of additional tools and libraries to enhance the AI development cycle from data preparation to deployment.
Included in Intel’s AI development software portfolio are:
- End-to-End Python Data Science and AI Performance Enhancement: A toolkit that supports machine learning, deep learning, and inference optimization with components from conda, pip, and Docker repositories. It includes optimized deep learning frameworks, machine learning extensions like scikit-learn and XGBoost, and the Intel Distribution of Modin for accelerated data analytics.
- Automated Model Optimization: The Intel Neural Compressor, an open-source library for model optimization, supports automation in quantization, pruning, and knowledge distillation, compatible with frameworks such as PyTorch, TensorFlow, ONNX Runtime, and Apache MXNet.
- Additional Tools and Libraries: This category encompasses BigDL for distributed deep learning, the Intel Distribution for Python featuring optimized computational packages, Intel AI Reference Models for access to optimized AI models, Cnvrg.io for MLOps, SigOpt for hyperparameter optimization, and software support for Intel Gaudi accelerators.
In summary, optimizing with OpenVINO streamlines deployment and enhances model performance, granting access to Intel’s extensive toolkit to support AI application development across all stages.
What is YOLO-NAS Pose?

In the dynamic landscape of computer vision, a paradigm-shifting advancement takes center stage with the introduction of YOLO-NAS Pose. Crafted by the visionary team at Deci, YOLO-NAS Pose isn’t merely an evolution; it signifies a complete reimagining of the boundaries within pose estimation. Positioned to transform diverse industries, this model stands out for its unparalleled combination of accuracy and speed, positioning it as a transformative force in realms such as healthcare diagnostics, athletic performance analytics, and security systems. More about it here: https://deci.ai/blog/pose-estimation-yolo-nas-pose/.
YOLO-NAS Pose elevates the foundational excellence of YOLOv8 Pose to unprecedented levels. At its essence, this model is meticulously crafted using the cutting-edge NAS framework, AutoNAC. Designed to optimize the architecture with meticulous precision, AutoNAC gives rise to a model that seamlessly integrates an ingenious pose estimation head into the YOLO-NAS structure, thereby ensuring unparalleled efficiency and performance, particularly when running on Intel Xeon CPUs. Performance graph and table below.
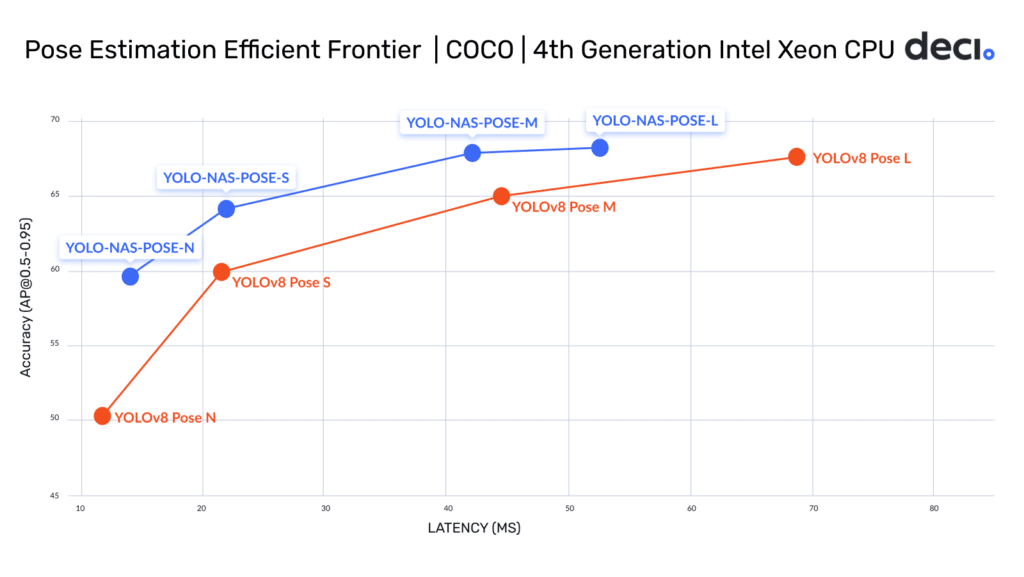
| Number of Parameters (In millions) | [email protected] | Latency (ms) Intel Xeon gen 4th (OpenVino) | Latency (ms) Jetson Xavier NX (TensorRT) | Latency (ms) NVIDIA T4 GPU (TensorRT) | |
| YOLO-NAS N | 9.9M | 59.68 | 14 | 15.99 | 2.35 |
| YOLO-NAS S | 22.2M | 64.15 | 21.87 | 21.01 | 3.29 |
| YOLO-NAS M | 58.2M | 67.87 | 42.03 | 38.40 | 6.87 |
| YOLO-NAS L | 79.4M | 68.24 | 52.56 | 49.34 | 8.86 |
YOLO-NAS Pose: From Training to Inference
The training regimen of YOLO-NAS Pose demands a particular focus. It integrates sophisticated loss functions, strategic data augmentation, and a meticulously devised training schedule. The result is a robust model that caters to a variety of computational demands and crowd densities without compromising accuracy. To run inference or train your custom model using your own data, follow our well explained guide here: https://colab.research.google.com/drive/1agLj0aGx48C_rZPrTkeA18kuncack6lF.
Project Structure
Export YOLO-NAS Pose trained model to OpenVINO IR format
import openvino as ov
import torch
from super_gradients.training import models
from super_gradients.common.object_names import Models
# path to an image file
source = 'pose.jpg'
# loading an image for testing YOLO-NAS Pose model.
model = models.get(Models.YOLO_NAS_POSE_N,
pretrained_weights="coco_pose")
# Testing model on loaded image
model.predict(source, conf=0.50).show()
# prepare dummy input data
input_data = torch.rand(1, 3, 224, 224)
# converting Pose model to Openvino
ov_model = ov.convert_model(model, example_input=input_data)
# save model to OpenVINO IR for later use
ov.save_model(ov_model, 'model.xml')
# Compile and infer with OpenVINO:
compiled_model = ov.compile_model('model.xml')
# run inference
result = compiled_model(input_data)
print(result)
Explanation of the above code
Please be advised that successful execution of the provided code necessitates the establishment of a virtual environment with the installation of requisite packages, including SuperGradients, torch, and the OpenVINO package, along with the essential dependencies for OpenVINO.
To accomplish this, follow the subsequent steps using Visual Studio Code (VSCode). Initiate by creating a directory on your desktop and opening it with VSCode. Utilize the terminal in VSCode and sequentially execute the following commands to establish the virtual environment and install the specified packages.
# Step 1: Create a virtual environment python -m venv openvino_env # Step 2: Activate the virtual environment openvino_env\Scripts\activate # Step 3: Upgrade pip to the latest version python -m pip install --upgrade pip # Step 4: Download and install the OpenVINO package pip install openvino==2023.2.0 # Step 5: Download and install super-gradients pip install super-gradients # Step 6: Download and install torch pip install torch
Note: The provided instructions assume the use of VSCode for the tutorial and are designed to be executed in a Windows environment. Adjustments may be necessary for other platforms or development environments.
Following the successful installation of the aforementioned packages, proceed by importing the essential libraries required for converting the model to the OpenVINO format. Utilize the following code snippet:
import openvino as ov import torch from super_gradients.training import models from super_gradients.common.object_names import Models
Upon successful library imports, the next step involves loading an image file and the YOLO-NAS Pose model, followed by testing the loaded model with the provided image to ensure proper functionality. Utilize the following code snippet:
# path to an image file
source = 'pose.jpg'
# loading an image for testing YOLO-NAS Pose model.
model = models.get(Models.YOLO_NAS_POSE_N,
pretrained_weights="coco_pose")
# Testing model on loaded image
model.predict(source, conf=0.50).show()
In this code segment, the variable source contains the file path of the image (‘pose.jpg’). The YOLO-NAS Pose model is loaded using the models.get function from the super_gradients.training.models module, specifying the YOLO-NAS Pose model and its pretrained weights (‘coco_pose’). Finally, the predict method is used to test the model on the loaded image with a confidence threshold of 0.50, and the result is displayed. Adjust the file path or other parameters as needed for your specific use case.

The provided code snippet demonstrates the creation of dummy input data, conversion of the model to the OpenVINO format, and saving the resulting model for future use:
# prepare dummy input data input_data = torch.rand(1, 3, 224, 224) # converting Pose model to Openvino ov_model = ov.convert_model(model, example_input=input_data) # save model to OpenVINO IR for later use ov.save_model(ov_model, 'model.xml')
In this code:
input_data is generated as dummy input data with dimensions (1, 3, 224, 224).The Pose model (model) is converted to the OpenVINO format using ov.convert_model, and the dummy input data (input_data) is provided as an example input.The converted OpenVINO model (ov_model) is then saved in the OpenVINO Intermediate Representation (IR) format with the filename ‘model.xml’ using ov.save_model.
The following code snippet demonstrates the compilation of the saved OpenVINO model and the execution of inference on the compiled model:
# Compile and infer with OpenVINO:
compiled_model = ov.compile_model('model.xml')
# run inference
result = compiled_model(input_data)
print(result)
In this code:
The OpenVINO model saved in the Intermediate Representation (IR) format (‘model.xml’) is compiled using ov.compile_model, and the resulting compiled model is stored in the variable compiled_model.
Inference is performed on the compiled model using compiled_model(input_data), where input_data is the previously prepared dummy input data.
The inference result is printed using print(result).
Conclusion
The benchmarking results clearly demonstrate the benefits of exporting the YOLO-NAS Pose model to the OpenVINO format. Across different models and hardware platforms, the OpenVINO format consistently outperforms other formats in terms of inference speed while maintaining comparable accuracy.
For the Intel® Data Center GPU Flex Series, the OpenVINO format was able to deliver inference speeds almost 10 times faster than the original PyTorch format. On the Xeon CPU, the OpenVINO format was twice as fast as the PyTorch format. The accuracy of the models remained nearly identical across the different formats.
For more detailed information and instructions on using OpenVINO, refer to the official OpenVINO documentation.
YOLO-NAS Pose is just one part of Deci’s extensive range of foundation models. Within this collection, you’ll find DeciSegs, the SOTA hyper-performant semantic segmentation models and the YOLO-NAS models, designed for hyper-efficient object detection. Each family within Deci’s foundation models is meticulously crafted using the AutoNAC engine. It is tailored to excel in specific computer vision tasks and optimized for given hardware and dataset characteristics.
Upon choosing a foundation or custom model, you can train or fine-tune it using your own data via SuperGradients. To further boost your model’s efficiency and inference speed, Deci’s Infery SDK is an invaluable tool.
Discover more about Infery and using Deci’s foundation models for commercial applications, by booking a demo with us.








