
Object detection stands out as a crucial technology in the dynamic field of artificial intelligence. It serves as the foundation for a multitude of advanced applications, enabling AI systems to understand and interact with the world. This blog compares two significant players in object detection—YOLOv8 and Deci’s YOLO-NAS—to explore their technological advancements.
The Essence of Object Detection
Object detection, a core aspect of computer vision, enables machines to recognize and pinpoint multiple objects within images or video frames, typically achieved by outlining each object with bounding boxes. The impact of this technology extends across various industries, influencing the development of autonomous systems, surveillance, robotics, and more.
The Starring Models: YOLOv8 and YOLO-NAS
In this examination of object detection’s cutting edge, we focus on two powerful models: YOLOv8 and Deci’s YOLO-NAS. As trailblazers in innovation, these models embody the relentless pursuit of efficiency, low latency, and accuracy. Join us as we delve into the intricacies of these models—analyzing their strengths, weaknesses, and profound influence on the AI landscape.
The Evolution of Yolo
Over the past seven years, the evolution of the You Only Look Once (YOLO) models has significantly influenced the landscape of object detection technology.
YOLOv1 (2016): A Game Changer
Introduced in 2016, YOLOv1 revolutionized object detection by adopting a regression-based paradigm and employing a single convolutional neural network (CNN) to process the entire image. This departure from the conventional two-stage approach allowed for the simultaneous prediction of multiple bounding boxes and class probabilities.
YOLOv2 (2016): Embracing Improvements
Building upon its predecessor, YOLOv2, introduced in December 2016, incorporated batch normalization and anchor boxes from Faster R-CNN. These enhancements boosted the model’s learning efficiency, reduced overfitting, and improved stability and performance.
YOLOv3 (2018): Scaling New Heights
April 2018 saw the release of YOLOv3, which further refined object detection. Predicting objects at multiple scales and adopting the more efficient Darknet-53 backbone architecture contributed to its increased accuracy and speed.
YOLOv4 (2020): Optimization and Controversy
YOLOv4, launched in April 2020, optimized resource utilization and introduced the CSPDarknet53 backbone architecture. Despite some controversy surrounding its release, YOLOv4 remains a top-performing model in terms of accuracy, speed, and efficiency.
YOLOv5 (2020): Maintaining Momentum
Developed by Ultralytics in May 2020, YOLOv5 introduced the CSP architecture, enhancing accuracy and maintaining fast inference speeds. The model’s versatility, with a range of sizes catering to different use cases, marked a significant step forward.
YOLOv6 (2021): Power and Efficiency
July 2021 saw the emergence of YOLOv6, featuring the Scaled-YOLOv4, a smaller and more efficient version optimized for mobile and edge devices. This version maintained accuracy while improving inference speed and introduced novel data augmentations.
YOLOv7 (2021): Speed and Simplicity
Released in December 2021, YOLOv7, developed by the original YOLO team, focused on speed and simplicity. With a new anchor-free architecture and a straightforward design, YOLOv7 prioritized ease of understanding and modification for specific use cases.
YOLOv8 (2022): Cutting-Edge Performance
April 2022 marked the release of YOLOv8, the latest version developed by Ultralytics . Featuring a dynamic prediction scheme and a new feature pyramid network architecture, YOLOv8 set new standards in performance, adjusting predictions based on image complexity and improving accuracy on both small and large objects.
For a comprehensive review of the advancements of YOLO models, from the original YOLOv1 to YOLOv8, we invite you to read our blog, “The History of Object Detection Models from YOLOv1 to YOLOv8.”
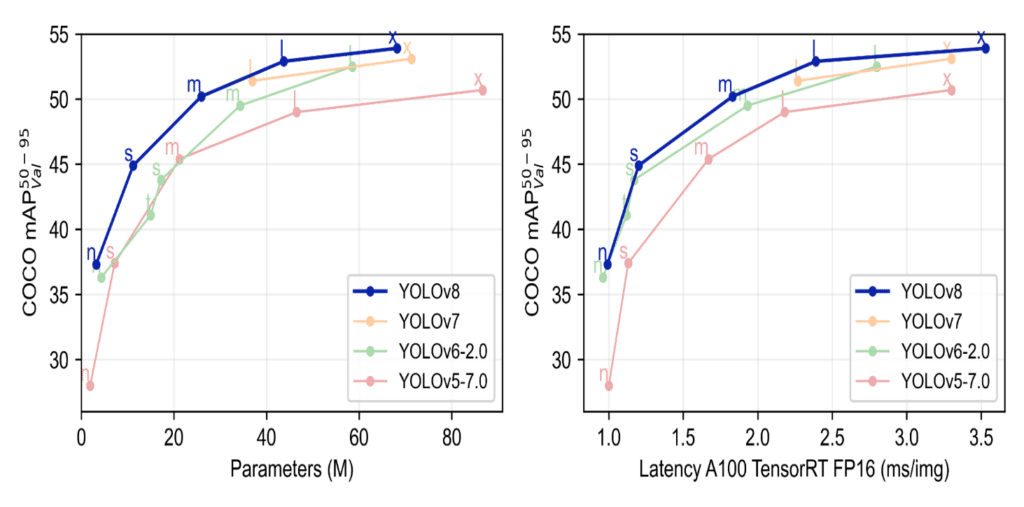
An Overview of YOLOv8’s Architecture and Key Features
The YOLOv8 Architecture
The YOLOv8 architecture comprises two main components: the backbone and the head, each contributing to its prowess in object detection.
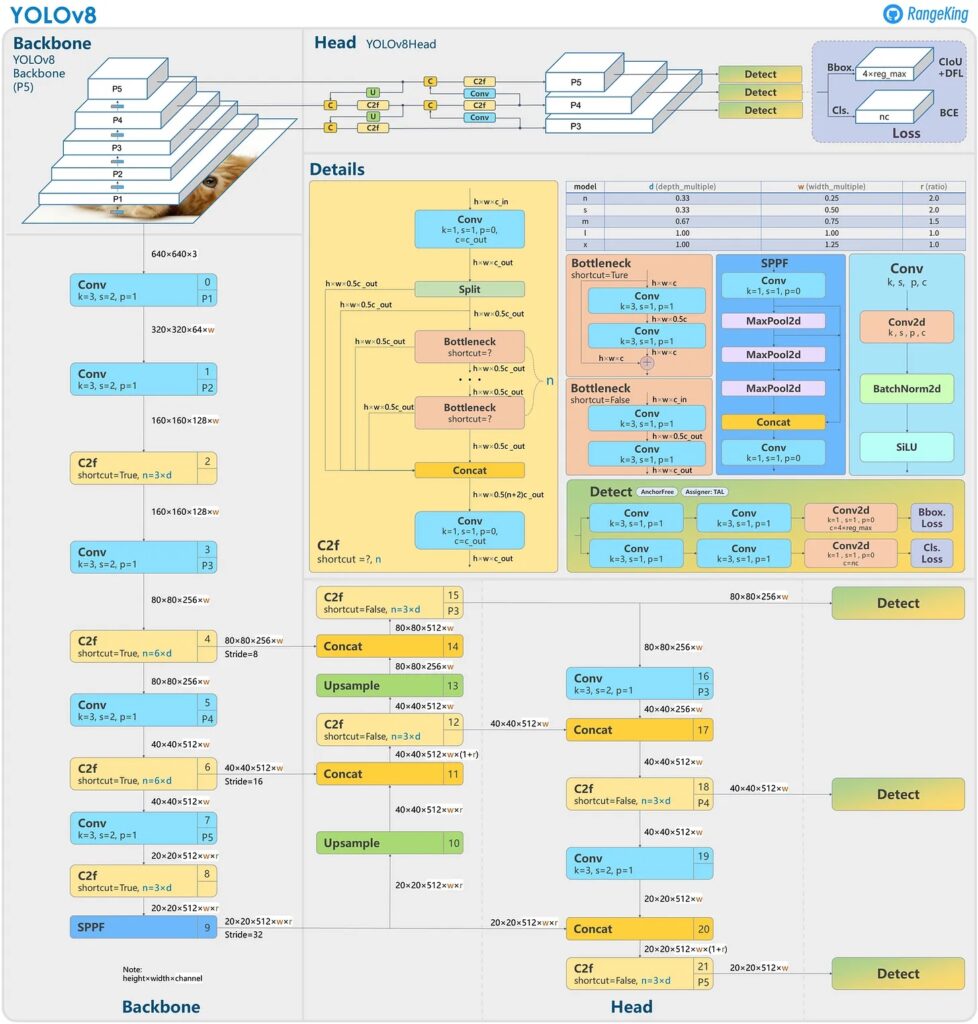
1: Backbone: A Modified CSPDarknet53
The backbone of YOLOv8 is a modified version of the CSPDarknet53 architecture, featuring 53 convolutional layers. What sets it apart is the incorporation of cross-stage partial connections, enhancing information flow between layers. This strategic design improves the model’s ability to understand complex patterns and relationships within images.
2: Head: Precision in Prediction
The head of YOLOv8 is composed of multiple convolutional layers followed by fully connected layers. This segment plays the crucial role of predicting bounding boxes, objectness scores, and class probabilities for identified objects in an image. It acts as the decision-making hub, refining the model’s predictions with each layer.
Key Features of YOLOv8
Self-Attention Mechanism
YOLOv8 incorporates a self-attention mechanism into the network’s head. This novel feature enables the model to dynamically focus on different regions of an image, adjusting the significance of various features based on their relevance to the detection task. This enhances adaptability and contributes to an overall improvement in performance.
Multi-Scaled Object Detection
Within its architecture, YOLOv8 introduces a feature pyramid network. This network comprises multiple layers specifically designed to detect objects at various scales. This multi-scaled approach enhances the model’s capability to effectively identify objects of different sizes within an image.
Deci’s YOLO-NAS
Deci AI’s YOLO-NAS represents a groundbreaking milestone in the evolution of object detection models. Generated with the use of advanced Neural Architecture Search (NAS) technology, this foundational model is meticulously crafted to transcend the limitations of its YOLO predecessors. With a primary focus on overcoming challenges and pushing the boundaries of performance, YOLO-NAS introduces substantial advancements, notably in quantization support and an improved accuracy and latency trade-off.
Distinctive Architectural Features of YOLO-NAS
YOLO-NAS stands out in the realm of object detection architectures due to its unique combination of advanced techniques and design elements. Each feature contributes significantly to its overall performance and versatility. Here are four key distinctive architectural features of YOLO-NAS:
1. Quantization Aware Blocks and Selective Quantization
YOLO-NAS uniquely integrates quantization-aware blocks and adopts a hybrid quantization strategy, ensuring superior performance, particularly in environments with limited resources. This architecture utilizes Quantization-Specific Parameters (QSP) and Quantization-Centric Initialization (QCI) blocks, which blend the benefits of re-parameterization with 8-bit quantization. These blocks, inspired by the methodology suggested by Chu et al., are specifically designed to minimize accuracy loss during post-training quantization.
A key aspect of YOLO-NAS’s approach is selective quantization, which strategically quantizes specific parts of the model. This method effectively balances accuracy and latency while mitigating information loss — a common issue with standard quantization techniques that uniformly affect all layers, often leading to substantial accuracy degradation.
The hybrid quantization method improves the quantization process to preserve accuracy. It does so by selectively quantizing certain layers while keeping others in their original state. The decision about which layers to quantize is driven by a sophisticated layer selection algorithm. This algorithm evaluates the impact of each layer on the model’s accuracy and latency, and carefully considers the implications of toggling between 8-bit and 16-bit quantization on the overall latency of the model. Such an optimized approach ensures that YOLO-NAS remains both efficient and accurate, a crucial balance for advanced object detection tasks.
2. Detection Head with Distribution Probability for Size Regression
A standout feature of YOLO-NAS is its detection head design, which predicts a distribution probability for size regression. This approach is particularly useful in scenarios where the object sizes vary significantly. By predicting a range of possible sizes rather than a single fixed size, YOLO-NAS enhances its accuracy in detecting objects of varying scales. This probabilistic approach to size regression also makes YOLO-NAS suitable for knowledge distillation. It allows for a more nuanced transfer of knowledge from a complex, high-capacity teacher model to a simpler, more efficient student model, further enhancing the practicality of YOLO-NAS in diverse applications.
3. Pyramid-Attention Neck with Top-Down and Bottom-Up Information Flows
YOLO-NAS features a sophisticated pyramid-attention neck that integrates both top-down and bottom-up information flows. This design element enhances the network’s ability to capture and utilize multi-scale information effectively. In the pyramid-attention structure, the top-down pathway aids in capturing high-level semantic information, while the bottom-up pathway focuses on finer details. The attention mechanism within this pyramid structure ensures that the network focuses on the most relevant features at different scales, thereby improving its ability to detect objects with varying sizes and complexities.
4. NAS-Generated Backbone Design with AutoNAC
The backbone of YOLO-NAS, a pivotal component in its architecture, is a product of an advanced Network Architecture Search (NAS) process, specifically utilizing Deci’s proprietary NAS technology, AutoNAC. This innovative approach enables the tailoring of the network structure to meet the specific demands of object detection tasks with unparalleled precision.
AutoNAC, as a part of the NAS process, plays a critical role in determining the optimal sizes and structures of various stages within the YOLO-NAS backbone. This includes meticulously configuring the block type, the number of blocks, and the number of channels in each stage. By doing so, AutoNAC ensures that each aspect of the backbone is precisely optimized for its function.
The NAS-generated backbone, therefore, is not just a result of automated design but also of intelligent decision-making that considers a multitude of factors. This includes computational efficiency, accuracy, and speed, ensuring that the backbone contributes effectively to the overall robustness and adaptability of YOLO-NAS.
These advancements culminate in a superior architecture with unprecedented object detection capabilities and outstanding performance over its predecessors.
AutoNAC: Revolutionising YOLO-NAS Performance
Deci-AI uses AutoNAC technology which is an optimization engine developed by Deci. AutoNAC applies Neural Architecture Search (NAS) to refine the architecture a deep learning model in order to improve the model’s performance when run on specific hardware, without compromising, and sometimes even improving, the model’s accuracy.
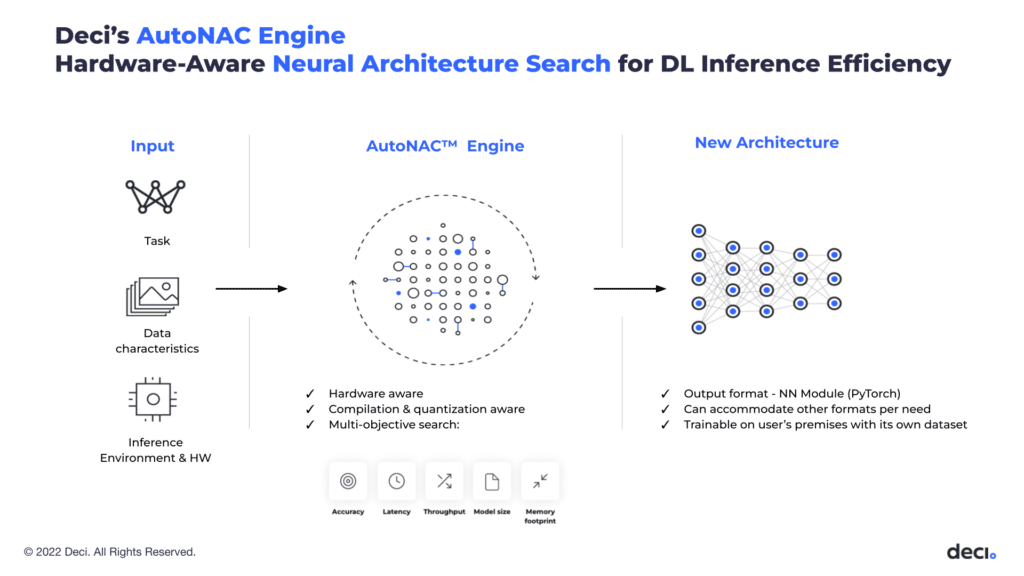
Benefits of YOLO-NAS
Optimized Efficiency
YOLO-NAS excels in achieving an optimal balance between accuracy and speed, surpassing other human-designed models in terms of efficiency. This optimization plays a pivotal role in enhancing inference speeds and improving resource utilization, which are essential for the demands of real-time object detection applications.
Adaptability to Diverse Tasks and Hardware
YOLO-NAS’s architecture makes it adaptable to a variety of object detection tasks, ranging from common objects to more intricate scenarios and hardware. This versatility positions YOLO-NAS as a valuable tool across a spectrum of applications.
Training on Prominent Datasets:
YOLO-NAS enhances its capabilities through pre-training on the well established Object365, followed by training on COCO. This strategic pre-training equips the model with a comprehensive understanding of common object features, significantly boosting its accuracy when presented with new and previously unseen images.
Variations of YOLO-NAS
Three different versions of YOLO-NAS have been released. Small, Medium, and Large, with and without quantization. These models create a new efficiency frontier for object detection.
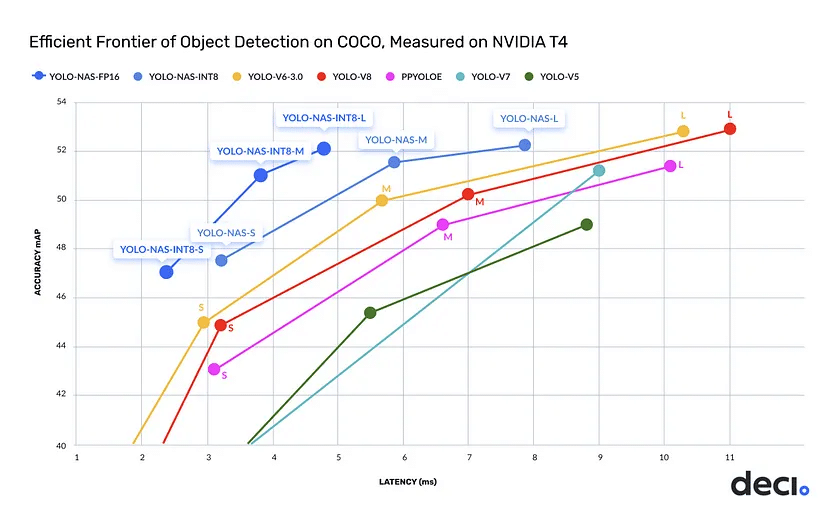
Performance of YOLO-NAS Compared to Other YOLO Models
YOLO-NAS marks a paradigm shift in object detection, demonstrating State-of-the-Art (SOTA) performance that surpasses its predecessors, including YOLOv5, YOLOv6, YOLOv7, and YOLOv8. This update not only introduces cutting-edge features but also achieves an unparalleled accuracy-speed combination, redefining benchmarks in the field.
In summary, the YOLO-NAS update signifies a groundbreaking advance in object detection performance. Its focus on unbeatable accuracy-speed dynamics underscores the prowess of YOLO-NAS across its different versions. The substantial increase in mean Average Precision (mAP) values and the incorporation of quantization propel YOLO-NAS to the forefront of State-of-the-Art models, establishing a new standard for excellence in object detection technology. See the accuracy against latency graph below for a visual representation.
Advantages of Opting for YOLO-NAS Over Previous Versions
Superior Fine-Tuning Capabilities
In the realm of artificial intelligence and computer vision, mAP, or Mean Average Precision, serves as a crucial metric for assessing the performance of object detection algorithms, image segmentation, and information retrieval systems.
As part of an experimental validation, the team decided to evaluate the models’ performance by fine-tuning RoboFlow’s “RoboFlow100 dataset.” This test was designed to showcase the models’ proficiency in handling intricate object detection tasks.
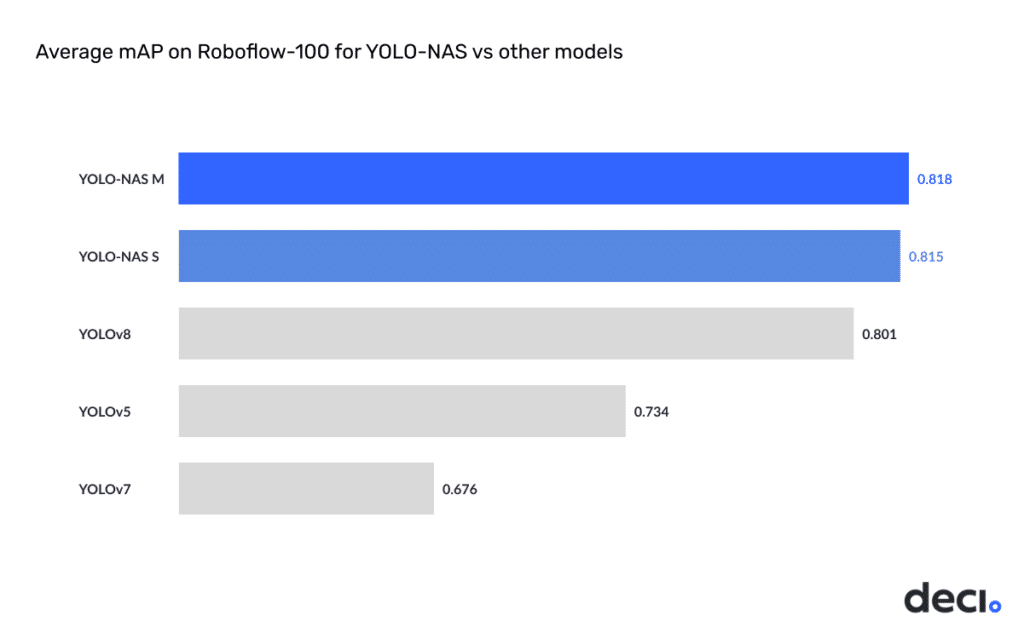
Detection and Localization Accuracy: Unveiling YOLO-NAS Excellence
YOLO-NAS distinguishes itself as a top performer in small object detection, showcasing exceptional proficiency in identifying and localizing diminutive objects. Its specialized architecture adeptly addresses challenges associated with small or intricate objects, providing not only heightened detection capabilities but also improved accuracy in pinpointing precise locations. These advancements position YOLO-NAS as a superior choice for a diverse range of applications, especially those where identifying small or elusive objects is pivotal.
While YOLOv8 is an impressive object detection model, it encounters limitations when tasked with the intricate challenge of small object detection and localization accuracy. Although proficient in various scenarios, YOLOv8 falls short compared to the specialized capabilities of YOLO-NAS in handling challenges posed by diminutive objects. The architectural trade-offs in YOLOv8 become apparent in scenarios where precision in small object detection is paramount.

YOLO-NAS in Real-Time Edge-Device Applications: Efficiency, Accuracy, and Excellence
In real-time edge-device applications, YOLO-NAS stands as a beacon of efficiency, accuracy, and excellence, outperforming its counterparts.
YOLO-NAS not only delivers real-time capabilities but does so with a remarkable performance-per-compute ratio, maximizing computational resources. This makes it an optimal choice for edge devices with constrained processing power.
The model solidifies its suitability for edge-device applications through features such as Post-Training Quantization (PTQ) and quantization-friendly basic blocks. These elements not only enhance efficiency but also facilitate seamless integration into resource-constrained environments.
YOLO-NAS Availability to the Community
The YOLO-NAS architecture is available under an open-source license. Its pre-trained weights are available for research use (non-commercial) on SuperGradients, Deci’s PyTorch-based, open-source computer vision training library. Whether you’re a researcher, developer or enthusiast, we encourage you to leverage this state-of-the-art foundation model in your work.
The open-source SuperGradients training toolkit facilitates easier model training and fine-tuning for specific use cases.
Conclusion
Both YOLO-NAS and YOLOv8 stand as robust object detection models. Yet, YOLO-NAS demonstrates superior performance in critical aspects such as small object detection, localization accuracy, post-training quantization, and real-time edge-device applications. YOLO-NAS is the clear choice for those seeking a state-of-the-art object detection model with heightened accuracy, faster processing, and superior efficiency.
Deci’s AutoNAC neural architecture search technology is pivotal in YOLO-NAS’s remarkable speed and accuracy. This model stands out in the market by offering an optimal trade-off between accuracy and latency, capable of being quantized and seamlessly deployed with TensorRT for production use.
Are you interested in using YOLO-NAS or Deci’s other foundation models for a commercial application?
Talk with our team about the commercial license.
Resources for Further Exploration








