If you’ve been training deep learning models, whether for research or production, you probably heard about the many techniques out there that can help improve your model’s performance. When it comes to computer vision models, there are loads of tips and tricks in various papers that explain how to train your model for better object detection, image classification, and image segmentation. But who has time to track down every trick in the different papers published, try them out, and find the ones that really work? Well… that’s just about what we did at Deci.
At Deci, because our goal is to improve deep learning and make it more accessible to DL practitioners everywhere, we’ve trained loads of models across every task and every hardware. We’re super-experienced in seeking out the best models, optimization methods, and tips that make life easier. Based on our experience in-house and with partners like Intel and HP, our DL experts put together the ultimate collection of best practices in state-of-the-art model training.
This blog describes some of the top tips that are ‘must-haves’ when it comes to your model training recipe, and also explains how you can access the entire collection of tricks and models in our SuperGradients open-source package.
Are You Really Making the Most of Your Neural Network Training?
Choosing the best neural network training recipe for deep learning models is crucial but still remains tough to do well. A recent paper[1] demonstrated just how important the right training can be, when a few training tricks managed to boost ResNet50 to a top-1 accuracy of 80.4% on ImageNet-1K. (The original ResNet50 recipe reached 75.8% accuracy.) Gaining such a significant boost in performance just from changing the training recipe is pretty astonishing.
Tricks aside, when dealing with neural network training, there is no shortage of challenges that need to be overcome. For starters, choosing the architecture for a deep learning task usually involves a literature survey to find a model based on the latest state-of-the-art practices. Although there are automated algorithms targeted at finding the best hyperparameters for the architecture and its training, these techniques work better in theory than in practice. And, if there’s a significant change in data, it often means changing the model’s hyperparameters and training regime.
Once you choose the model, one of the main hurdles in training is its stability and convergence. Training a neural network often takes a substantial amount of time. For example, training EfficientNet B0 takes about 550 GPU hours on NVIDIA Ti2080. Because we don’t want to waste training time, it’s common practice to examine the model’s accuracy mid-training. When the neural network training output shows large variations in accuracy between consecutive epochs, this makes it tough to know whether your training is going “well” or should be aborted.
Another common issue is the fact that neural network training relies on gradient descent optimization steps. Once a local minima is reached, the optimization could converge to that solution, especially at a later stage of the training when the learning rate is low. This phenomenon might limit the optimization process, preventing the exploration of additional solutions/minimas.
With so many papers coming out every year offering new training enhancement techniques, it would require a Herculean effort to keep up with the latest innovations and implement them in your codebase. To overcome these challenges, we created SuperGradients, a neural network training package that is constantly being updated with the best recipes, the latest cutting-edge models, and the newest training techniques. SuperGradients makes it easier to keep your production models up-to-date and allows you to use the optimal research and practices for your computer vision tasks.
5 Top Tricks to Improve Neural Network Training
These are the top must-have items for your deep learning training bag of tricks. The way we see it, it’s worth trying them all out because they can only improve things and will definitely not cause any harm.
Trick #1: Exponential Moving Average – EMA
EMA is a method that increases the stability of a model’s convergence and helps it reach a better overall solution by preventing convergence to a local minima. To avoid drastic changes in the model’s weights during training, we create a copy of the current weights before updating the model’s weights. Then we update the weights to be the weighted average between the current weights and the post-optimization step weights as follows:

Example for such a decay function:
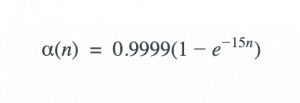
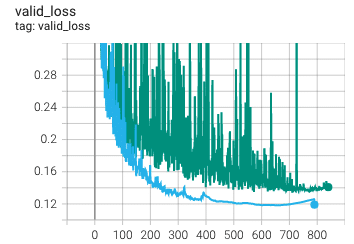
Adding EMA doesn’t change the weights learned as compared to non-EMA training, rather it saves an additional set of weights. At the end of the training, you can easily choose not to use the EMA learned weights if they don’t provide any benefit—although we usually find them quite helpful. For example, the validation loss plot below presents two identical trainings: one without EMA (green) and the other with EMA (teal). As you can see, the training with EMA is much more stable throughout the entire training process and converges to a better value.
Trick #2: Weight Averaging
Weight averaging is a post-training method that takes the best model weights across the training and averages them into a single model. By doing so we overcome the optimization tendency to alternate between adjacent local minimas in the later stages of the training. This trick doesn’t affect the training whatsoever, other than keeping a few additional weights on the disk, and can yield a substantial boost in performance and stability.
Trick #3: Batch Accumulation
When you use a model ‘off the shelf’, it generally comes with a suggested training recipe. The thing is, these models are usually trained on a very powerful GPU, which may mean the recipe is not necessarily appropriate for your target hardware. Reducing the batch size to accommodate your hardware will likely require tuning other parameters as well and you won’t always get the same training results. To overcome this issue, you can perform several consecutive forward steps over the model, accumulate the gradients, and backpropagate them once every few batches. This mechanism is known as batch accumulation.
Trick #4: Precise BatchNorm
BatchNorm layers are meant to normalize the data based on the dataset’s distribution. Ideally, we would like to estimate the distribution according to the entire dataset. Although this kind of estimation isn’t possible, we can use BatchNorm layers to evaluate the statistics of a given mini-batch throughout the training. The paper Rethinking “Batch” in BatchNorm[2] by Facebook AI Research, showed that these mini-batch based statistics are sub-optimal. Instead, the data statistics parameters (the mean and standard deviation variables) should be estimated across several mini-batches, while keeping the trainable parameters fixed. This method, titled Precise BatchNorm, helps improve both the stability and performance of a model.
Trick #5: Zero-weight Decay on BatchNorm and Bias
Any ‘go-to’ models for various computer vision tasks is likely to have batchnorm layers and biases added to their linear or convolution layers. When you’re training this kind of model, it works better if you set the optimizer’s weight decay to zero for the batch norm and bias weights. The weight decay is a regularization parameter that prevents the model weights from ‘exploding’. Zeroing the weight decay for these parameters is usually done by default in various projects and frameworks, but it’s still worth checking since we noticed that it’s still not the default behavior for Pytorch.
Weight decay essentially pulls the weights towards 0. While this is beneficial for convolutional and linear layer weights, Batchnorm layer parameters are meant to scale (the gamma parameter) and shift (the beta parameter) the normalized input of the layer. As such, forcing these values to a lower value would affect the distribution and result in inferior results.
SuperGradients – Your One-Stop Shop for the Latest in Deep Learning Training
SuperGradients is the new open-source training package released by Deci. It’s a one-stop shop for every computer vision task worth knowing, including classification, detection, and segmentation.
SuperGradients contains all the tricks listed above and more, so you can use it immediately to train deep learning models to their best possible accuracy and beyond.
What’s inside SuperGradients? The package contains many known models, which you can download pre-trained on the ImageNet dataset or train them from scratch. Aside from models, you get all the tricks mentioned above—and more—in a plug-and-play package that is easy to try out.
Try it now! – https://github.com/Deci-AI/super-gradients
References:
- Wightman, Ross, Hugo Touvron, and Hervé Jégou. “Resnet strikes back: An improved training procedure in timm.” arXiv preprint arXiv:2110.00476 (2021).
- Wu, Yuxin, and Justin Johnson. “Rethinking” Batch” in BatchNorm.” arXiv preprint arXiv:2105.07576 (2021).