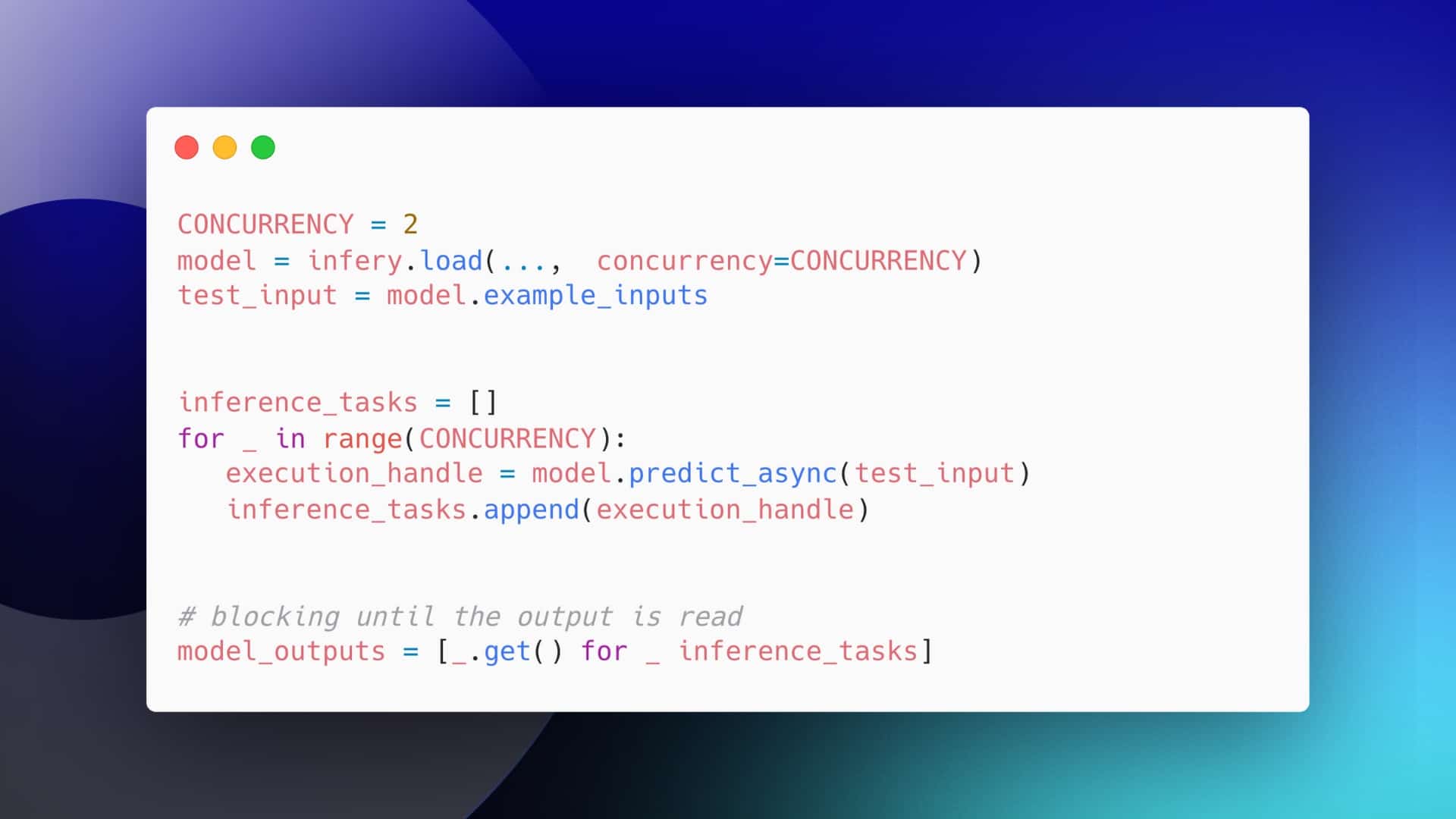
Deep learning inference is the phase in development where the capabilities learned during training is put to work. The trained deep neural networks (DNN) make predictions (or inferences) on new (or novel) data that the model has never seen before. When it comes to deployment, the trained DNN is often modified and simplified to meet real-world power and performance requirements.
Image classification, natural language processing, and most AI tasks can have large and complex models, resulting in huge compute, memory, energy usage, and eventually, poor latency. This is where deep learning optimization techniques such as pruning and quantization come in.