Introduction
Transformer-based text generation models have advanced significantly since the seminal Attention Is All You Need paper. Today’s models exhibit remarkable improvements in performance, compared to early examples such as GPT-1 and BERT. This leap in performance can be attributed to several key factors: the utilization of larger, better-curated datasets; enhanced training methodologies; significantly higher parameter count, more powerful hardware; and, crucially, groundbreaking architectural innovations such as Grouped Query Attention (GQA), SwiGLU, Rotary Position Embeddings, and (RoPE).
In this blog, we’ll explore these architectural advancements, providing insight into how they contribute to the superior performance and efficiency of today’s Transformer models.
Grouped Query Attention: Enhanced Balance Between Efficiency and Accuracy
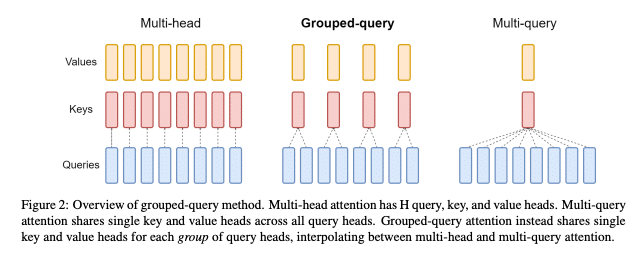
Grouped Query Attention (GQA) represents a significant advancement in attention mechanisms, addressing some of the efficiency issues inherent in the ‘Attention Is All You Need’ Transformer’s Multi-Head Attention (MHA). As detailed in the paper by Ainslie et al., GQA is an optimization technique that divides query heads into groups, each sharing a single key and value head. This approach reduces the computational and memory overhead compared to traditional MHA, allowing for faster inference times without a significant loss in quality. The paper presents a method for converting existing MHA models to GQA models with minimal additional training, demonstrating that GQA can achieve close to MHA quality with the speed benefits of Multi-Query Attention (MQA).
Multi-Head Checkpoints
An Overview of Grouped Query Attention
Developed by Joshua Ainslie and colleagues at Google Research, GQA is an evolution of the Multi-Query Attention (MQA) mechanism, designed to address its limitations and offer a balanced approach between computational efficiency and model performance.
Motivation: Memory Bandwidth and Key-Value Caching in MHA
The motivation behind GQA is rooted in the high memory bandwidth demands of MHA during inference. MHA, a cornerstone of Transformer models, operates by generating multiple sets of query, key, and value vectors for each input token. These vectors facilitate the attention mechanism’s ability to weigh the importance of different parts of the input data. However, this process becomes computationally expensive, primarily due to the necessity of key-value caching.
Key-value caching involves storing the computed key and value vectors for each token so that they can be reused across different decoding steps. This technique is crucial for enabling efficient sequential processing, particularly in autoregressive models where the output at each step depends on the previous outputs. Despite its benefits, key-value caching significantly increases the memory bandwidth requirement, as the model must continually load and update these caches at every decoding step. The memory overhead from loading these keys and values becomes a severe bottleneck, slowing down decoder inference and escalating computational costs.
MQA as a Precursor to GQA
MQA simplifies the attention mechanism by employing a single key and value head across multiple query heads, significantly reducing the memory bandwidth required for key-value caching. This approach, while effective in speeding up inference, can lead to quality degradation due to the reduced capacity for capturing complex patterns, as it diminishes the model’s ability to process diverse aspects of the input data in parallel.
GQA: An Efficient Alternative
GQA is ingeniously designed to circumvent the inefficiencies wrought by key-value caching in MHA and the quality compromise associated with MQA. By adopting an intermediate approach between MHA and MQA, GQA reduces the number of key-value pairs without diminishing the model’s capacity to capture complex data relationships. This reduction is achieved by dividing the query heads into groups, each sharing a single key and value head.
GQA’s Impact on Memory Bandwidth
The crux of GQA’s efficiency lies in its ability to maintain a lower number of key-value pairs across groups, while keeping a higher level of expressiveness than the single-headed MQA. This architectural decision directly addresses the memory bandwidth challenge by minimizing the volume of data that must be loaded and stored at each inference step.

To illustrate the different key-value caching memory requirements of MHA, MQA, and GQA models, consider a standard 7B transformer architecture. Usually, 7B models have 32 layers, 32 query heads, a hidden size of 4096, and a head dimension of 128. For an MHA model such as Llama 2 7B and a sequence of 1024 tokens, the KV cache amounts to 536 megabytes of memory for every single sequence in the batch. For a GQA model that uses 8 kv heads, such as Mistral-7B, the KV cache size drops by a factor of 4 to 134 MB per sequence. An MQA model of equivalent size would only use 16.75 MB per sequence, a fraction of the memory consumption of the original MHA model.
Experimental Validation and Implications
Experiments conducted to assess GQA’s efficacy underscore its capability to achieve near-MHA quality levels while markedly improving inference speed, akin to MQA. The approach demonstrates a substantial reduction in memory bandwidth usage without compromising the depth of language understanding, validated across various datasets and NLP tasks.

GQA Adoption and Impact on Model Performance
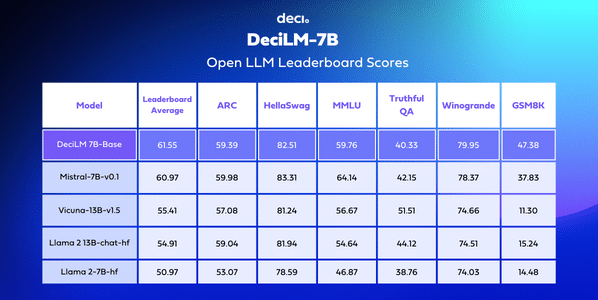
The integration of Grouped Query Attention (GQA) into transformer models such as Mistral-7B and DeciLM-7B has been a significant factor in their enhanced efficiency. Specifically, the application of GQA has allowed these models to achieve a superior speed-accuracy tradeoff than counterparts like Llama-2-7B, which employs MHA.
Variable Grouped Query Attention: Enhancing Transformer Efficiency with Layer-Specific Optimization
DeciLM takes GQA a step further, employing an advanced version of GQA called Variable GQA, where the number of kv heads per layer is not fixed. DeciLM, while maintaining a consistent number of query heads per layer (32), introduces variability in the GQA grouping across different layers. This means some layers may operate similarly to MQA with a single group, while others use multiple groups, optimizing the attention mechanism according to the specific needs of each layer. This layer-specific variation allows DeciLM-7B to achieve an optimal speed-accuracy balance.
Deci’s neural architecture search engine, AutoNAC, was used to determine the optimal configuration of the GQA group parameters across each transformer layer, with the object of maximizing inference speed while minimizing performance degradation.
SwiGLU: An Enhanced Activation Function for Better Performance
SwiGLU, short for Sigmoid-Weighted Linear Unit, is an activation function that aims to improve upon the GELU (Gaussian Error Linear Unit) used in the original ‘Attention Is All You Need’ Transformer model. The primary advantage of SwiGLU is its ability to dynamically adjust the non-linearity applied to different parts of the model input, depending on the task at hand. This adaptability results in models that can better capture complex patterns in data, leading to improved performance across a variety of NLP tasks. SwiGLU’s effectiveness is particularly notable in deep learning models where the interaction between nonlinearities and the model’s capacity is crucial for capturing subtle linguistic nuances.

On the left, the modified FFN layer with SwiGLU
A Technical Overview of SwiGLU
SwiGLU was introduced by Noam Shazeer in the paper GLU Variants Improve Transformer as a variant of Gated Linear Units (GLU) for improving the Transformer model’s performance.
Gated Linear Units (GLU) and Their Importance
GLUs are a type of neural network layer that apply a gating mechanism to linear transformations of the input. The original GLU formula is given by:
GLU(x,W,V,b,c)=σ(xW+b)⊙(xV+c)
Where x is the input, W and V are weight matrices, b and c are bias vectors, σ is the sigmoid function, and ⊙ denotes element-wise multiplication. This mechanism allows the model to control the flow of information through the network, which can lead to more expressive and flexible models.
Introduction to SwiGLU
SwiGLU is introduced as a variant of GLU that utilizes the Swish activation function (AKA SiLU) in place of the traditional sigmoid. The Swish function is defined as
Swishβ (x)=xσ(βx), where β is a parameter that could be learned or fixed. In the context of SwiGLU, the formula becomes:
SwiGLU(x,W,V,b,c,β)=Swishβ(xW+b)⊙(xV+c)
Implementation in Transformer Models
The Transformer model, which involves position-wise feed-forward networks (FFN), traditionally employs ReLU or GELU activation functions in its FFN layers. In the paper “GLU Variants Improve Transformer”, Noam Shazeer proposes replacing the first linear transformation and activation function in these FFN layers with GLU variants, including SwiGLU. The modified FFN layer with SwiGLU is defined as:
FFNSwiGLU(x,W,V,W2)=(Swish1(xW)⊙xV)W2
To maintain a constant number of parameters and computation, the paper suggests adjusting the size of the hidden layer when comparing these GLU-variant layers to the original two-matrix FFN configuration.
Experimental Results
The experiments conducted in the paper demonstrate the efficacy of SwiGLU and other GLU variants in improving model performance. Using the T5 model architecture, models incorporating SwiGLU were found to yield lower perplexity scores. (For language models, lower perplexity means the model is more certain about its predictions, which generally corresponds to better performance). Additionally, models incorporating SwiGLU were also shown to perform better on a wide array of downstream language understanding tasks, including SQuAD, GLUE and SuperGLUE.

SwiGLU Adoption
SwiGLU has been integrated into prominent models such as PaLM, followed by its implementation in LLaMA, Llama 2, and Mistral-7B. It has emerged as the de facto standard used in the majority of newly developed open-source LLMs.
Rotary Position Embeddings (RoPE): A Spatial Encoding Technique
Introduced in RoFormer: Enhanced Transformer with Rotary Position Embedding, RoPE is a novel way of incorporating positional information into Transformer models. Unlike the original, ‘Attention Is All You Need’ positional embeddings that add vector representations of positions to token embeddings, RoPE encodes positional information directly into the attention mechanism. This is achieved by rotating the embedding space in a way that the relative position information is preserved and explicitly encoded into the model’s attention calculations. The primary advantage of RoPE is its ability to capture long-range dependencies more effectively, as it maintains the contextual relationship between tokens regardless of their position in the input sequence. This results in improved model performance, especially in tasks requiring an understanding of complex sentence structures or long documents.
RoPE incorporates positional information into Transformer-based models by leveraging the mathematical properties of rotation matrices. This approach marks a departure from traditional methods of positional encoding, which typically involve adding or concatenating positional vectors to token embeddings. RoPE, instead, mathematically encodes the position by directly modulating the keys and queries in a way that naturally incorporates relative position information into the attention mechanism.

Mathematical Foundation of RoPE
The essence of RoPE lies in its use of rotation matrices to encode positional information. In a two-dimensional space, a rotation matrix can be represented as:

Where θ is the rotation angle, which in the case of RoPE is a function of the token’s position in the sequence. This concept is extended to higher dimensions by applying rotations in 2D planes within the high-dimensional embedding space, effectively encoding each token’s absolute position through a series of rotations.
Integration into Self-Attention
The self-attention mechanism of Transformers computes the attention score between pairs of tokens based on their embeddings. RoPE modifies this computation by first applying the rotation matrix to the embeddings, which are then fed into the self-attention mechanism. This process can be formalized for a token at position i with embedding xi
as:
qi=R(θi)WQxi
ki=R(θi)WKxi
Where WQ and WK are the query and key projection matrices of the self-attention mechanism, and R(θi) is the rotation matrix corresponding to position i. The attention scores are then computed using these rotated embeddings. This allows the model to implicitly capture relative positional relationships; when qm and kn are multiplied, their rotation matrices are also multiplied, resulting in a new rotation matrix that is only dependent on their relative position (and not their absolute positions). This is a general property of rotations: rotating in θ degrees and then rotating in φ degrees in the other direction is the same as rotating in θ-φ degrees. Equation 16 in RoFormer: Enhanced Transformer with Rotary Position Embedding illustrates this:

Theoretical and Practical Advantages
- Implicit Relative Position Encoding: By rotating embeddings based on position, RoPE naturally encodes the relative positions of tokens within the self-attention mechanism. This is because the rotation angle differences directly correlate with the relative distances between tokens, allowing the model to understand which tokens are closer or farther apart in the sequence.
- Compatibility with Linear Attention: RoPE’s method of encoding position through rotation does not increase the computational complexity of the self-attention mechanism. This makes it particularly suitable for integration with linear attention variants, which aim to reduce the quadratic complexity of standard self-attention with respect to sequence length.
- Scalability to Longer Sequences: The efficiency of RoPE in encoding positional information without significantly increasing computational demands allows Transformer models to scale to longer sequences more effectively. This is crucial for tasks involving lengthy texts, where understanding long-range dependencies is key to model performance.
Experimental Results
RoPE’s effectiveness is empirically validated across a wide range of NLP tasks, demonstrating that Transformers equipped with RoPE (RoFormer) consistently outperform those using traditional positional encodings. For instance, in machine translation tasks such as the WMT 2014 English-to-German translation, RoFormer achieved a BLEU score improvement. In pre-training language modeling on datasets like Enwik8, RoFormer exhibited faster convergence and a reduction in training loss, indicating a more efficient contextual understanding. Further, when fine-tuned on the GLUE benchmark, RoFormer showed notable improvements in performance across various tasks.
Adoption of RoPE:
RoPE has been widely adopted in practically all open-source LLMs, including Llama, Llama2, PaLM, Mistral, and DeciLM. This adoption signifies RoPE’s effectiveness in improving the model’s understanding of sequence order and inter-token relationships through a more nuanced positional encoding technique.
Today’s Transformers: Beyond “Attention Is All You Need”
Today’s transformer models surpass the original “Attention Is All You Need” Transformer by a mile. Besides larger model sizes, more compute, and larger training datasets of higher quality, three architecture innovations played a key role in the transformer revolution: SwiGLU, RoPE, and GQA. SwiGLU introduces a dynamic activation function that improves pattern recognition. RoPE revolutionizes positional encoding, enhancing the model’s understanding of sequence and context. GQA optimizes the attention mechanism, reducing computational overhead while maintaining attention quality. DeciLM’s variable GQA further tailors attention efficiency at a layer-specific level, optimizing for both speed and accuracy.
These advancements have been shown to improve performance across numerous benchmarks, demonstrating their superiority over earlier models. The adoption of these innovations by leading models highlights their effectiveness and the significant progress they represent in natural language processing technology. In essence, today’s Transformer models are more effective and adaptable due to these architectural innovations.
If you’re interested in exploring Deci’s AutoNAC-generated LLMs, we encourage you to sign up for a free trial of our API. For those curious about our VPC and on-premises deployment options, we encourage you to book a 1:1 session with our experts.