Introduction
In an era marked by large language models (LLMs), we’re seeing a surge in efforts to make the fine-tuning process of these models more efficient.
An evolution from its predecessor, LLaMA, Meta’s Llama 2 is a family of large language models with variants scaling up to 70 billion parameters. It boasts an augmented context length and the innovative introduction of Grouped Query Attention (GQA), which enhances the model’s inference scalability.
This guide will walk you through the process of fine-tuning Llama 2 with LoRA for Question Answering tasks.
Why Use Llama 2
Before delving into our step-by-step guide, let’s briefly review the advantages of Llama 2.
Variety in Scale: Llama 2 is available in multiple sizes, ranging from 7B to massive 70B parameters. An architecture reminiscent of Llama 1, the model includes enhanced capabilities.
Significant Enhancements:
Training Corpus: Trained on a massive 2 trillion tokens, this model is no slouch when it comes to the breadth of data it’s been exposed to.
With an increased context length of 4K, the model can grasp and generate extensive content.
Grouped Query Attention (GQA): Adopted to improve inference scalability, GQA accelerates attention computation by caching previous token pairs.
Performance: Llama 2 models have consistently outperformed their predecessors. This model shines in various benchmarks, standing tall against competitors like Llama 1 65B and even Falcon models.
Open Versus Closed-source LLMs: When matched against the likes of GPT-3.5 or PaLM (540B), Llama 2 70B showcases commendable performance. Although there exists a slight gap in certain benchmarks against GPT-4 and PaLM-2-L, the model’s potential is clear.
Unpacking LoRA Technique
Parameter-Efficient Fine-Tuning (PEFT)
Parameter-efficient fine-tuning is about adapting pre-trained models to new tasks with the least changes possible to the model’s parameters. It’s especially vital for mammoth neural network models like BERT, GPT, and their kin. Let’s explore why PEFT is crucial:
- Reduced Overfitting: Limited datasets can spell trouble. Modifying too many parameters might cause the model to overfit. PEFT allows us to balance a model’s versatility while tailoring it to new tasks.
- Swift Training: Fewer parameter tweaks mean fewer calculations, which translates to speedier training sessions.
- Resource Heavy: Deep neural training is a resource intensive. PEFT minimizes the computational and memory burden, making deployments in resource-tight scenarios more practical.
- Preserving Knowledge: Extensive pre-training on broad datasets packs models with invaluable general knowledge. With PEFT, we ensure that this treasure trove isn’t lost when adapting the model to novel tasks.
LoRA, or Low Rank Adaptation, is a revolutionary breakthrough in the world of large language models. At the start of the year, these models seemed like exclusive luxury items for millionaire companies. But LoRA has changed the game.
LoRA has democratized the use of large language models. Its approach to low-rank adaptation has drastically reduced the trainable parameters by up to 10,000 times. This leads to:
A three-fold reduction in GPU requirements – typically the major bottleneck.
Comparable, if not better, performance even when not fine-tuning the entire model.
When fine-tuning, we modify a pre-trained model’s existing weights using new examples. Traditionally, this needed a matrix of the same size. However, with some creativity and the concept of rank factorization, a matrix can be split into two smaller ones. When multiplied, they approximate the original matrix.
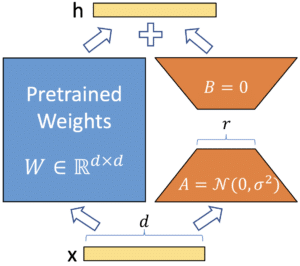
To visualize, consider a 1000×1000 matrix equating to 1,000,000 parameters. With rank factorization, if the rank is, say, five, we could have two matrices, both 1000×5. Combined, they represent just 10,000 parameters – a massive drop.
Fine-tuning Llama 2 with LoRA
Google Colab Notebook: The preferred environment for our guide. It provides a Python environment and free GPU access. Make sure to select a GPU runtime!
Python Setup: A working Python environment, preferably version 3.9 or newer.
GPU Allocation: Ensure you have abundant GPU resources, utilizing CUDA for an enhanced experience.
For a comprehensive walkthrough with code, refer to our dedicated Google Colab notebook.
Access to Google Colab (preferably with high RAM and T4 GPU)
Setting the stage: Prerequisites and environment setup
Here, we install all required Python libraries and modules. They help with training efficiency (accelerate), allow for low-rank adaptations (peft), facilitate quantized training (bitsandbytes), and give access to pre-trained models and tools (transformers, trl).
!pip install -q accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7 import os, torch, logging from datasets import load_dataset from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, HfArgumentParser, TrainingArguments, pipeline from peft import LoraConfig, PeftModel from trl import SFTTrainer
This is a subset of the widely recognized timdettmers/openassistant-guanaco dataset and contains 1,000 samples. It’s processed to be compatible with Llama 2’s prompt format.
These samples are specially processed to align seamlessly with Llama 2’s prompt format, ensuring that they are directly usable for training without further modifications.
Given that this subset is already processed for Llama 2’s prompt format, it can be directly used to train the model for specific applications. This could be for creating chatbots, virtual assistants, or any other application that requires understanding and generating language in the style of the timdettmers/openassistant-guanaco dataset.
Variation: Consider trying out other conversational datasets available on Hugging Face’s datasets repository to train the model on various dialogue styles. The Abirate/english_quotes dataset from Hugging Face consists of quotes from Goodreads.
Setting up the Model and Tokenizer
We specify the pre-trained Llama 2 model and prepare for its enhanced version, llama-2-7b-mlabonne-enhanced (you can name it anything). The tokenizer is loaded and slightly tweaked to ensure compatibility with fp16 operations. Working with half-precision floating-point numbers (fp16) can provide several benefits, such as reducing memory consumption and speeding up model training. However, not all operations are compatible with this reduced precision format right out of the box. This includes tokenization, which is a critical step in preparing text data for model training.
The pre-trained Llama 2 model is loaded with our quantization configurations. We then disable caching and set a pretraining temperature parameter.
To reduce the model size and increase inference speed, we use a 4-bit quantization provided by the BitsAndBytesConfig. Quantizing the model means representing its weights in a way that uses less memory.
The configuration here uses the ‘nf4’ type for quantization. Experiment with different quantization types to see potential performance variations.
# Dataset
data_name = "mlabonne/guanaco-llama2-1k"
training_data = load_dataset(data_name, split="train")
# Model and tokenizer names
base_model_name = "NousResearch/Llama-2-7b-chat-hf"
refined_model = "llama-2-7b-mlabonne-enhanced"
# Tokenizer
llama_tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
llama_tokenizer.pad_token = llama_tokenizer.eos_token
llama_tokenizer.padding_side = "right" # Fix for fp16
# Quantization Config
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=False
)
# Model
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
quantization_config=quant_config,
device_map={"": 0}
)
base_model.config.use_cache = False
base_model.config.pretraining_tp = 1
Quantization Configurations
In the context of training a machine learning model using LoRA (Low-Rank Adaptation), several parameters come into play. Here’s a simplified explanation for each:
LoRA-Specific Parameters
- Dropout Rate (lora_dropout): This is the probability that each neuron’s output is set to zero during training, used to prevent overfitting.
- Rank (r): Rank is essentially a measure of how the original weight matrices are broken down into simpler, smaller matrices. This reduces computational requirements and memory consumption. Lower ranks make the model faster but might sacrifice performance. The original LoRA paper suggests starting with a rank of 8, but for QLoRA, a rank of 64 is required.
- lora_alpha: This parameter controls the scaling of the low-rank approximation. It’s like a balancing act between the original model and the low-rank approximation. Higher values might make the approximation more influential in the fine-tuning process, affecting both performance and computational cost.
By tweaking these parameters, especially lora_alpha and r, you can observe how the model’s performance and resource consumption change, helping you find the optimal setup for your specific task.
# LoRA Config
peft_parameters = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=8,
bias="none",
task_type="CAUSAL_LM"
)
# Training Params
train_params = TrainingArguments(
output_dir="./results_modified",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant"
)
# Trainer
fine_tuning = SFTTrainer(
model=base_model,
train_dataset=training_data,
peft_config=peft_parameters,
dataset_text_field="text",
tokenizer=llama_tokenizer,
args=train_params
)
# Training
fine_tuning.train()
# Save Model
fine_tuning.model.save_pretrained(refined_model)
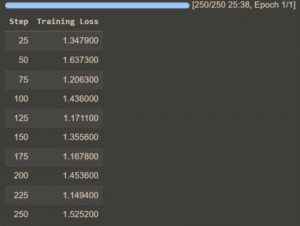
The model is trained using the SFTTrainer, which is specifically designed for this kind of task. After defining the trainer, the training process begins.
# Generate Text
query = "How do I use the OpenAI API?"
text_gen = pipeline(task="text-generation", model=refined_model, tokenizer=llama_tokenizer, max_length=200)
output = text_gen(f"<s>[INST] {query} [/INST]")
print(output[0]['generated_text'])
After training, we save the refined model. We then showcase the model’s capabilities by generating a response to the query “How do I use the OpenAI API?”.
For a comprehensive walkthrough with code, refer to our dedicated Google Colab notebook.
Benefits in Action
The training process of Llama 2 is quite extensive; it’s trained on a massive 2 trillion tokens of data. This immense training has endowed the model with an enhanced context length of 4,000 tokens. What’s more? The introduction of Ghost Attention (GAtt). The Ghost Attention (GAtt) method improves a model’s ability to maintain dialogue flow across multiple turns. For example, if the model is instructed to respond using only emojis, GAtt ensures that it remembers this instruction throughout the conversation, unlike without GAtt where the model might forget by the second message.
Fine-tuning is pivotal in harnessing the full potential of LLMs. While pre-training lays the foundation by enabling the model to learn from vast corpora of text, fine-tuning sharpens the model for specific tasks. Llama 2’s fine-tuning process incorporates Supervised Fine-Tuning (SFT) and a combination of alignment techniques, including Reinforcement Learning with Human Feedback (RLHF). This rigorous process involves presenting the model with specific prompts and refining its responses, ensuring that it aligns with human preferences and safety measures.
Fine-tuning is indispensable when we aim to extract the most from Large Language Models (LLMs) like Llama 2. While initial pre-training stages provide a broad knowledge base, derived from extensive text corpora, it’s the fine-tuning that tailors the model for specialized tasks. In our experiment, rather than adopting the usual Supervised Fine-Tuning (SFT) or Reinforcement Learning with Human Feedback (RLHF), we leveraged the power of Low-Rank Adaptation (LoRA).
The Advantages of Using LoRA for Fine-Tuning:
- Efficiency: LoRA reduces trainable parameters, saving memory and costs.
- Performance: Despite fewer parameters, we achieved comparable, if not superior, results.
- Scalability: LoRA’s rank factorization makes big models like Llama 2 manageable even on constrained setups.
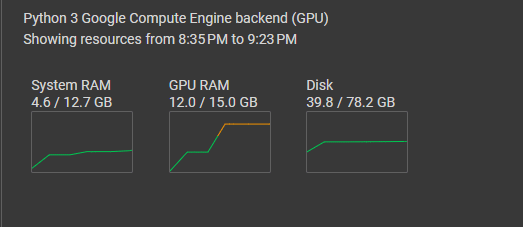
Using LoRA on Google Colab with a T4 GPU, we experienced efficient training sessions, reducing the expected durations seen with traditional methods.
Our GPU memory utilization peaked at just 12GB. This efficiency meant smoother training without the typical out-of-memory issues.
For a comprehensive walkthrough, including code demonstrations, delve into our dedicated Google Colab notebook.
And Now… Deployment
While the use of LoRA streamlines the fine-tuning of large language models like Llama 2, challenges remain in managing inference latency, throughput, and cost.
The complex computations required by LLMs can result in high latency, adversely affecting the user experience, particularly in real-time applications. Additionally, a crucial challenge is managing low throughput, which leads to slower response times and difficulties in processing multiple user requests simultaneously. This often requires more expensive, high-performance hardware to enhance throughput, increasing operational costs. Therefore, the need to invest in such hardware adds to the inherent computational expenses of deploying these models.
Deci’s Infery-LLM addresses these issues effectively. This Inference SDK boosts LLM performance, offering up to five times higher throughput while maintaining accuracy. Significantly, it optimizes computational resource use, allowing for the deployment of larger models on cost-effective GPUs, which lowers operational costs.
When combined with Deci’s open-source models, such as DeciCoder or DeciLM-7B, the efficiency of Infery-LLM is notably increased. These highly accurate and efficient models integrate smoothly with the SDK, boosting its effectiveness in reducing latency and cutting down costs.
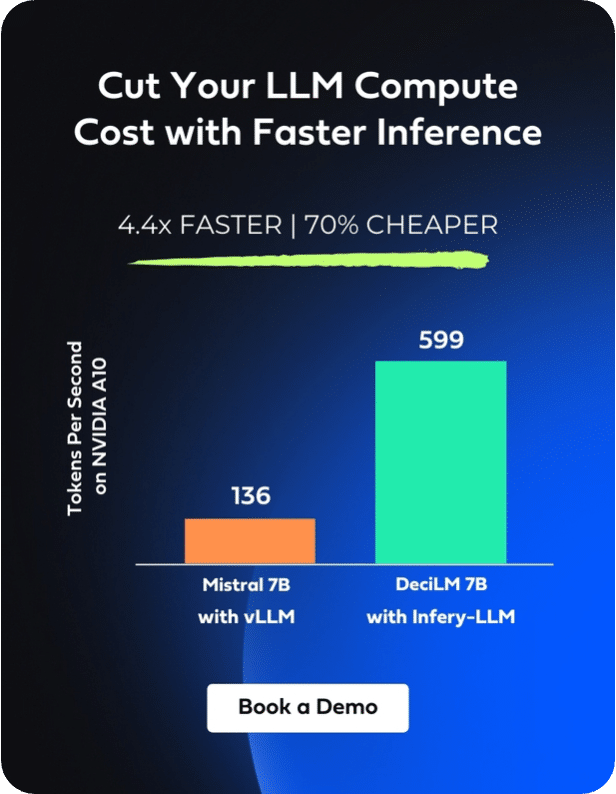
Enabling inference with just three lines of code, Infery-LLM makes it easy to deploy into production and into any environment. Its optimizations unlock the true potential of LLMs, as exemplified when it runs DeciLM-7B, achieving 4.4x the speed of Mistral 7B with vLLM with a 64% reduction in inference costs.
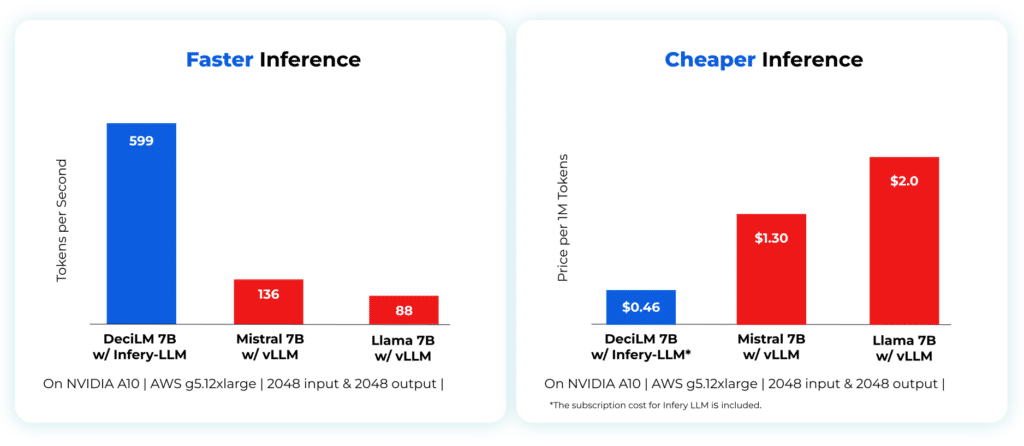
Infery’s approach to optimizing LLMs enables significant performance improvements on less powerful hardware, as compared to other approaches on vLLM or PyTorch even on high-end GPUs, significantly reducing the overall cost of ownership and operation. This shift not only makes LLMs more accessible to a broader range of users but also opens up new possibilities for applications with resource constraints.

In conclusion, Infery-LLM is essential for overcoming the challenges of latency, throughput, and cost in deploying LLMs, becoming an invaluable asset for developers and organizations utilizing these advanced models.
To experience the full capabilities of Infery-LLM, we invite you to get started today.