Introduction
At Deci AI, we’ve been on a roll this year, unveiling a series of groundbreaking models that have not only pushed the boundaries of what’s possible in AI but have also been generously made available to the community. As open models with permissive licenses, they stand as a testament to our commitment to fostering innovation and creativity in the AI space. As someone who takes immense pride in being a part of the Deci AI family, I felt a surge of inspiration to celebrate our achievements in a unique way. Rather than just showcasing each model in isolation, I embarked on a creative exploration to weave together three of our most popular models into a single, cohesive project. The idea? To use our object detection model‘s output as a springboard for our Language Model, DeciLM-6B-Instruct, to craft captivating one-sentence stories. These stories would then serve as a diffusion prompts for our diffusion model, culminating in a visually stunning image generation.
To say the journey was exciting would be an understatement. The thrill of conceptualizing a project that seamlessly integrated all three models was only surpassed by the sheer joy of witnessing the models exceed my expectations. The prowess of DeciLM-6B-Instruct, in particular, left me in awe, as it adeptly followed my prompts, crafting narratives that were both concise and evocative. Crafting the perfect prompt was a challenge in itself, and I owe a nod to ChatGPT for assisting me in understanding the essence of impactful one-sentence stories and effective diffusion model prompts.
But beyond the technical marvels and the cool generations, this project underscored something profound: the power of openness in AI. By making our models accessible to all, we’re not just sharing technology; we’re inviting the world to dream, experiment, and create. And as you delve deeper into this post, I hope to inspire those of you passionate about Generative AI to see the limitless possibilities that lie ahead.
Setting Up
%%capture !pip install super-gradients diffusers --upgrade invisible_watermark transformers accelerate safetensors wget
# @title %%capture import numpy as np import torch from typing import Dict from collections import Counter from super_gradients.training import models from diffusers import StableDiffusionPipeline from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, TextIteratorStreamer from tqdm.notebook import tqdm from IPython.display import display from matplotlib import pyplot as plt import time from IPython.core.display import display, HTML from google.colab import files import wget
Run the Cell Below to Upload Pictures
# @title
# Ask the user for their preference
choice = input("Do you want to (1) Upload an image or (2) Enter a URL? Enter the number of your choice: ")
if choice == "1":
# User chooses to upload an image
uploaded = files.upload()
# Check if any file was uploaded
if uploaded:
# Extract the filename
filename = list(uploaded.keys())[0]
# Assign the filename to the variable "picture"
picture = filename
print("Uploaded file:", picture)
else:
print("No file was uploaded.")
elif choice == "2":
# User chooses to enter a URL
url = input("Enter the image URL: ")
# Download the image using wget
picture = wget.download(url)
print("Downloaded file from URL:", picture)
else:
print("Invalid choice.")
Result:
Do you want to (1) Upload an image or (2) Enter a URL? Enter the number of your choice: 2 Enter the image URL: https://i.redd.it/1cso7yshi3291.jpg Downloaded file from URL: 1cso7yshi3291 (2).jpg
Download Models
This could take a few minutes…
# @title
# Define a custom function to display a tqdm progress bar for each download
def with_progress_bar(download_function, description, *args, **kwargs):
with tqdm(total=1, desc=description) as pbar:
result = download_function(*args, **kwargs)
pbar.update(1)
return result
# Model names
llm_name = 'Deci/DeciLM-6b-instruct'
diffusion_model = 'Deci/DeciDiffusion-v1-0'
detection_model = "yolo_nas_l"
# Download yolo-nas with progress
detector = with_progress_bar(models.get, "Downloading yolo-nas", detection_model, pretrained_weights="coco")
# Download llm with progress
llm = with_progress_bar(AutoModelForCausalLM.from_pretrained, "Downloading llm", llm_name, device_map="auto", trust_remote_code=True)
# Set tokenizer
tokenizer = AutoTokenizer.from_pretrained(llm_name)
tokenizer.pad_token = tokenizer.eos_token
# Download decidiffusion model with progress
deci_diffusion_pipeline = with_progress_bar(StableDiffusionPipeline.from_pretrained, "Downloading decidiffusion model", diffusion_model, custom_pipeline=diffusion_model, torch_dtype=torch.float16)
# Download unet for decidiffusion with progress
deci_diffusion_pipeline.unet = with_progress_bar(deci_diffusion_pipeline.unet.from_pretrained, "Downloading unet for decidiffusion", diffusion_model, subfolder='flexible_unet', torch_dtype=torch.float16)
# Move to CUDA
deci_diffusion_pipeline = deci_diffusion_pipeline.to('cuda')
Result:

Helper Functions
# @title
one_sentence_story = """
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
You are an excellent one-sentence story writer. Given the contents of an image, you can write a good one-sentence story.
These are the qaualities of a good one-sentence story:
• The story used the names of famous celebrities instead of vague nouns (e.g., "Keanu Reeves" instead of "a man", "Jennifer Aniston" instead of "a woman")
• The story should evoke strong emotions, whether it's happiness, sadness, surprise, anger, or any other feeling.
• It should be brief, getting straight to the point without unnecessary words.
• Even in its brevity, the story should have a clear beginning, middle, and end or convey a complete thought or idea.
• The story should resonate with the reader, making them feel connected or empathetic.
• A good one-sentence story should stimulate thoughts, memories, or images in the reader's mind.
• Many of the stories touch on universal human experiences, such as love, loss, hope, betrayal, and more.
• Clear Message: Despite its brevity, the story should convey a clear message or insight.
Examples of one-sentence stories:
• "In the silence of the empty house, the old clock's ticking became a symphony of memories."
• "Priyanka Chopra wore her grandmother's locket every day, not for the photo inside, but for the scent of old letters it held."
• "After years of chasing sunsets around the world, he found the most breathtaking view was in his backyard with her."
• "The last message on Dijit Dosanjh's phone read, 'See you soon,' but the airport remained eerily silent."
• "Idris Elba's favorite book was filled not with annotations, but with the pressed flowers from every place they'd been together."
Contents of the image: {instruction}
### Response:
"""
diffusion_prompt = """
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
You are an excellent Stable diffusion prompt writer. Given a one-sentence story, you can write a Stable diffusion prompt.
Instructions for writing a Stable diffusion prompt with a one-sentence story:
• Use specific descriptors based on the one-sentence story details (e.g., "dense pine forest" instead of "forest").
• Detail objects mentioned in the one-sentence story (e.g., "ancient leather-bound book" instead of "book").
• Highlight emotions conveyed in the one-sentence story (e.g., "melancholic," "joyful").
• Choose a visual style, such as "35mm film," "cinematic," "watercolor", "oil painting", "3D art".
• Reference an artist or artistic style that aligns with the one-sentence story vibe.
Examples of Stable diffusion prompts:
• "Macie Grey in a Victorian dress, exploring a luminous garden with glowing plants and mystical creatures, rendered in a dreamy watercolor style with soft pastel hues."
• "Mark Hamel as an astronaut in a futuristic suit, examining an ancient monolith amidst ruins on an alien planet, captured with a 35mm film grain effect and a surreal, otherworldly color palette."
• "Baby shark with a painted face on an old wall, in the style of hyper-realistic sculptures, fragmented figures, distressed materials, tiled walls of light grays, cracked, rococo—inspired art"
• "Award-winning cinematic bioluminescent oil creature design in gold, vibrant holographic gradient blue and silver colored scheme, in the style 3d hydro — drip venom character, ray tracing reflection, prismatic lighting, realistic texture detail, vibrant electric flames coursing through oil"
• "Pope Francis wearing leather jacket is a DJ in a nightclub, mixing live on stage, giant mixing table, 4k resolution, a masterpiece"
• "Kanye West in medieval armor, standing on a cliff's edge, watching a dragon soar from misty mountains, depicted in a Renaissance painting style with dramatic chiaroscuro lighting."
• "A trench-coated Dick Tracy, silhouette against neon noir streets, searching for elusive clues of a jewel thief, visualized in a vibrant neon noir style with rain-soaked streets reflecting the city's lights."
One-sentence story: {instruction}
### Response:
"""
def describe_counts(counts_dict):
items = []
for key, value in counts_dict.items():
if value == 1:
items.append(f"{value} {key}")
else:
# Handling plural forms
if key.endswith("s"):
items.append(f"{value} {key}")
else:
items.append(f"{value} {key}s")
if len(items) == 1:
return f"This image has {items[0]}."
last_item = items.pop()
return f"This image has {', '.join(items)}, and {last_item}."
# Function to construct the prompt using the new system prompt template
def get_prompt_with_template(message: str, system_prompt_template: str) -> str:
return system_prompt_template.format(instruction=message)
# Function to handle the generation of the model's response using the constructed prompt
def generate_model_response(message: str, system_prompt_template: str) -> str:
prompt = get_prompt_with_template(message, system_prompt_template)
inputs = tokenizer(prompt, return_tensors='pt')
if torch.cuda.is_available(): # Ensure input tensors are on the GPU if model is on GPU
inputs = inputs.to('cuda')
output = llm.generate(**inputs,
max_new_tokens=500,
temperature=0.1
)
return tokenizer.decode(output[0], skip_special_tokens=True)
# Function to extract the content after "### Response:"
def extract_response_content(full_response: str) -> str:
response_start_index = full_response.find("### Response:")
if response_start_index != -1:
return full_response[response_start_index + len("### Response:"):].strip()
else:
return full_response
# Main function to get the model's response and extract the content after "### Response:"
def get_response_with_template(message: str, system_prompt_template: str) -> str:
full_response = generate_model_response(message, system_prompt_template)
return extract_response_content(full_response)
def text_to_image(prompt, pipeline=deci_diffusion_pipeline):
# Start the timer
start_time = time.time()
# Call the pipeline function directly
result = pipeline([prompt], generator=torch.Generator("cuda").manual_seed(42))
# Calculate and print the elapsed time
elapsed_time = time.time() - start_time
display(HTML(f'<span style="color: #3264ff; font-weight:bold;font-size: 20px;">Time taken to generate: {elapsed_time:.2f} seconds</span>'))
img = result.images[0]
# Display the saved image
plt.imshow(img)
plt.axis('off')
plt.show()
Use YOLO-NAS to Detect What’s in the Image
The YOLO-NAS architecture is a testament to the evolution of object detection models. Stemming from the YOLO (You Only Look Once) family, which revolutionized object detection by treating it as a single regression problem, YOLO-NAS builds upon the strengths of its predecessors. The initial YOLO model divided images into a grid, predicting bounding boxes and class probabilities simultaneously. While efficient, early versions like YOLOv1 had challenges with detecting small objects and localization accuracy. Over time, the YOLO family expanded with versions like YOLOv6, YOLOv7, and YOLOv8, each pushing the boundaries of object detection.
YOLO-NAS, introduced by Deci, is a culmination of advancements in neural architecture search (NAS) and deep learning. Utilizing Deci’s proprietary NAS technology, AutoNAC, the architecture was optimized for both accuracy and latency. The model incorporates cutting-edge techniques such as attention mechanisms, quantization-aware blocks, and reparametrization at inference time. These innovations enable YOLO-NAS to detect objects of varying sizes and complexities with exceptional performance.
Once the YOLO-NAS model processes an image and provides object detections, the next step is to translate these detections into a human-readable sentence. For this, a simple Python function, describe_counts, was crafted:
def describe_counts(counts_dict):
items = []
for key, value in counts_dict.items():
if value == 1:
items.append(f"{value} {key}")
else:
# Handling plural forms
if key.endswith("s"):
items.append(f"{value} {key}")
else:
items.append(f"{value} {key}s")
if len(items) == 1:
return f"This image has {items[0]}."
last_item = items.pop()
return f"This image has {', '.join(items)}, and {last_item}."
This function takes in a dictionary of detected objects and their counts, then constructs a descriptive sentence about the contents of the image. The function handles singular and plural forms, ensuring the description is grammatically correct. For instance, if the model detects three cats and one dog, the function would output: “This image has 3 cats and 1 dog.”
# @title
predictions = detector.predict(picture, iou=.50, conf=.70)
model_class_names = predictions[0].class_names
labels = predictions[0].prediction.labels
# Count the occurrences of each unique label in the labels array
label_counts = Counter(labels)
# Create the desired dictionary by fetching class names using the label indices
class_counts = {model_class_names[int(label_index)]: count for label_index, count in label_counts.items()}
contents = describe_counts(class_counts)
print(contents)
Use DeciLM-6B-Instruct to Generate Stories and Diffusion Prompts
The deep learning community has been making significant strides in the development of Large Language Models (LLMs). However, the computational demands for training and inference of these models have been growing exponentially. Addressing this challenge, Deci introduced DeciLM 6B and its fine-tuned counterpart, DeciLM 6B-Instruct. With 5.7 billion parameters, DeciLM 6B boasts a throughput that’s 15 times higher than Llama 2 7B, setting a new benchmark for inference efficiency and speed. The model’s architecture, uniquely generated using Deci’s Neural Architecture Search engine, AutoNAC, is a testament to its efficiency.
Architectural Innovations
DeciLM’s architecture stands out due to its implementation of variable Grouped-Query Attention (GQA). Unlike other transformer models, DeciLM varies the number of attention groups, keys, and values across transformer layers. This variability allows DeciLM to optimize the balance between inference speed and output quality.
Variable Grouped-Query Attention: DeciLM introduces a unique approach to GQA. While maintaining 32 queries/heads per layer, the model varies its GQA group parameter. This layer-specific variation allows DeciLM to handle diverse attention patterns efficiently.
AutoNAC
The architecture of DeciLM was sculpted using Deci’s proprietary Neural Architecture Search (NAS) engine, AutoNAC. This engine automates the search process efficiently, playing a pivotal role in determining the optimal GQA group parameter for each transformer layer.
Training and Fine-tuning
DeciLM 6B was trained using a subset of the SlimPajamas dataset, an extensive deduplicated, multi-corpora open-source dataset. After its initial training, the model underwent LoRA fine-tuning, resulting in the instruction-following variant, DeciLM 6B-Instruct.
Performance Metrics
Benchmarking DeciLM 6B and DeciLM 6B-Instruct against leading models in the 7-billion parameter class revealed its prowess. Despite having fewer parameters, DeciLM 6B-Instruct consistently ranked among the top-performing LLMs in its category.
Crafting Effective Prompts: Knowledge Generation and Few-Shot Prompting
Knowledge Generation Prompting
Knowledge Generation Prompting is an advanced strategy in prompt engineering that aims to generate new insights or knowledge that the model was not explicitly trained on. Unlike traditional prompting, where the model mainly retrieves information from its training data, Knowledge Generation Prompting encourages the model to ‘create’ new knowledge. The AI model is directed to use its understanding of patterns, structures, and relationships within the training data to offer insights beyond the explicit content of the data. This method enhances the model’s usefulness, enabling it to generate insights or solutions that are not readily available in its training data source.
Knowledge Generation Prompting is a nuanced technique in prompt engineering that goes beyond mere information retrieval by pushing AI models to synthesize new insights tailored to specific tasks.
Few-Shot Prompting
Few-shot prompting is a technique that helps models generate relevant responses by providing them with one or more examples to guide their answers. This technique is particularly useful for complex tasks or those that require a specific format. The one-sentence story prompt also employs few-shot prompting by offering multiple examples of desired outputs. These examples serve as a guide, showing the model the structure and context of the task, and aiding in generating a relevant response.
When the model receives examples of how to properly continue a prompt, it can better understand the underlying structure of the task. For example, if you need a list of travel destinations based on certain keywords, you can provide the model with several examples of keywords and their corresponding travel destinations. This helps the model generate a more accurate response based on the structure and context provided by the examples.
Prime examples of these two techniques are the one-sentence story prompts and diffusion model prompts that I created.
one_sentence_story = """
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
You are an excellent one-sentence story writer. Given the contents of an image, you can write a good one-sentence story.
These are the qaualities of a good one-sentence story:
• The story used the names of famous celebrities instead of vague nouns (e.g., "Keanu Reeves" instead of "a man", "Jennifer Aniston" instead of "a woman")
• The story should evoke strong emotions, whether it's happiness, sadness, surprise, anger, or any other feeling.
• It should be brief, getting straight to the point without unnecessary words.
• Even in its brevity, the story should have a clear beginning, middle, and end or convey a complete thought or idea.
• The story should resonate with the reader, making them feel connected or empathetic.
• A good one-sentence story should stimulate thoughts, memories, or images in the reader's mind.
• Many of the stories touch on universal human experiences, such as love, loss, hope, betrayal, and more.
• Clear Message: Despite its brevity, the story should convey a clear message or insight.
Examples of one-sentence stories:
• "In the silence of the empty house, the old clock's ticking became a symphony of memories."
• "Priyanka Chopra wore her grandmother's locket every day, not for the photo inside, but for the scent of old letters it held."
• "After years of chasing sunsets around the world, he found the most breathtaking view was in his backyard with her."
• "The last message on Dijit Dosanjh's phone read, 'See you soon,' but the airport remained eerily silent."
• "Idris Elba's favorite book was filled not with annotations, but with the pressed flowers from every place they'd been together."
Contents of the image: {instruction}
### Response:
"""
This prompt exemplifies several key principles of Knowledge Generation and Few Shot Prompting:
- Task-Specific Guidance: The AI is given a clear directive to craft a one-sentence story based on an image’s contents.
- Demonstrations: By providing examples of one-sentence stories, the model is shown the desired format and quality of the output.
- Qualities of Desired Output: The prompt outlines specific criteria for a good one-sentence story, ensuring the AI’s generated content aligns with these standards.
- Integration of External Knowledge: The AI is expected to weave its understanding of the image’s contents into the story, showcasing its ability to merge external data with internal knowledge.
- Multiple Demonstrations: The prompt provides several examples of one-sentence stories, serving as “shots” to guide the AI on the desired structure, style, and content.
- Clear Task Definition: The prompt begins with a clear instruction, offering a comprehensive view of the assignment.
- Contextual Guidance: The qualities listed in the prompt provide additional context, ensuring the story aligns with specific criteria.
- Explicit Format: The “Instruction” and “Response” format helps the model understand the flow of the task.
- Integration of External Information: The placeholder {instruction} indicates the model should integrate external information into its response.
# @title story = get_response_with_template(contents, one_sentence_story)
story
Result:
A man races his motorcycle through the city, chasing the car that left him behind.
Use DeciLM-6B-Instruct to create diffusion prompts from stories
diffusion_prompt = """
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
You are an excellent Stable diffusion prompt writer. Given a one-sentence story, you can write a Stable diffusion prompt.
Instructions for writing a Stable diffusion prompt with a one-sentence story:
• Use specific descriptors based on the one-sentence story details (e.g., "dense pine forest" instead of "forest").
• Detail objects mentioned in the one-sentence story (e.g., "ancient leather-bound book" instead of "book").
• Highlight emotions conveyed in the one-sentence story (e.g., "melancholic," "joyful").
• Choose a visual style, such as "35mm film," "cinematic," "watercolor", "oil painting", "3D art".
• Reference an artist or artistic style that aligns with the one-sentence story vibe.
Examples of Stable diffusion prompts:
• "Macie Grey in a Victorian dress, exploring a luminous garden with glowing plants and mystical creatures, rendered in a dreamy watercolor style with soft pastel hues."
• "Mark Hamel as an astronaut in a futuristic suit, examining an ancient monolith amidst ruins on an alien planet, captured with a 35mm film grain effect and a surreal, otherworldly color palette."
• "Baby shark with a painted face on an old wall, in the style of hyper-realistic sculptures, fragmented figures, distressed materials, tiled walls of light grays, cracked, rococo—inspired art"
• "Award-winning cinematic bioluminescent oil creature design in gold, vibrant holographic gradient blue and silver colored scheme, in the style 3d hydro — drip venom character, ray tracing reflection, prismatic lighting, realistic texture detail, vibrant electric flames coursing through oil"
• "Pope Francis wearing leather jacket is a DJ in a nightclub, mixing live on stage, giant mixing table, 4k resolution, a masterpiece"
• "Kanye West in medieval armor, standing on a cliff's edge, watching a dragon soar from misty mountains, depicted in a Renaissance painting style with dramatic chiaroscuro lighting."
• "A trench-coated Dick Tracy, silhouette against neon noir streets, searching for elusive clues of a jewel thief, visualized in a vibrant neon noir style with rain-soaked streets reflecting the city's lights."
One-sentence story: {instruction}
### Response:
"""
# @title prompt = get_response_with_template(story, diffusion_prompt)
prompt
Result:
"A man races his motorcycle through the city, chasing the car that left him behind, captured in a hyper-realistic sculpture style with fragmented figures, distressed materials, and a surreal, otherworldly color palette."
Image Generation with DeciDiffusion:
Converting the Story into a Prompt
Once the one-sentence story was generated using DeciLM-6B-Instruct, it served as the foundation for the prompt that would guide the DeciDiffusion model. This prompt encapsulated the essence of the story, providing a clear and concise instruction for the image generation process.
The Process of Generating Images from Diffusion Prompts
DeciDiffusion is Deci’s groundbreaking text-to-image latent diffusion model. It’s designed to transform textual descriptions into vivid images, marking a significant leap in AI capabilities.
Here’s a deep dive into its workings:
Efficiency and Quality
DeciDiffusion boasts 1.02 billion parameters and achieves equal quality in 40% fewer iterations compared to its counterpart, Stable Diffusion v1.5. With the integration of Deci’s Inference SDK, Infery, DeciDiffusion is 3x faster than Stable Diffusion v1.5, producing high-quality images in under a second on NVIDIA A10G GPUs.
Architectural Innovations
At the heart of DeciDiffusion’s efficiency is its innovative architecture. Unlike Stable Diffusion, which uses a traditional U-Net component, DeciDiffusion employs a more streamlined variant called U-Net-NAS. This architecture was conceived by Deci and was optimized using Deci’s proprietary Neural Architecture Search engine, AutoNAC. The U-Net-NAS features fewer up and down blocks than the traditional U-Net, making it computationally more efficient.
Latent Diffusion Process
The latent diffusion process starts with a basic, noisy image representation in latent space. With textual guidance, the model refines this representation, gradually revealing a clearer image. This process involves three primary components:
Variational Autoencoder (VAE)
Transforms images into latent representations and vice versa.
U-Net
An iterative encoder-decoder mechanism that introduces and subsequently reduces noise in the latent images.
Text Encoder
Transforms textual prompts into latent text embeddings.
Training Techniques
DeciDiffusion was trained on a subset of the LAION dataset and was fine-tuned on the LAION-ART dataset. Specialized training techniques were employed to shorten the training time and achieve high-quality images in fewer iterations. Techniques such as using precomputed VAE and CLIP latents, and employing EMA only for the last phase of training, contributed to its efficiency.
Generating Images with Sharper Details
DeciDiffusion employs techniques to produce images with sharper details and diverse characteristics. By omitting certain steps during the reverse diffusion process, the model focuses on steps that have a more pronounced impact on the final image’s appearance and quality.
text_to_image(prompt)
Result:

Challenges and Solutions
1. Integrating Multiple Models:
- Challenge: One of the primary challenges was conceptualizing a meaningful project that could seamlessly integrate all three models: YOLO-NAS, DeciLM-6B-Instruct, and DeciDiffusion.
- Solution: The solution was a creative endeavor that used the object detection model to detect objects in an image, parse the detections into a sentence, generate a one-sentence story with DeciLM-6B-Instruct, and then use that story to craft a prompt for DeciDiffusion to generate an image.
2. Crafting Effective Prompts:
- Challenge: The biggest challenge was crafting a prompt that would guide the models, especially DeciLM-6B-Instruct, to produce the desired output.
- Solution: Assistance from ChatGPT was sought to research the qualities of good one-sentence stories. This research was then integrated into the prompt, ensuring that the generated stories were not only relevant but also resonated with readers. The same approach was taken for crafting prompts for the diffusion model.
3. Model Expectations:
- Challenge: There was an initial skepticism about how well the models, especially DeciLM-6B-Instruct, would perform given the intricate nature of the task.
- Solution: To the pleasant surprise, DeciLM-6B-Instruct excelled at following the prompts, showcasing its capability to understand and generate contextually relevant content.
4. Openness and Accessibility:
- Challenge: Ensuring that the broader AI community could replicate and experiment with the project.
- Solution: The open model approach adopted by Deci AI played a pivotal role. By allowing the community to freely download the models, it encouraged creative explorations and ensured that the project could be replicated and further enhanced by others.
Lessons Learned
- The Power of Open Models: The openness of models is crucial for fostering innovation and creativity in the AI community. It not only allows for replication but also encourages further exploration and experimentation.
- Importance of Prompt Engineering: Crafting effective prompts is both an art and a science. It’s essential to understand the model’s capabilities and guide it with clear, context-rich prompts to achieve the desired output.
- Collaborative Problem Solving: Leveraging multiple tools, like ChatGPT, can provide valuable insights and solutions to challenges faced during a project.
- Setting Realistic Expectations: While it’s essential to have high hopes from AI models, it’s equally crucial to set realistic expectations. However, with the right approach and guidance, models can often exceed these expectations.
For a comprehensive walkthrough, refer to our Google Colab notebook.
Final Thoughts: Overcoming Deployment Challenges
In this blog, we’ve primarily explored building an application that weaves together three different models. However, as we wrap up, it’s crucial to address deployment and the real-world challenges of inference cost, latency and throughput that it presents.
The complex computations required by LLMs can result in high latency, adversely affecting the user experience, particularly in real-time applications. Additionally, a crucial challenge is managing low throughput, which leads to slower response times and difficulties in processing multiple user requests simultaneously. This often requires the adoption of more expensive, high-performance hardware to enhance throughput, further increasing operational costs. Therefore, the need to invest in such hardware adds to the inherent computational expenses of deploying these models.
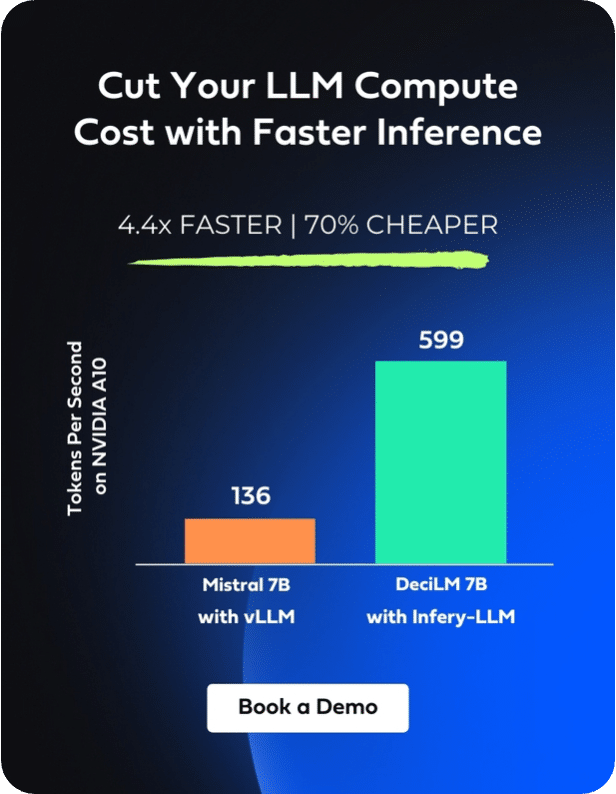
Deci’s Infery-LLM offers a robust solution to these challenges. This Inference SDK significantly enhances LLM performance, achieving up to fivefold throughput increases while maintaining accuracy. Crucially, it optimizes the use of computational resources, enabling the deployment of larger models on more economical GPUs and thus reducing overall operational costs.
When combined with Deci’s open-source models like DeciCoder or DeciLM 6B, Infery-LLM’s efficiency is further amplified. These models, optimized for performance, pair seamlessly with the SDK, enhancing its ability to minimize latency and reduce costs.
Below is a chart that demonstrates the throughput acceleration on NVIDIA A10 GPUs using DeciLM 6B with Infery-LLM, compared to the standard performance of both DeciLM 6B and Llama 2, as well as Llama 2 utilized with vLLM, an open-source library for LLM inference and serving. The comparison highlights the effectiveness of Infery-LLM in facilitating the transition from the high-performance but expensive NVIDIA A100 GPUs to the more cost-effective A10s. This shift is achieved without compromising throughput or quality, even on the less resource-intensive hardware.

In summary, Infery-LLM is vital for addressing the challenges of latency, throughput, and cost in LLM deployment, proving indispensable for developers and organizations leveraging these sophisticated AI models.
Discover the power of Infery-LLM for yourself; click below for a live demo and witness its groundbreaking impact.