Getting your deep learning model ready for deployment is only the beginning. Once you optimized it, found the suitable hardware, and achieved the results that you want, the next step is to assess and improve the inference pipeline in production.
In this post, we will go through the different components of the inference pipeline and ways to optimize each. To measure success, we enumerate the various metrics that you can use to monitor hardware utilization.
What is the Inference Pipeline in Production?
Unlike in the research phase where there is no pipeline (only forward-pass), inference behaves and acts differently in the production environment. Figure 1 provides an overview of the key components to consider beyond your optimized model. It is a two-way process that involves the hardware, operating system, applications, users, and everything in between.
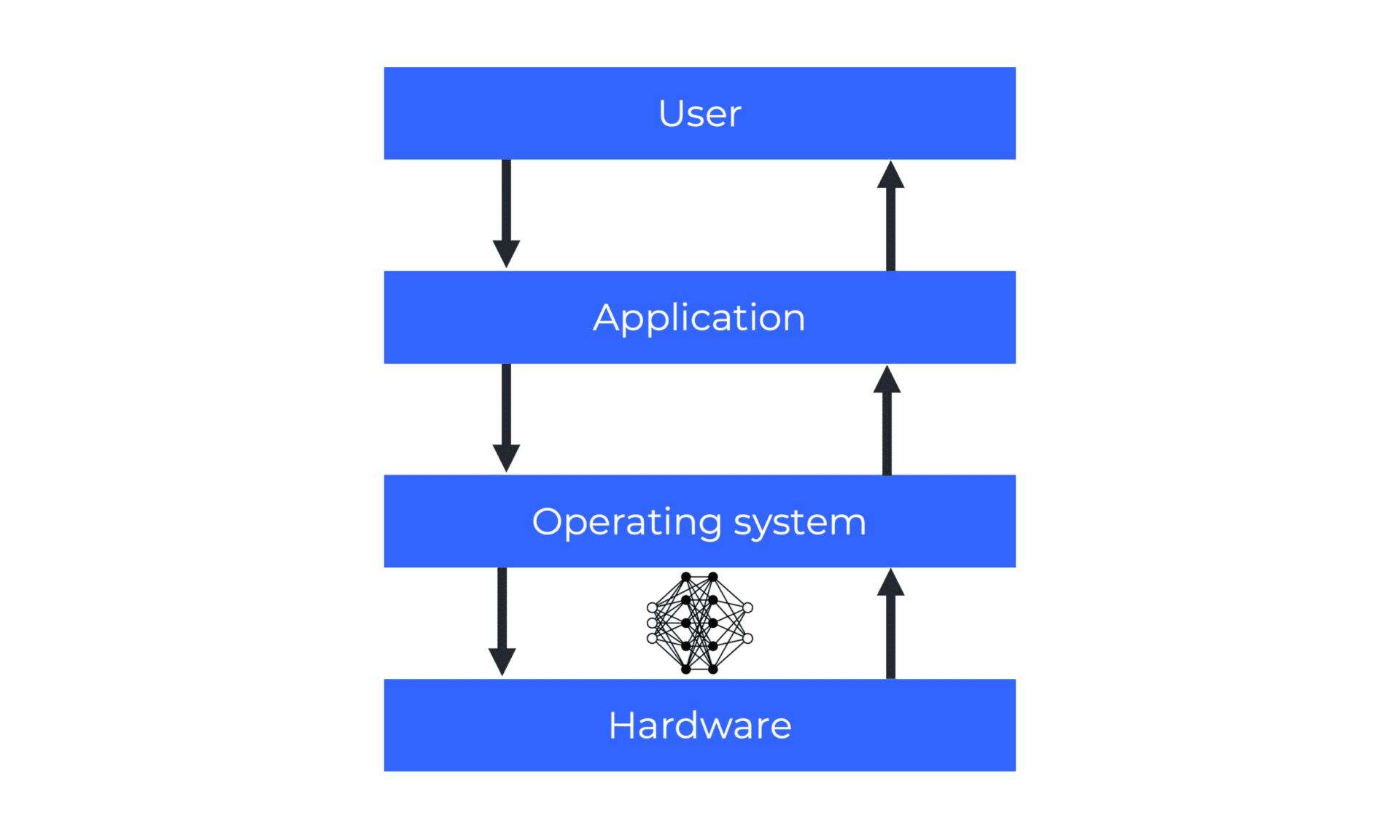
Figure 1. A Simple Illustration of the Inference Pipeline
Simply put, to achieve optimal performance, the entire pipeline needs to be fast—not only the model. The following tips for optimizing the inference pipeline in production were taken from our webinar, “How to Deploy Deep Learning Models to Production.” We encourage you to watch it to see demonstrations of the principles we will discuss.
1. Inference Server
The inference server executes your model algorithm and returns the inference output. It is the biggest part of the pipeline, so it must meet your expectations. When choosing your inference server, here is what you need to watch out for.
- Is it easy to deploy with a robust API? You don’t want to spend too much time on how to use it, what to do with it, or how to deploy it.
- Is it versatile and dynamic? You should have the ability to do whatever you want and need. For example, sometimes you might want to run multiple models on the same inference server or manage it using an API instead of constant configurations.
- Is it efficient? A low memory footprint is very important. You must be able to replicate more instances of the inference server over the same hardware.
When it comes to metrics, you should measure performance with and without the inference server, comparing your model behavior under the inference server and solely, by itself. Another thing to note is that latency will always be faster than end-to-end latency.
2. Client and Server Communication
The client and server denote a distributed but cooperative application structure that divides tasks between the providers of resource or service (servers), and the service requesters (clients). Tensor data must be shared and transferred in both ways between the client and server to fasten communication.
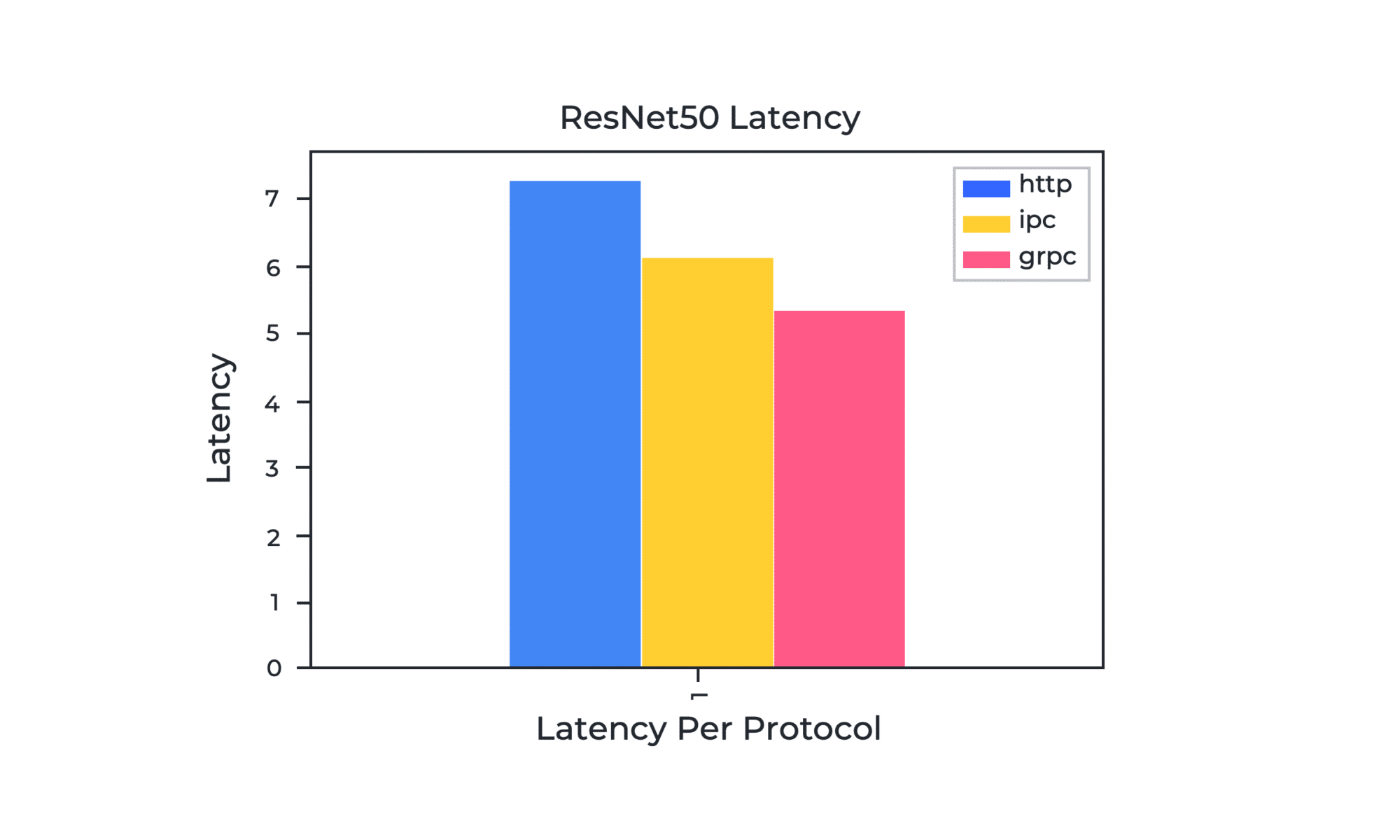
Graph 1. ResNet50 Latency Per Protocol
In Graph 1, you can see the end-to-end latency of ResNet50 using different communication protocols between the client and server. The end-to-end latency is a time pass between the second we call predict until the time we got a response back in memory available for use. We treat end-to-end latency when the server and client both finish their jobs, and the client has a response in memory to use.
Here is a quick explanation of each communication protocol.
- HTTP (network) is an application-layer protocol. It is simple and widely supported, but it doesn’t produce the best results.
- gRPC (network) is a newer protocol and is built on top of HTTP/2. It is a transport layer, so it leverages a protocol buffer message exchange. It supports request multiplexing over the same socket. In the graph, it is the fastest one for batch size 1.
- IPC (shared memory) is the solution we propose whenever the inference is done locally. When the client and server run on the same cluster or the same machine, they use /dev/shm to transfer the tensor data from one place to another. It is possible to share the tensors using inter-process communication so your model can communicate over shared memory which is faster—instead of over the network. It also requires less CPU operations.
Going back to the graph, gRPC has the lowest latency and is the fastest among the three. It should be a great choice if you use frame-by-frame processing. But eventually, it will depend on the batch size. You must try your model on different batch sizes to see which one behaves best for your use case.
3. Batch Size
Batch size is the number of samples on which the models makes predictions in one forward pass. Optimizing it is a low-hanging fruit when you want to boost inference performance in production.
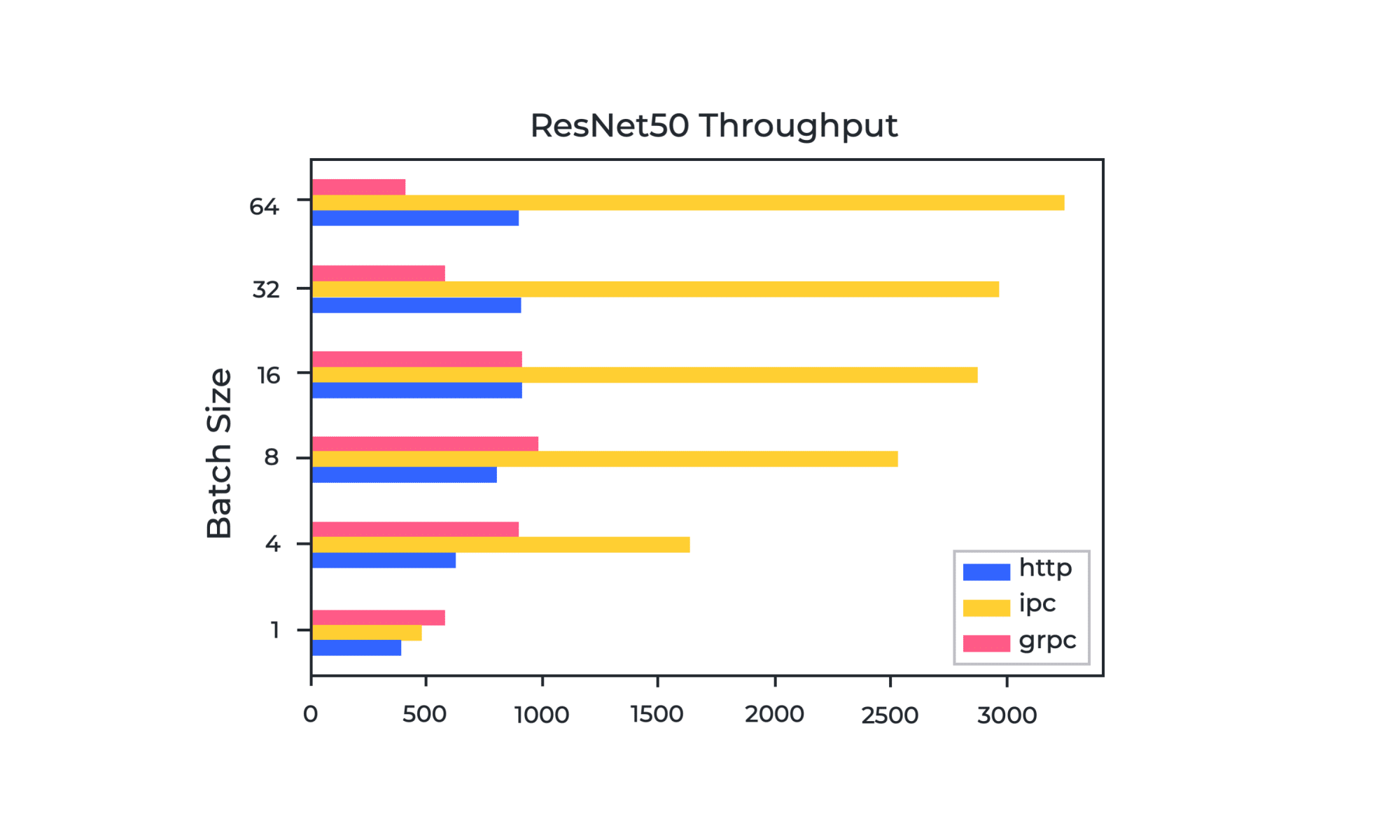
Graph 2. ResNet50 Throughput per Batch Size and Communication Protocol
Graph 2 demonstrates the throughput of ResNet50 for different communication protocols and batch sizes. HTTP reaches a bottleneck at batch size 16 while gRPC reaches it at batch size 8. Meanwhile, for shared memory (IPC), the throughput grows as the batch size grows but it reaches a plateau at some point because the operating system blocks it. What are the factors that affect batch size?
- Model task. In transport, the input and output shapes are critical. For example, classification models have input shapes that are different from detection models or NLP models.
- Model memory consumption and possible replication. When you reduce the model’s memory size, you can run the model more times and increase the number of instances for inference. This will then help you do parallel concurrent serving inside the server.
The general approach is to keep in mind what matters to you and your use case. If it is an edge client, you are bound by a network transport like HTTP or gRPC. If it is a batch processing queue, it consumes like a queue and infers on the same machine, on the same hardware. In this scenario, inter-process communication can increase the throughput of your model instead of using HTTP or gRPC at the localhost because both are inefficient.
4. Code Optimization
Code is something that you can change in the fastest way, and one method to do that is to utilize asynchronous code. To understand it, here is its definition in comparison to synchronous code.
- Synchronous code performs tasks one at a time. Python is the default that we always see in the examples. You send a request, you get a response, and continue with your logic whether it is pre-processing or post-processing. Synchronous code is a great thing to try and copy but when it comes to production code, you should use another method.
- Asynchronous code performs multiple tasks simultaneously and completes more tasks faster. It means that when you run the predict function, you get a future object, an object that you can use later to get the server response once you want it. You can fire 100 requests, request all of them or the ones that are done among them, at a certain point. This keeps the GPU volatility and benchmarks high.
5. Serialization
Serialization translates state information of a data or object instance into a format that can be stored, transported over a network, and reconstructed later. The process affects latency because it manipulates the data, and it is a CPU blocking operation. It can be done in various ways. The default option, Stack Overflow, is not necessarily the fastest.
When you watch our webinar, you will see not only how we compare three serialization methods with different batch sizes: NumPy native serialization, Apache PyArrow which is a Flatbuffer, and Protobuf which is used within gRPC. But also, significant improvements to an optimized model using all the above inference pipeline components.
How Do You Ensure that Hardware Usage is Maximized?
Now that you have several principles to test on your model and production environment, it is crucial to know the metrics to track inference and to assess performance. Figure 2 highlights the essential hardware metrics that you should be aware of when evaluating the utilization of your hardware.
- Watt usage. It shows us the power consumption, which is a great metric to watch GPU usage live.
- Memory usage. You want to keep it as high as possible and use all of it for inference. GPU is a very expensive resource, and you want to utilize it to the top. You also might use pinned memory GPU inference. It is much faster and more efficient when you do it inside the pipeline. It also uses less memory when you optimize your model.
- Volatility. During peak performance, it should be very high but with caveats. In production, consistency at about 80% or 90% is ideal. This means the hardware is used to the limit. It shouldn’t be on 100% all the time. Instead, it should bounce between 90% above—and not with a big variance. Spikes in volatility can indicate bottlenecks. Jumping from 40% to 80%, for example, means that the GPU is not maximized to the max.

Figure 2. Hardware Metrics
The key is to strike high utilization among these metrics. To maximize your resources, you must use all available GPUs and keep the hardware busy.
Conclusion
From the inference server that you use to the tweaking of the client and server protocol, batch size, code, and serialization, the main takeaway here is that engineering efforts can mitigate hardware constraints. Every technical aspect of your pipeline can be improved. And at the end of the day, there is always a unique combination that works best for your use case.
Don’t forget to check out Deci’s inference tools when you try the tips for your deep learning project. You can run inference locally with Infery, a Python runtime engine, when you compare inference times of models (also good for edge devices with limited resources). Then, you can use RTiC, a runtime inference container, when you are ready to deploy and make predictions in the production environment.