2023 has not just been a year of technological strides in open large language models (LLMs), it’s been a year of redefining them.
In August, I shared my thoughts on the top 10 LLMs, but the subsequent months have highlighted a significant shift in the landscape. One particularly striking trend is the emergence and impressive performance of smaller LLMs. Contrary to their unassuming size, these models have punched above their weight in performance, challenging our understanding of efficiency and capability in AI.
This post, initially intended to focus on the major LLM releases in the latter half of 2023, will instead concentrate on these smaller yet robust LLMs.
I will explore them in categories based on their parameter sizes, specifically those with 13 billion parameters or less, grouped by parameter size categories – 1 billion, 3 billion, 7 billion, and 13 billion. For each, I’ll provide a thorough introduction, details on their training data, current popularity metrics like likes and downloads, and a discussion on their unique contributions and use cases.
This exploration aims to highlight how these smaller LLMs are reshaping the AI landscape, offering impressive capabilities despite their reduced scale.
1 Billion Parameter LLMs
DeciCoder-1B
Downloads Last Month (Nov 2023): 202,166
Likes: 229
📝 Brief Introduction
The DeciCoder-1B is a 1 billion parameter model, designed for code completion.
It’s an auto-regressive language model based on the transformer decoder architecture, using Grouped Query Attention. The model has a specific focus on the Python, Java, and JavaScript programming languages.
📚 Training Data
DeciCoder 1B was trained on the Starcoder Training Dataset, an extensive collection featuring 783GB of code across 86 programming languages.
This dataset is notable for its diversity, including 54GB of GitHub Issues, 13GB of Jupyter notebooks in scripts and text-code pairs, and 32GB of GitHub commits, totaling approximately 250 billion tokens.
The richness and variety of this dataset contribute significantly to the model’s robust performance in code generation and completion tasks.
🔧 Architecture
The model boasts a context window of 2048 tokens and was discovered using Deci’s AutoNAC engine(Neural Architecture Search-based technology). It has 20 layers, 32 heads, and a hidden size of 2048, optimized for handling complex coding tasks efficiently.
🏋🏼♀️ Training Details
- Warm-Up Steps: 9,000
- Total Training Steps: 284,000
- Total Tokens: 446 Billion
- Global Batch Size: 768
- Optimizer: AdamW (beta1=0.9, beta2=0.95)
- Weight Decay: 0.1
- Learning Rate: 4e-4
- Learning Rate Schedule: Cosine
🏆 Performance and Usage
DeciCoder 1B excels in single/multiline code completion, specifically in the Python, Java, and JavaScript contexts. It’s important to note that it’s not an instruction-based model, and thus, it performs best when prompts are framed in the style of source code comments.
✨ Highlights
- Licence: Apache 2.0
- Evaluation: Impressive pass@1 scores on the MultiPL-HumanEval dataset for Python (0.191), JavaScript (0.184), and Java (0.166).
- Accessibility: Available on Hugging Face, making it easy for developers to integrate into their projects.
Phi-1.5
Downloads Last Month (November 2023): 152,917
Likes: 1174
📝 Brief Introduction
Phi-1.5 is a 1.3 billion parameter language model that was developed by Microsoft.
Unlike its predecessor, phi-1, this model includes additional data sources for NLP synthetic texts. Designed not for instruction following or reinforcement learning from human feedback,
Phi-1.5 targets research in safety challenges like reducing toxicity and understanding biases.
📚 Training Data
Phi-1.5’s training involved a diverse array of data sources, enhancing its ability to handle various NLP tasks. Key sources include subsets of Python codes from The Stack v1.2, Q&A content from StackOverflow, competition code from code_contests, and synthetic Python textbooks and exercises generated by gpt-3.5-turbo-0301. This training approach helps the model in generating a wide range of texts, from technical to creative.
🏋🏾 Training Details
- Architecture: Transformer-based with next-word prediction objective
- Dataset Size: 30B tokens
- Training Tokens: 150B tokens
- Precision: fp16
- GPUs: 32xA100-40G
- Training Time: 8 days
🔧 Architecture
The model’s architecture, rooted in the Transformer framework, is designed to handle a wide range of NLP tasks with efficacy and precision.
🏆 Performance and Usage
Phi-1.5 is adept in QA, chat, and code formats.
However, as a base model, it may produce some irrelevant text after the main answer. It demonstrates near state-of-the-art performance among models with less than 10 billion parameters in common sense, language understanding, and logical reasoning.
✨ Highlights
- License: Research License
- Evaluation: Strong performance in benchmarks for common sense and logical reasoning.
- Paper: Textbooks Are All You Need II
👩👩👧👧 Other members of the Phi family
3 Billion Parameter LLMs
Dolly-v2-3b
Downloads Last Month (November 2023): 98,913
Likes: 251
📝Brief Introduction
Dolly v2-3b, a creation of Databricks, is a significant entry in the smaller LLM space with 2.8 billion parameters.
This model, which is based on EleutherAI’s Pythia-2.8b, is an instruction-following language model trained for commercial use. It’s fine-tuned on about 15k instruction/response records generated by Databricks employees, covering a range of capability domains like brainstorming, classification, QA, and summarization.
📚 Training Data
Dolly v2-3b’s training leveraged the databricks-dolly-15k dataset, which includes a variety of instruction/response records.
This model, while not state-of-the-art, demonstrates high-quality instruction-following behavior, a trait not characteristic of its foundational model, Pythia-2.8b.
🏋🏼♀️ Training Details
- Base Model: EleutherAI’s Pythia-2.8b
- Fine-Tuning Dataset: ~15K records from
databricks-dolly-15k - Domains Covered: Brainstorming, classification, closed QA, generation, information extraction, open QA, summarization
🔧 Architecture
Dolly v2-3b is built on a causal language model framework, inheriting the robust architecture of its base model, Pythia-2.8b. This setup facilitates effective instruction following and response generation across various domains.
🏆 Performance and Usage
While not at the forefront in terms of state-of-the-art performance, Dolly v2-3b excels in instruction-following tasks. It is adept in generating responses for a wide range of prompts, including technical and creative requests.
✨ Highlights
- License: MIT
- Diverse Applications: Capable of handling tasks from brainstorming to summarization.
- Commercial Use: Licensed for commercial applications, expanding its utility beyond research.
👩👩👧👧 Other members of the Dolly family
StableLM-Zephyr-3B
Downloads Last Month (November 2023): 11,526
Likes: 142
📝 Brief Introduction
StableLM Zephyr 3B is a notable 3 billion parameter instruction-tuned model.
Inspired by HuggingFaceH4’s Zephyr 7B training pipeline, this model was trained on a mix of publicly available datasets and synthetic datasets using Direct Preference Optimization (DPO). It is designed to provide high-quality performance in a variety of NLP tasks, including chat and instruction following.
📚 Training Data
The training of StableLM Zephyr 3B involved datasets like HuggingFaceH4/ultrachat_200k, WizardLM/WizardLM_evol_instruct_V2_196k, and others, offering a diverse range of instruction formats and responses.
The model’s performance is benchmarked using MT Bench and the Alpaca Benchmark.
🏋🏾 Training Details
- Base Model: Inspired by HuggingFaceH4’s Zephyr 7B
- Datasets: Includes HuggingFaceH4/ultrachat_200k, WizardLM/WizardLM_evol_instruct_V2_196k, and more
- Approach: Direct Preference Optimization (DPO)
🔧 Architecture
StableLM Zephyr 3B, with its causal language model framework, is adept at handling a wide range of instruction-following tasks.
The model’s design enables effective communication and generation of responses in various NLP applications.
🏆 Performance and Usage
StableLM Zephyr 3B excels in generating high-quality responses for instruction-following and chat-based interactions.
It’s evaluated to perform well in common sense, language understanding, and logical reasoning tasks.
Highlights ✨
- Recommended Use: Ideal as a foundational base model for application-specific fine-tuning.
- Limitations and Bias: Not trained against adversarial inputs; recommended to pair with input and output classifiers.
- Safety Measures: Developers should evaluate and fine-tune the model for safe performance in their specific applications.
👩👩👧👧 Other members of the StableLM family
7 Billion Parameter LLMs
DeciLM-7B
Downloads Last Month (November 2023): 2,107
Likes: 167
📝 Brief Introduction
DeciLM-7B is a high-efficiency, 7.04 billion parameter text generation model.
This decoder-only model stands out as one of the top-performing 7B base language models on the Open LLM Leaderboard. Its efficiency is further highlighted by its support for an 8K-token sequence length, making it a formidable tool in the realm of large language models.
📚 Training Data
While specific details about the training data and procedure aren’t provided (it’s mostly permissively-licensed open source data along with our own proprietary datasets.), DeciLM-7B’s superior performance implies a comprehensive and diverse training regimen.
The use of variable Grouped-Query Attention (GQA) suggests an emphasis on balancing accuracy with computational efficiency.
🏋🏼♀️ Training Details
- Model Type: Auto-regressive language model
- Architecture: Optimized transformer decoder with variable Grouped-Query Attention
- Sequence Length Support: Up to 8192 tokens
- Optimization: Utilizes Deci’s proprietary Neural Architecture Search technology, AutoNAC
🔧 Architecture
DeciLM-7B is designed with an optimized transformer decoder architecture that includes variable Grouped-Query Attention.
This architecture, generated using Deci’s AutoNAC technology, contributes to its high performance and efficiency.
🏆 Performance and Usage
As a highly efficient language model, 7B base model, DeciLM-7B showcases exceptional capabilities in text generation.
Its performance is further enhanced by a throughput that makes it suitable for a wide range of NLP tasks.
✨ Highlights
- License: Apache 2.0
- Efficiency: Notable for its high throughput, up to 4.4x that of similar models
- Capability: Supports a large token sequence length, ideal for complex text generation tasks
👩👩👧👧 Other members of the DeciLM family
Mistral-7B-Instruct-v0.2
Downloads Last Month (November 2023): 46,831
Likes: 436
📝 Brief Introduction
Mistral-7B-Instruct-v0.2, an enhanced version of the previous Mistral-7B-Instruct-v0.1, is a prominent 7 billion parameter LLM fine-tuned for instruction following. This model demonstrates compelling performance in various NLP tasks, standing out for its ability to accurately interpret and respond to instructions.
📚 Training Data
The model is an improved fine-tuned version of its predecessor, likely involving additional training on diverse datasets to enhance its instruction-following capabilities.
For specific training details, please refer to the model’s paper and release blog post.
🏋🏾 Training Details
- Base Model: Mistral-7B-Instruct-v0.1
- Fine-Tuning: Focus on instruction following
- Paper and Blog Post: For in-depth details and insights
🔧 Architecture
Mistral-7B-Instruct-v0.2’s architecture is designed for efficient instruction interpretation and response generation, building upon the robust framework of its predecessor. This architecture enables the model to excel in a wide range of NLP tasks.
🏆 Performance and Usage
The model is particularly adept at understanding and following instructions, making it suitable for applications requiring precise interpretation of user prompts. It’s recognized for its improved performance compared to the earlier version.
✨ Highlights
- License: Apache 2.0
- Upgraded Version: Fine-tuned for enhanced instruction following
- Flexibility: Effective in various NLP tasks, including chat and QA formats
👩👩👧👧 Other members of the Mistral family
Orca-2-7B
Downloads Last Month (November 2023): 18,651
Likes: 176
📝 Brief Introduction
Orca 2 is a distinctively designed model, built primarily for research purposes.
It specializes in providing single-turn responses in tasks like reasoning over user-provided data, reading comprehension, math problem-solving, and text summarization. Orca 2 shines in its ability to perform reasoning tasks, setting it apart as a unique tool in the realm of language models.
📚 Training Data
Orca 2 is a fine-tuned version of the LLAMA-2 base model.
Its training involved a synthetic dataset created specifically to enhance the model’s reasoning abilities. This synthetic data was moderated using Microsoft Azure content filters to ensure quality and safety.
🏋🏼♀️ Training Details
- Base Model: LLAMA-2
- Specialization: Reasoning tasks
- Data Moderation: Microsoft Azure content filters
🔧 Architecture
Orca 2, based on the LLAMA-2 architecture, is optimized for tasks that require high levels of reasoning and comprehension. This architecture enables the model to effectively handle complex queries and provide accurate responses.
🏆 Performance and Usage
Designed for reasoning, Orca 2 excels in tasks that require logical thinking and comprehension. It’s a research model, aimed at demonstrating the potential of models and complex workflows in creating synthetic data that can teach Small Language Models (SLMs) new capabilities.
✨ Highlights
- License: Microsoft Research License
- Research Focus: Enhancing reasoning capabilities in SLMs
- Paper: For detailed evaluations, refer to the Orca 2 paper.
👩👩👧👧 Other members of the Orca family
Amber
Downloads Last Month (November 2023): 445
Likes: 45
Brief Introduction 📝
Amber, part of the LLM360 family, is a 7B parameter English language model built on the LLaMA architecture.
This model exemplifies the commitment to fully open-sourced LLMs, offering transparency in training, model checkpoints, and analyses.
📚 Training Data and Procedure
Amber’s training involved comprehensive datasets and methodologies as part of the LLM360 initiative, designed to advance the field through open-source efforts. The initiative provides detailed insights into the model’s development, including intermediate model checkpoints, pre-training datasets, source code, and configurations.
🏋🏾 Training Details
- Model Type: Language model with LLaMA-7B architecture
- Language: English
- Resources:
🔧 Architecture
Built with the LLaMA-7B architecture, Amber is designed for efficiency and effectiveness in English language processing. This structure allows for versatile applications and robust performance in various NLP tasks.
🏆 Performance and Usage
As an open-source model, Amber is not only a valuable tool for research but also for practical applications in English language processing. Its design and structure make it suitable for a wide range of NLP tasks.
✨ Highlights
- License: Apache 2.0
- Open-Source Initiative: Part of LLM360, promoting comprehensive and transparent LLM research.
- Community Engagement: Invites community participation in understanding and advancing LLMs.
👩👩👧👧 Other members of the Amber family
OpenHathi-7B-Hi-v0.1-Base
Downloads Last Month (November 2023): 1,180
Likes: 33
📝 Brief Introduction
OpenHathi is a breakthrough in bilingual large language models.
This 7 billion parameter model, based on the Llama2 architecture, is trained on Hindi, English, and Hinglish. OpenHathi stands out as the first in a series of models that aims to address the need for Indic language support in open models.
📚 Training Data
While specific training details are not provided, OpenHathi’s focus on Hindi, English, and Hinglish suggests a comprehensive and diverse training regimen, catering to both local and global linguistic nuances. The model’s development aims to democratize access to language technology by enabling local execution and customization for specific requirements.
Training Details:
- Model Type: Based on Llama2 architecture
- Languages: Hindi, English, Hinglish
- Focus: Bilingual language processing and support for Indic languages
🔧 Architecture
OpenHathi’s architecture, derived from Llama2, is specifically optimized for bilingual language processing. This design allows the model to handle a blend of Hindi, English, and Hinglish effectively, making it a versatile tool for various linguistic tasks.
🏆 Performance and Usage
Designed to bridge the gap in Indic language support in open models, OpenHathi is not only a valuable resource for research but also for practical applications in bilingual language processing. Its unique focus on Hindi, English, and Hinglish makes it suitable for a wide range of NLP tasks in these languages.
✨ Highlights
- First in OpenHathi Series: Pioneering bilingual LLM support in open models
- Innovative Language Support: Focused on Hindi, English, and Hinglish
- Democratizing Language Technology: Enabling local execution and specialized applications
13 Billion Parameter LLMs
SOLAR-10.7B-v1.0
Downloads Last Month (November 2023): 2,027
Likes: 77
📝Brief Introduction
SOLAR-10.7B, although not reaching a full 13 billion parameters,is a huge advancement in open LLMs, with its 10.7 billion parameters.
This model demonstrates exceptional performance, particularly in tasks requiring state-of-the-art capabilities for models with parameters under 30B. Built on the Llama2 architecture, SOLAR-10.7B incorporates the innovative Upstage Depth Up-Scaling technique, offering a compact yet powerful solution.
This model demonstrates exceptional performance, especially in tasks requiring state-of-the-art capabilities for models with parameters under 30B. SOLAR-10.7B, built on the Llama2 architecture, incorporates the novel Upstage Depth Up-Scaling technique, offering a compact yet powerful solution.
📚 Training Data
SOLAR-10.7B’s training involved the integration of Mistral 7B weights into its upscaled layers, followed by continued pre-training.
This innovative approach, combined with Depth Up-Scaling, allows the model to outperform even larger models.
🏋🏾 Training Details
- Base Model: Llama2 architecture
- Special Techniques: Upstage Depth Up-Scaling, integration of Mistral 7B weights
- Performance: Outperforms models up to 30B parameters
🔧 Architecture
SOLAR-10.7B’s architecture is designed to maximize performance within a compact framework.
The use of Depth Up-Scaling and integrated weights from the Mistral 7B model contribute to its robustness and efficiency in various NLP tasks.
🏆 Performance and Usage
The model is ideal for fine-tuning and demonstrates remarkable adaptability for a range of applications.
Its state-of-the-art performance under 30B parameters makes it a top choice for tasks requiring advanced language understanding and generation.
✨ Highlights
- License: Apache 2.0
- Innovation: Depth Up-Scaling technique for enhanced performance
- Versatility: Suitable for fine-tuning across various applications
NexusRaven-V2-13B
Downloads Last Month (November 2023): 3,232
Likes: 251
📝 Brief Introduction
NexusRaven-V2-13B, an open-source and commercially viable function calling LLM, surpasses the state-of-the-art in function calling capabilities, including GPT-4.
It is capable of generating single function calls, nested calls, and parallel calls in many challenging cases and provides detailed explanations for the function calls it generates.
📚 Training Data and Procedure
While specific training details are not provided in the excerpt, NexusRaven-V2-13B’s performance highlights its advanced capabilities in function calling, surpassing even GPT-4. It is noted that the training of NexusRaven-V2 did not involve any data generated by proprietary LLMs such as GPT-4, ensuring commercial permissiveness.
🏋🏾 Training Details
- Focus: Advanced function calling capabilities
- Commercially Permissive: Trained without proprietary LLM data
🔧 Architecture and Capabilities
NexusRaven-V2-13B is designed to be fully explainable and versatile in function calling. It demonstrates generalization to unseen functions and surpasses GPT-4 by 7% in function calling success rates.
🏆 Performance and Usage
This model is a top choice for applications involving complex function calling tasks. Its ability to generate detailed explanations for function calls makes it particularly useful for applications requiring clarity and insight into the model’s processes.
✨ Highlights
- License: Nexusflow community license
- Innovation: Surpasses state-of-the-art models in function calling
- Versatility: Suitable for generating single, nested, and parallel function calls
Conclusion 🚀
The year 2023 has undoubtedly been a remarkable one for open large language models (LLMs). In just a matter of months, we’ve witnessed a Cambrian explosion of LLMs that have pushed the boundaries of what’s possible in natural language understanding and generation.
While the focus was initially on the larger LLMs with billions of parameters, a distinct trend has emerged—the rise of smaller LLMs. These more compact models, often with 13 billion parameters or less, have demonstrated astonishing performance, proving that size isn’t the only factor that matters in the world of language models.
In this blog post, we’ve delved into this exciting trend by exploring a curated selection of smaller LLMs released in 2023. These models, ranging from 1 billion to 13 billion parameters, have shown us that they can rival their larger counterparts in various tasks, all while being more resource-efficient.
From DeciCoder’s innovative approach to code generation to the language versatility of OpenHathi and the advanced function calling capabilities of NexusRaven-V2-13B, each model has brought something unique to the table.
We’ve not only highlighted their features and capabilities but also provided a glimpse of their real-world applications through example generations. These hands-on experiences have shown us the incredible potential these smaller LLMs hold for research, industry, and society as a whole.
As we conclude this journey through the world of smaller LLMs, it’s essential to recognize that the LLM landscape is evolving rapidly. Chances are, there are more hidden gems out there, waiting to be discovered. The field of natural language processing continues to expand, innovate, and democratize access to language technology.
The era of smaller LLMs is here, and it’s reshaping how we interact with language models. Whether you’re a developer, researcher, or enthusiast, these models offer exciting opportunities to explore the power of language in more accessible and efficient ways.
So, as we bid farewell to 2023, let’s look forward to what the future holds for open LLMs. Who knows what groundbreaking models will emerge next, ready to redefine the boundaries of language understanding and generation?
Stay tuned, stay curious, and let’s continue to unlock the potential of language together.
Next Phase: Achieving Lightning-Fast Inference
In this blog post, we’ve delved into the realm of small LLMs. These models offer a significant advantage with their rapid inference speed compared to their larger counterparts. For developers constructing applications around LLMs, fast inference isn’t just desirable—it’s indispensable for enhancing user experiences and managing operational costs.
However, size isn’t the sole determinant. Computational efficiency and meticulous inference optimization are equally critical factors to consider.
LLMs – even those under 13B – demand intricate computational processes, which can lead to significant latency issues, negatively impacting user experiences, especially in applications that require real-time responses. A major hurdle is the low throughput, which causes delayed responses and hinders the handling of concurrent user requests. This situation typically necessitates the use of costlier, high-performance hardware to improve throughput, thereby elevating operational expenses. Consequently, the need for such advanced hardware compounds the already substantial computational costs associated with implementing these models.
Infery-LLM by Deci presents an effective solution to these problems. This Inference SDK significantly improves LLM performance, offering up to a five-times increase in speed without compromising on accuracy, leading to reduced latency and quicker, more efficient outputs. Importantly, it makes better use of computational resources, allowing for the use of larger models on more cost-effective GPUs, thereby lowering the total operational costs.
When combined with Deci’s open-source models, such as DeciCoder or DeciLM-7B, the efficiency of Infery-LLM is notably increased. These highly accurate and efficient models integrate smoothly with the SDK, boosting its effectiveness in reducing latency and cutting down costs.
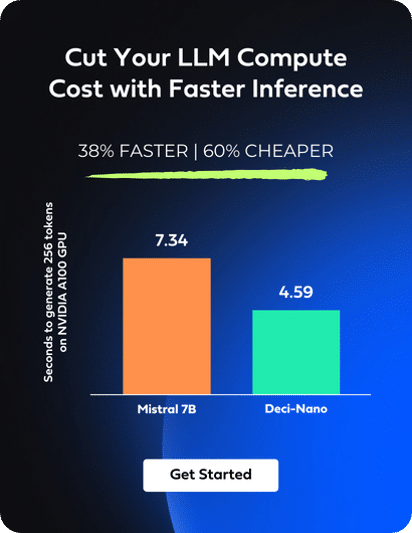
Enabling inference with just three lines of code, Infery-LLM makes it easy to deploy into production and into any environment. Its optimizations unlock the true potential of LLMs, as exemplified when it runs DeciLM-7B, achieving 4.4x the speed of Mistral 7B with vLLM with a 64% reduction in inference costs.

Infery’s approach to optimizing LLMs enables significant performance improvements on less powerful hardware, as compared to other approaches on vLLM or PyTorch even on high-end GPUs, significantly reducing the overall cost of ownership and operation. This shift not only makes LLMs more accessible to a broader range of users but also opens up new possibilities for applications with resource constraints.

In conclusion, Infery-LLM is essential for overcoming the challenges of latency, throughput, and cost in deploying LLMs, becoming an invaluable asset for developers and organizations utilizing these advanced models. To experience the full capabilities of Infery-LLM, we invite you to get started today.