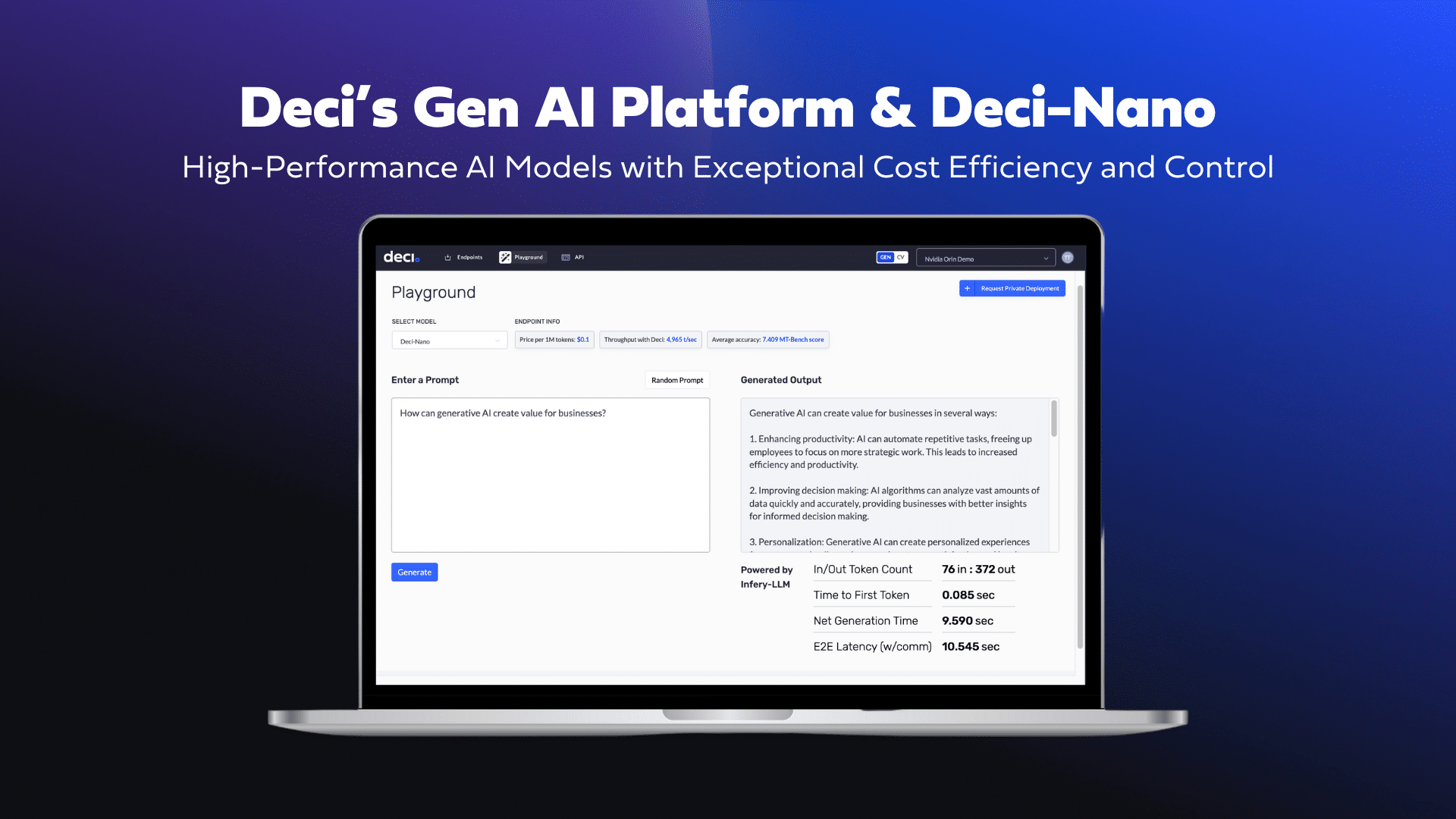
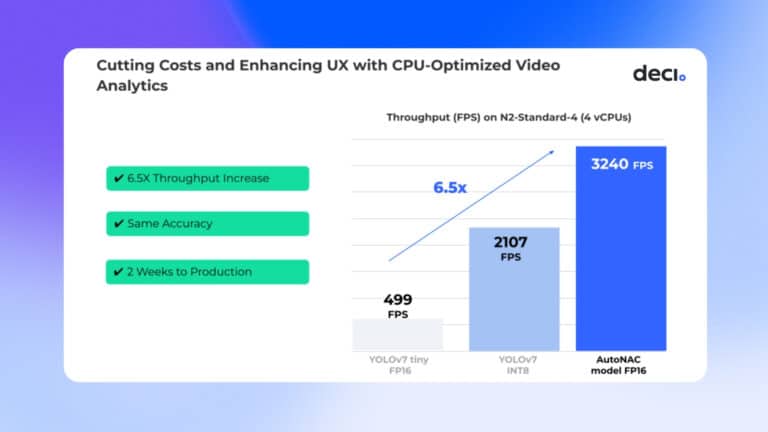
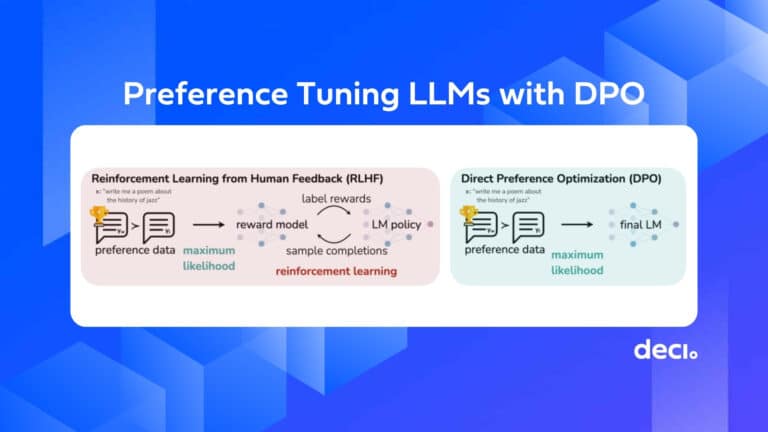
from transformers import AutoFeatureExtractor, AutoModelForImageClassification extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50") model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")