Defining Class Frequency
Class Frequency refers to the frequency of instances of each class in the dataset.
Class Frequency measures the count of instances for each class in the dataset. With this measure, we can gain an accurate understanding of how classes are distributed across the dataset.
The importance of Class Frequency
Class frequency plays a critical role in determining your model’s effectiveness.
The main reason is balance. If a class rarely shows up in the training set but often in the validation set, your model is set up for a fall—it hasn’t been given enough examples to learn from.
This information leads us to strategic decisions. If we spot class imbalances, we might need to adjust our data collection or implement specific augmentation strategies. These might include collecting more samples of underrepresented classes or applying data augmentation techniques like cropping, flipping, or rotation.
In response to class imbalances, we could also modify our model’s training strategy. This could involve changing the loss function to penalize incorrect predictions of underrepresented classes more heavily. So, a thorough understanding of class frequency can directly inform and shape our data augmentation and model training strategies.
Calculating Class Frequency
To calculate the class frequency, iterate over all the samples in the dataset.
For each sample, count how many times each class appears. Then, group the data by class and split (training or validation), and count the number of entries for each group. This gives the number of appearances of each class in each split.
To get the frequency, divide the number of appearances by the total number of appearances in the split, and multiply by 100 to get a percentage.
Here’s how Class Frequency is calculated in DataGradients.
Exploring Class Frequency Through Examples
Let’s consider two examples to better understand the potential issues associated with Class Frequency.
Example 1: Underrepresented Class
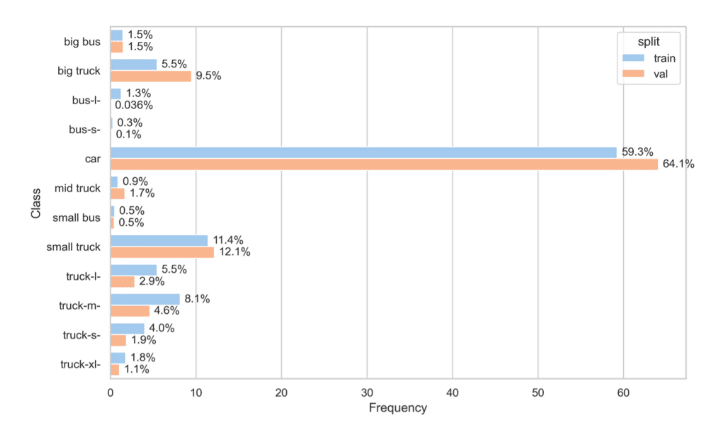
In this example, the training and validation sets have relatively close class frequencies. There is one major exception, bus -l- which appears around 40x more in the training than in the validation set.
Despite class frequency being an important factor, in this instance, the difference between the train and validation set is not an issue. Seeing more frequently a specific class in the training set will simply allow the model to learn that class properly.
However, if the situation were the other way around, it would pose a potential issue. If the class bus-l appeared only 0.036% of the time in the training set, but 40 times more frequently in the validation set, the model would have very few examples to learn from. In that case, you may choose to tweak the loss function to penalize incorrect predictions of the class bus -l. We will delve more deeply into this strategy in the next lesson.
Example 2: Missing Class
Now consider an extreme example, where a certain class appears only in the validation set.
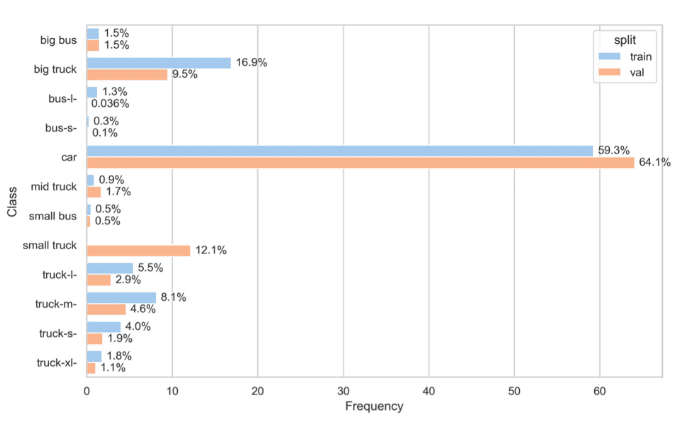
Here the small truck class appears only in the validation set, which means that the model won’t be able to learn that class at all.
If your dataset displays this sort of discrepancy in the occurrence of certain classes, there are a few strategies you can adopt.
First, review the transformations applied to your labels to ensure that no specific class has been inadvertently omitted or dropped.
If your transformations are accurate and the discrepancy persists, you have two primary options:
- Data Shuffling: Shuffle your dataset to ensure the missing class is represented in your training set as well, as explained in section 1.4. However, bear in mind this might not always be an appropriate solution. In instances where the validation set was specifically curated to represent a different distribution from the training set, merging the two datasets could lead to an inaccurate representation of the data.
- Ignoring the Missing Class: If you choose not to shuffle the datasets, it would be prudent to disregard the missing class during predictions. Without representation in the training set, the model lacks the necessary data to accurately predict the missing class.
