Semantic segmentation models aim to assign class labels to every pixel in an image, requiring the model to understand and capture both coarse and fine-grained spatial details. When designing a model for semantic segmentation tasks, two crucial aspects to consider are the convexity of objects and the presence of fine details. The convexity here refers to how much an object deviates from a convex shape, with high convexity meaning less deviation (more similar to a convex shape) and low convexity indicating higher deviation (more concave or complex shapes).
Let’s explore how these characteristics may impact our decision-making process.

Convex and Simple Objects: Utilizing Auxiliary Heads
If our dataset mainly consists of simple, convex objects, our model doesn’t need to retain high-resolution detail as much as it needs to understand the broader context. In these scenarios, the deeper layers of our model, where the receptive field is larger, and the spatial resolution is reduced, can adequately recognize and segment these objects.
To facilitate the learning of these deeper layers, we can employ auxiliary heads. These are additional output layers placed at intermediate points within the model, which make their own independent segmentation predictions during training.
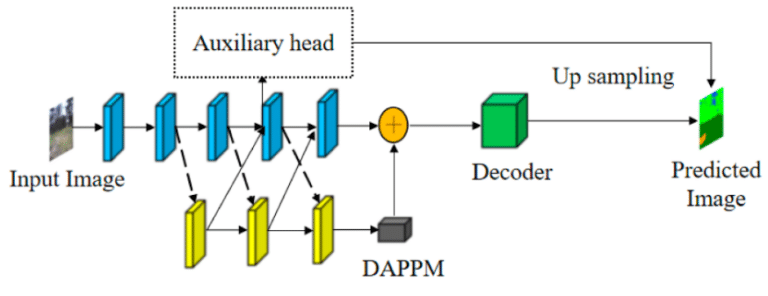
The importance of these auxiliary heads stems from their capacity to tackle the vanishing gradient problem, a common issue in very deep neural networks. They achieve this by injecting gradients directly into the deeper layers of the model during backpropagation. The result is a model that is better equipped to capture the overall features of simple, convex objects, even at deeper network layers.
However, it’s crucial to note that these auxiliary heads are only utilized during the training phase. After the model has been trained and is ready for inference, these auxiliary heads are typically discarded, and only the main model output is used. This approach ensures that the benefits of auxiliary heads are harnessed for model learning, while not affecting the complexity and computational cost during the inference stage.
Complex Shapes and Fine Details: Preserving High-Resolution Information
On the other hand, if our objects of interest have complex shapes or intricate details, our model design choices must change. In this scenario, it is crucial that our model retains high-resolution spatial information that can capture these fine details. Simple, large receptive fields often cannot provide the required precision.
One common strategy here is to use long skip connections. Skip connections allow information to bypass layers in the neural network, ensuring that high-resolution, detailed information from the initial layers is not lost as we move deeper into the network. Specifically, long skip connections enable the fine details from the early layers to be combined with the broader context information from deeper layers, facilitating the accurate segmentation of complex objects.
Another effective method is the use of dilated or atrous convolutions. These special types of convolutions, with adjustable sampling rates, can effectively increase the receptive field without losing resolution or coverage, making them well suited to tasks that require the preservation of fine details.
Final Thoughts
The design of a semantic segmentation model is not a one-size-fits-all task. The architectural choices should align with the characteristics of the objects in the dataset. Understanding the role of object convexity and the presence of fine details can guide the optimal use of auxiliary heads, skip connections, and different types of convolutions, ultimately leading to more effective and efficient models.
