
Two critical dataset factors that play a key role in the design of object detection models are the number of objects per image and the degree of overlap between these objects. In this lesson, we’ll explore how understanding these elements can greatly enhance your model’s performance. We’ll delve into Non-Maximum Suppression (NMS) and top-k filtering, and discuss how the object count and overlap can influence these techniques’ parameters.
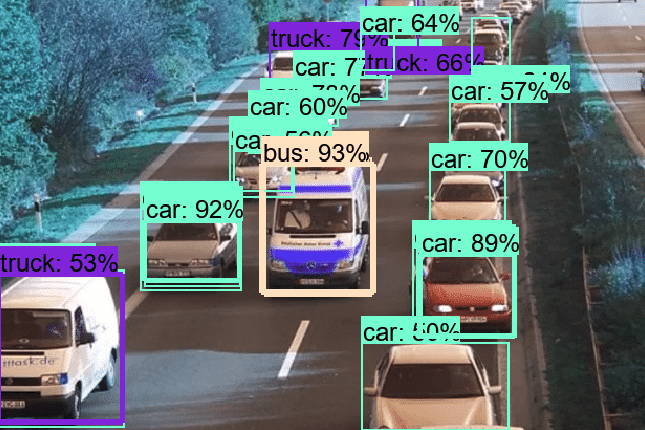
Non-Maximum Suppression and Object Overlap
Object detection models often comprise numerous detectors, each tasked with scanning a particular region of the image for potential objects. It is common for several detectors to recognize the same object, each drawing their interpretation of the object’s bounding box. This scenario poses a challenge: how can we ensure that each object is detected and outlined once?
The answer lies in a technique called Non-Maximum Suppression (NMS). Here’s how it works:
Sorting Prediction Boxes: All prediction boxes are sorted based on their scores. The score usually represents a confidence measure produced by the object detection model for each predicted bounding box.
Selection and Suppression: The prediction box with the highest score gets chosen as the “true” bounding box for that object. All other boxes with a substantial overlap (as determined by the Intersection over Union, or IoU, threshold) get suppressed or removed. This process is repeated until all prediction boxes have either been chosen or suppressed.
The degree of overlap between objects directly impacts the IoU threshold set for NMS. If your dataset primarily comprises images with highly overlapping objects, you might consider setting a higher IoU threshold to ensure distinct instances of objects are not suppressed by NMS. Conversely, a lower IoU threshold might be more suitable for images where objects do not overlap significantly.
Top-K Filtering and Object Count
Object count in an image is a significant factor when setting parameters for top-k filtering. This technique retains only the top ‘k’ detection boxes based on confidence scores. If your images generally contain a high number of objects, a larger ‘k’ might be more suitable to accommodate the many detections. However, if your images usually contain fewer objects, a smaller ‘k’ could be sufficient and more computationally efficient. Moreover, in some cases, we know there is at most one unique object and can, therefore, confidently set our k to 1.
Having a high ‘k’ value when your images seldom contain many objects could result in the model keeping many false positives. For instance, if you know your images seldom contain more than ten objects, setting ‘k’ to a significantly larger value than ten could lead to a high number of false positives.
In Conclusion
Understanding the specifics of your dataset, such as object count and overlap, can enable you to effectively tune the parameters of techniques like NMS and top-k filtering. This understanding can lead to improved model performance, making your object detection system more precise and efficient. Always remember, effective model design begins with a comprehensive understanding of your data.
